【2024年8月】衛星データ利活用に関する論文とニュースをピックアップ!【#MonthlySatDataNews】
2024年8月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
宙畑の新連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
本記事を制作するために、これは!と思った論文やニュースをTwitter上で「#MonthlySatDataNews」をつけて備忘録として宙畑編集部メンバーが投稿しています。宙畑読者のみなさまも是非ご参加いただけますと幸いです。
2024年8月の「#MonthlySatDataNews」を投稿いただいたのはこちらの方でした!
GLocal: A global development dataset of subnational administrative areas #MonthlySatDataNews
世界中のサブナショナルについてのデータセットでいろんなデータ含まれてる模様 https://t.co/0baZxUnrVQ— たなこう (@octobersky_031) August 17, 2024
それではさっそく2024年8月の論文を紹介します。
2024年8月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
・Deep learning for detecting and characterizing oil and gas well pads in satellite imagery(Sentinel-2衛星データとディープラーニングを用いた油井パッドと貯蔵タンクの高精度検出手法)
・Scalable interpolation of satellite altimetry data with probabilistic machine learning(衛星高度計データを用いた海氷と海面変動の効率的予測のためのGPSat手法)
・A satellite-derived baseline of photosynthetic life across Antarctica(Sentinel-2衛星データを活用した南極大陸全域の光合成生物分布の高解像度マッピング)
・A deep learning-based combination method of spatio-temporal prediction for regional mining surface subsidence(Sentinel-1衛星データ、K-meansクラスタリング、GRUモデルを組み合わせた地盤沈下の高精度予測手法)
・Semi-Automatic Detection of Ground Displacement from Multi-Temporal Sentinel-1 Synthetic Aperture Radar Interferometry Analysis and Density-Based Spatial Clustering of Applications with Noise in Xining City, China(Sentinel-1衛星のSBAS-InSARデータとDBSCANアルゴリズムを用いた広域の地滑り半自動検出手法)
・Complex-Valued 2D-3D Hybrid Convolutional Neural Network with Attention Mechanism for PolSAR Image Classification(複素数値2D-3DハイブリッドCNN+アテンション機構によるPolSAR画像分類手法)
それでは、一つずつ紹介していきましょう。
Deep learning for detecting and characterizing oil and gas well pads in satellite imagery
【どういう論文?】
・高解像度の衛星画像とディープラーニング技術を組み合わせることで、油井パッド(石油や天然ガスを採掘するための井戸)や貯蔵タンク施設の自動マッピングを行う
【技術や方法のポイントはどこ?】
◾️ネガティブ例の選定とデータセットの拡充
①目的
・モデルが油井パッド以外のオブジェクト(例:道路、風力タービン、湖床、川岸、露出した土壌、農地など)を誤検出してしまう問題に対応するため、これらの誤分類された景観のネガティブ例を収集することで、モデルの識別性能を向上させる
②内容
・初期のモデルによって誤分類された景観(例:道路、風力タービン、湖床、川岸、露出した土壌、農地など)を特定し、それらのネガティブ例を収集、OpenStreetMapからもデータを収集し、ネガティブ例を補強する
◾️モデルのトレーニング
・複数の物体検出モデル(Faster RCNN、RetinaNet、SSD、YOLOv3)とバックボーン(ResNet、EfficientNet)を比較検討する
◾️油井パッド検出の設計
①仮説課題
・単に油井パッドを検出するだけでは、似ているが異なるオブジェクト(例:道路、風力タービン、湖床、川岸、露出した土壌、農地など)を油井パッドと誤って検出する可能性が高い(偽陽性が残る可能性が高い)
②解決策
・検出された結果を再評価して、誤検出を排除するために検証モデルを追加する
・最初の段階では、一般的な物体検出モデル(例:RetinaNet)を使用し、衛星画像に写っている油井パッドの境界ボックスを検出する中で、リコール(Recall)を最大化させる
・検証段階では、より精密に油井パッドを識別するためのバイナリ分類器(例:EfficientNet-B3)を使用して、精度(Precision)を最大化させる
③補足
[RetinaNetとは]
・従来の物体検出モデル(例:Faster R-CNN)とは異なり、Focal Lossという損失関数を使用している
・Focal Lossは、難しい検出対象(すなわち、少数の重要なオブジェクト)に対してモデルが集中できるように調整されており、不均衡なデータセットに対しても有効である
・上記により、RetinaNetは画像内の複数の油井パッドなどのオブジェクトを検出しやすく、リコール(Recall)の最大化に寄与する
[EfficientNet-B3]
・ImageNetなどの大規模なデータセットで訓練されたモデルであり、高精度な分類を行うための深い層と広い受容野を持つため、油井パッドのような特徴的なパターンを正確に識別することができる
・このため、誤検出を減らす(偽陽性を排除する)段階での性能が非常に優れている
◾️貯蔵タンク検出の設計
①仮説課題
・貯蔵タンクは通常、油井パッド自体よりも小さく、より精度の高い検出が求められる
②解決策
・貯蔵タンク検出の精度を高めるために、Faster R-CNNに加えて、Res2Netバックボーンを使用するアーキテクチャを採用する
・Res2Netは、スケール変動に強い構造であり、貯蔵タンクのように小さな物体でも複数スケールで検出が可能である
・さらに、タンクの小ささに対応するために、アンカーボックスのスケールを調整し、より精度の高い検出が可能になるようハイパーパラメータを最適化する
③補足
[Faster R-CNN]
・二段階検出モデルであり、最初に領域提案ネットワーク(RPN)を用いて、画像内でオブジェクトが存在する可能性の高い領域を生成する
・次に、これらの領域に対して物体分類と境界ボックス回帰を行う
・画像内の複数のオブジェクトや、小さな物体の重なりを避けるためのNon-Maximum Suppression(重複した検出結果を排除するアルゴリズム)が含まれている
[Res2Net]
・標準のResNetに比べてスケールバリエーション(多様なスケールで特徴を抽出する能力)に優れている
・上記により、異なるサイズの貯蔵タンクや、視覚的に異なるタンクを同時に検出できる
・より多くの特徴を階層的に抽出するため、検出精度が向上する
【議論の内容・結果は?】
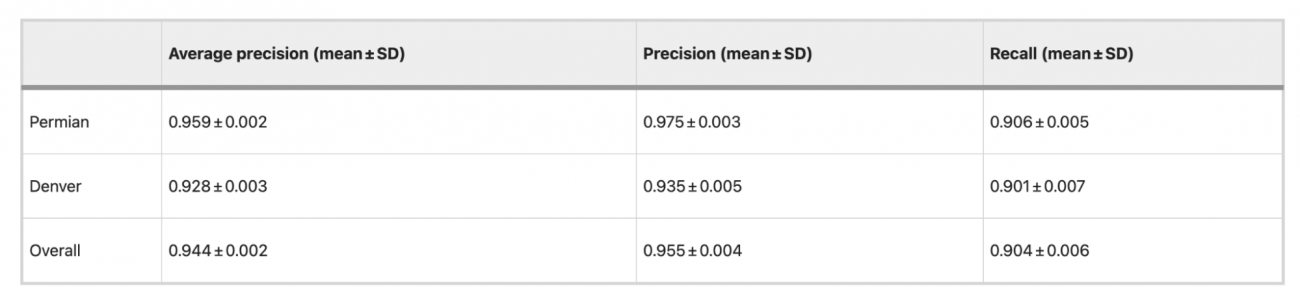
◾️油井パッド検出
①地域別の平均精度比較
[Permianエリア]
・平均精度: 0.959 ± 0.002
・精度: 0.975 ± 0.003
・再現率: 0.906 ± 0.005
・高い精度と再現率を達成しており、全体としてモデルは非常に信頼性の高い検出能力を持っていることが分かる
[Denverエリア]
・平均精度: 0.928 ± 0.003
・精度: 0.935 ± 0.005
・再現率: 0.901 ± 0.007
・Permianよりもやや平均精度が低く、再現率も若干低いが、依然として高い検出性能を維持している
②サイズ別精度比較
[小型パッド (164m²)]
・Permianでは 11.1% が大型で、平均精度は 0.944 ± 0.001
・Denverでは 13.2% が大型で、平均精度は 0.953 ± 0.012
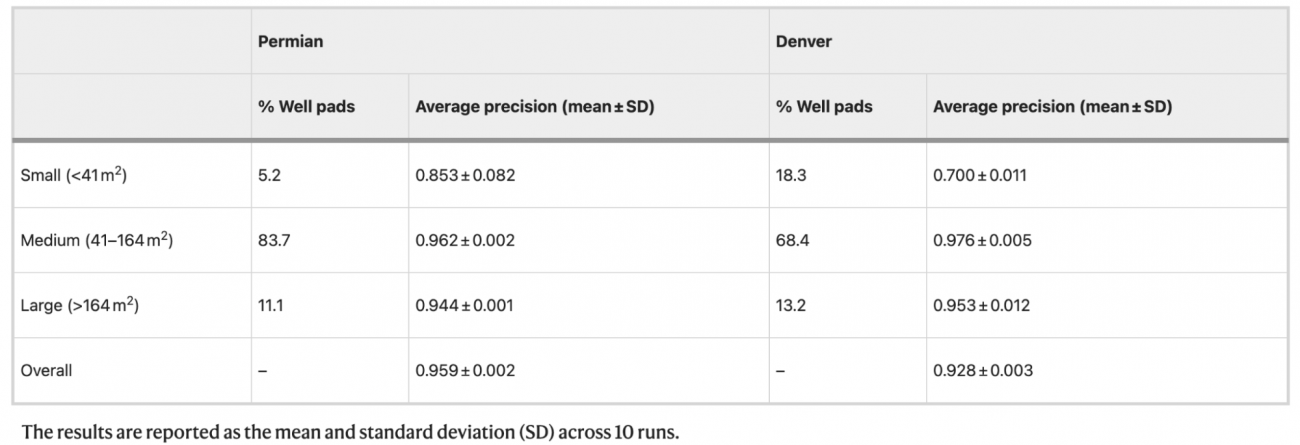
③上記による示唆
・全体として、DenverではSmallパッドの割合がPermianに比べて多く、検出精度が低いことがわかる
・Smallパッドの検出は両エリアにおいて低い精度となっており、特にDenverでは著しく低い(0.700)
・中型/大型のパッドでは、どちらの地域でも非常に高い精度を維持しており、今後の他地域での展開にも自信を持てる結果といえる
・Denverは都市インフラの影響が大きいため、都市特有の誤検出要因に対する対策が重要と考える
◾️貯蔵タンク検出
①平均精度
・Permianエリアで0.989、Denverエリアで0.981という高い値を達成した
②PrecisionとRecall
・Permianでは精度0.965、リコール0.972、Denverでは精度0.957、リコール0.963という結果であった
③示唆
・貯蔵タンクの色が(隣接する)油井パッドの色と低コントラストである場合、モデルが貯蔵タンクを検出できないことがあった
・貯蔵タンクではない他の円筒形の設備を貯蔵タンクとして誤って検出するケースが見られた
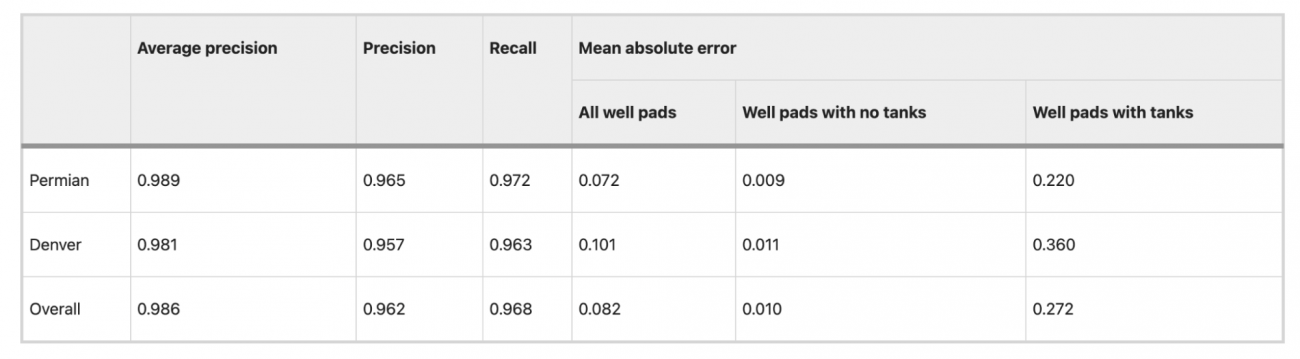
④モデルの汎用性評価
・なお、貯蔵タンクモデルは、新しい地域への適応能力も評価した
・結果としては、Anadarko盆地(精度およびリコールが0.930以上)、Uinta-Piceance盆地(0.900以上)、TX-LA-MS Salt盆地(0.850以上)で、良好な性能を示した
・Appalachian盆地では精度およびリコールが0.500に落ち込み性能が低下したが、これは油井パッドが小さく、また樹木や影で隠れていることが多いこともあり、検出が難しいためと考えられる
◾️PermianとDenverにおける油井パッド検出のリコール率評価
①Permianエリア
・Enverusデータセット: 80.5%
・HIFLDデータセット: 73.3%
②Denverエリア
・Enverusデータセット: 68.1%
・HIFLDデータセット: 46.1%
③データセットの違いによるリコール率の差異
・Enverusデータセットは2021年までの最新データが反映されており、頻繁に更新されているため、より最新の油井パッド情報が含まれており、モデルの検出結果と一致しやすく、リコール率も高くなっている
・HIFLDデータセットは2019年に公開されており、一部の州ではデータが古くなっている可能性がある(特にDenverエリアでは、データが2014年までしか反映されていないため、現在では存在しない油井パッドや、位置が不正確なデータが含まれている可能性がある)
#油井パッド #貯蔵タンク #FasterRCNN #RetinaNet #SSD #YOLOv3 #ResNet #EfficientNet
Scalable interpolation of satellite altimetry data with probabilistic machine learning
【どういう論文?】
・本論文は、衛星高度計データの効率的な補間において、従来の手法に比べて計算速度を大幅に向上させ、海氷や海面変動の高精度予測を可能にするGPSat手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
・CryoSat-2やICESat-2などの衛星高度計は、広い範囲を短時間で観測するものの、解像度の制約や観測点の不足により、データの空間的・時間的補間が必要になってくる
・これまでは統計的な補間手法(最適補間、ガウス過程(GP)回帰など)が用いられてきたが、大規模データを扱う際にスケーリングの問題が生じる
・また、データ数が増えると、逆行列の計算にかかる計算量が急激に増加するため、計算時間が膨大になり、データのサブサンプリングが必要となってくる
・上記により、計算コストが高くなるだけでなく、データの精度も低下する
・実際に、先行研究(G21手法)では、並列HPC(高性能コンピュータ)環境を使っても、50 km解像度のCryoSat-2やSentinel-3のデータを1か月分処理するのに36時間を要しており、データ処理の遅さが問題となる上、計算時間を削減するためのサブサンプリングにより、精度の低下を招いている
◾️本研究のアプローチ
①GPSatによる効率的な補間
・本研究では、機械学習で進展してきたスケーラブルな逆問題解法を取り入れ、GPSat(一度に複数の部分を同時に計算して補間するツール)というPythonライブラリを開発
②補間精度を保ちながらの大幅な高速化
・GPSatは、従来の補間手法(G21)と比較して、計算速度を大幅に向上させながら、予測精度を維持する
③高解像度データへの拡張性
・スケーラビリティを高く持ち、5kmやそれ以下の高解像度データにも対応する
・上記により、より詳細な気候モデルや海氷予測が可能となり、従来手法では見落としていた小規模な変動も把握できるようにする
④データに依存しない柔軟性
・データ非依存として、衛星データ以外にも気象データなどにも応用できるようにする
◾️手法(GPSatの解説)
①従来の技術的課題
・従来のG21手法では、各グリッドごとに独立してガウス過程(GP)モデルを最適化する必要があった
・つまり、各地点ごとに局所的なデータを使ってモデルを訓練し、その地点での予測を行うもので、たとえば海氷があるすべてのグリッドポイントで同じ処理を繰り返す必要があり、計算量が膨大になるという課題があった
・また、近接するグリッドポイントで重複するデータを使用することになり、効率が悪くなる
②GPSatによる効率化
・GPSatは上記課題を解決するために、ローカルエキスパートモデルを導入する
・各予測地点ごとに独自のモデルを構築するのではなく、200km間隔でローカルエキスパートを配置し、各エキスパートが担当する領域内のデータをまとめて処理する
・上記により、データの重複を排除しつつ、計算効率を大幅に向上させる
③実際のライブラリ開発のステップ
[海氷レーダーフリーボードデータの取得と処理]
・CryoSat-2(CS2)およびSentinel-3(S3)衛星から取得されたレーダー信号データを用いて、海氷の表面からのレーダー反射地点までの距離を測定する
・上記は、海氷の物理的な高さではなく、レーダー信号が反射された「レーダー反射基準面の高さ」となる
・衛星から得られたデータ(Level-0)は未加工で、直接使用することが難しいため、ESAのGPOD SARvatoreサービスを利用して、Level-1Bデータに変換する
・上記により、レーダー信号がどこで反射されたかを解析できるようになり、次にこれをEASEグリッド(50 km、5 km)に整理する
[Sea-Level Anomaly(SLA)データの取得と処理]
・衛星から取得された瞬間的な海面高度データを使用して、基準となる平均海面(MSS)との差分を計算し、SLA(局所的な海流や海面の変動を分析するための基礎データ)を導き出す
・取得した海面高度を、過去2年間のデータ(2011年~2013年)を基にした平均海面データと比較し、局所的な海面の異常(SLA)を計算する
・本手法により、局所的な気候変動や海流の変動をより精密に把握できるようになる
[補助データの使用(海氷集中データ・OIBデータ]
・NASAのNSIDCによるデータを利用して、各地点での海氷の密度や位置情報を取り込み補間結果の精度が向上さえる
・特に、海氷が75%以上集中している地点をターゲットにすることで、海氷が薄い領域では不確実性が増すことを回避する
・2019年のNASAのOperation IceBridgeキャンペーンデータを使用し、航空機による雪の厚さデータを基にした「スノーフリーボード」の測定結果とGPSatの補間結果を比較・検証させる
[ガウス過程(GP)モデルのトレーニング]
・空間・時間的相関の学習 ガウス過程モデル(GPモデル)を使用して、観測データ間の空間的・時間的な相関を学習さセル
・本モデルでは、局所的な観測データ(例えば、300 kmの範囲と±4日間のデータ)を基に、未観測地点での予測を行う
・モデルのハイパーパラメータ(共分散やノイズレベル)を最適化し、過学習を防ぎながら精度の高い予測を行う
・解像度が5 km以下になるとデータがノイズに敏感になるため、ノイズを扱うための工夫が導入されており、例えば、ノイズの分散パラメータに下限を設け、データのノイズに過剰にフィットしないように制御している
【議論の内容・結果は?】
◾️精度比較
①前提
・G21N(NumPy CPU)の結果(2019年1月15日における補間されたレーダーフリーボードの予測結果)を「基準」として、他の手法の結果と比較する
・G21N(NumPy CPU)とは、従来のG21手法であり、NumPyを用いて線形代数演算を行い、SciPyを使用して最適化処理を実行する
・G21A(Tensorflow CPU)とG21B(Tensorflow GPU)とは、G21手法をTensorflowに置き換えたバージョンで、CPUとGPUで実行される
・GPSatA(Tensorflow CPU)とGPSatB(Tensorflow GPU)は、GPSat手法を使用したモデルであり、ローカルエキスパートモデルを導入して計算効率を向上させている
②結果
・G21AとG21Bはそれぞれ2mm、GPSatAは3mm、GPSatBは4mmの誤差を示した
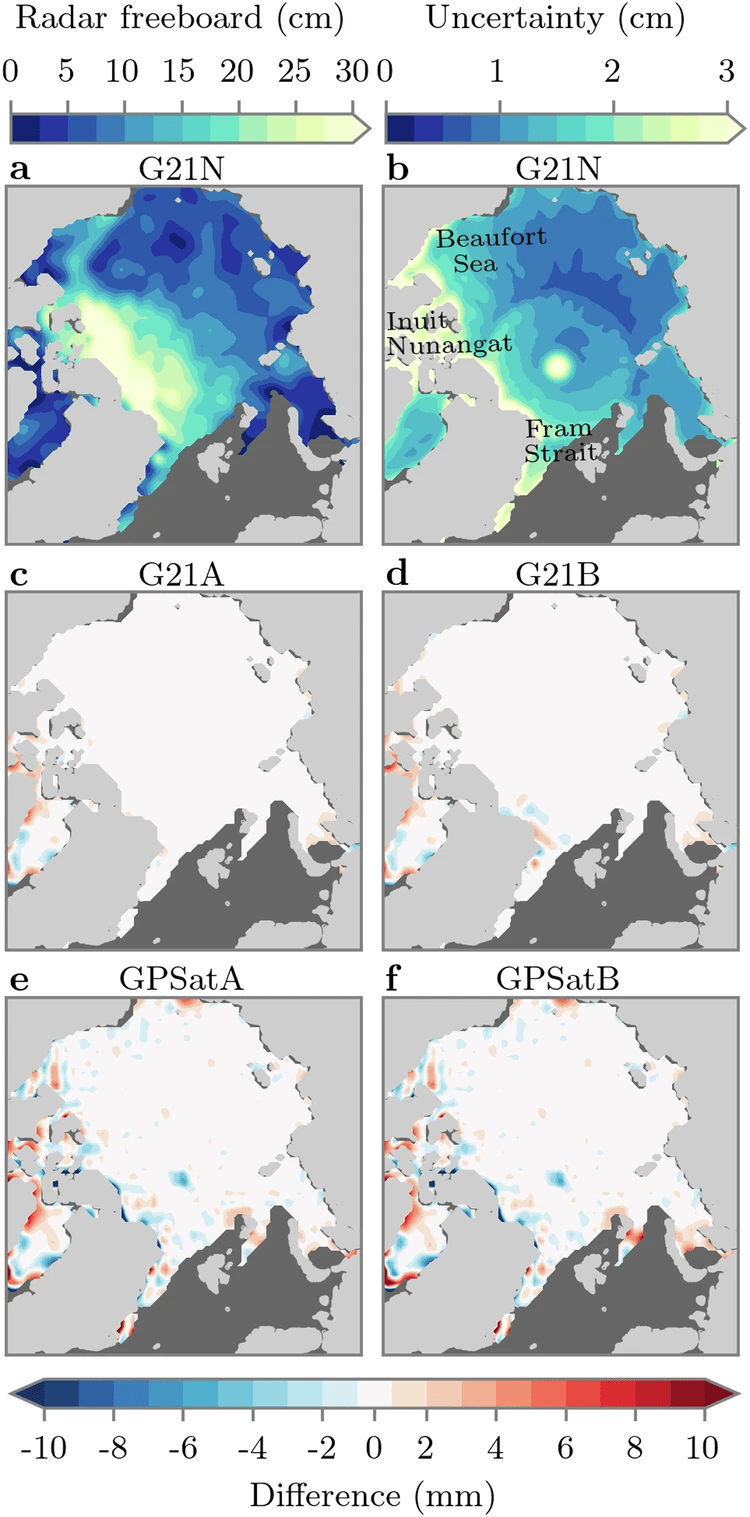
◾️時間比較
・GPSatAは43.5時間、GPSatBは9時間で計算を完了し、G21Nに比べてGPSatBでは504倍のスピードアップを実現した
・ローカルエキスパートの間隔を600 kmに広げたGPSatBでは、計算時間はわずか2時間で、2270倍のスピードアップとなった
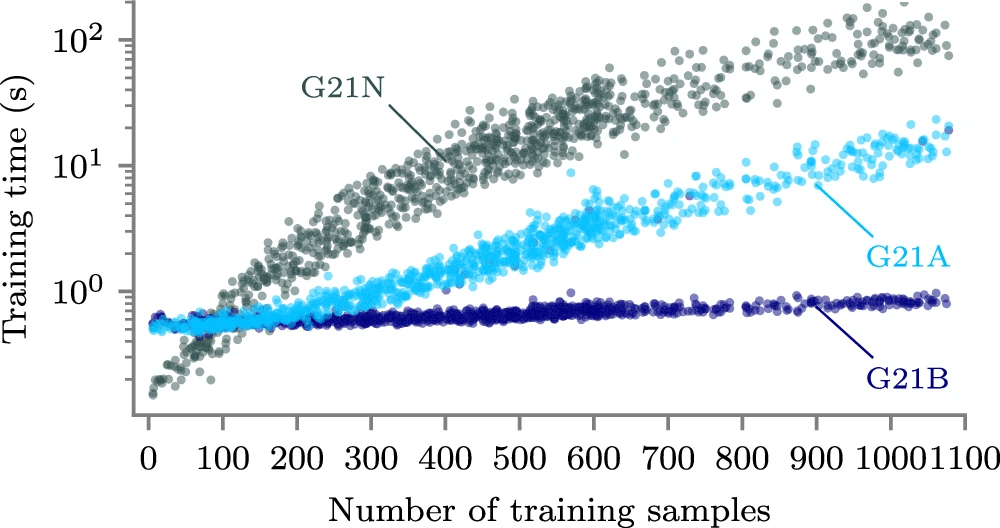
#衛星高度計 #海氷変動 海面変動 #GPSat #CryoSat-2 #ICESat-2 #ガウス過程回帰 #ローカルエキスパートモデル #G21N
A satellite-derived baseline of photosynthetic life across Antarctica
【どういう論文?】
・本論文は、南極大陸全体の陸上および氷雪環境における光合成生物(維管束植物、コケ、緑藻、地衣類、緑雪藻)の分布をSentinel-2衛星のデータを用いて地図化し、基礎的な生物地理データを提供する手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
・従来の研究では、主に南極の一部地域に限定され、南極大陸全体を網羅する基礎的な植生マップが存在しておらず、大陸規模での植生の面積や分布が定量化されていない
・また、Landsatの低解像度(30m/pixel)やNDVI(正規化植生指数)のしきい値設定の不十分さから、誤検出が多く含まれていた
・地衣類やコケ類のような低緑度の植生や、水中植生は従来の方法では検出が困難であり、植生の種類やステージによっては正確に識別されないケースが多かった
◾️本研究のアプローチ
・高解像度(10m/pixel)のSentinel-2データを用いつつ、NDVIやNDMI(正規化差分湿度指数)といったスペクトル指標を組み合わせることで、南極大陸全域にわたる植生の分布を正確に検出する
・また、GRVI(Green Red Vegetation Index)、NDRE(Normalized Difference Red Edge Index)という追加指数を適用して、(他の植生(特に緑色植物)とは異なる光反射特性を持つ)地衣類の検出を行う
◾️データセット
・Sentinel-2A/2B衛星の2017年から2023年の表面反射データを使用する
・6つのマルチスペクトルバンド(可視光から短波長赤外線まで)をカバーする
・なお、衛星は太陽同期軌道を通過するため、常に同じ時間帯に同じ場所を観測するものの、極域では直接通過しないため、南緯82.8度以南にはデータが存在しない「polar hole(極域のデータ欠落区域)」が発生する
・特に南緯60度以南の氷のないエリアを対象にしており、約82,000シーンが解析に利用されている
【議論の内容・結果は?】
◾️植生分布関連
・2017年から2023年までのデータを使用して、南極全域の植生をマッピングし、検出された植生は合計44.2 km²に及んだ(本面積は、解析対象の氷のない地域全体の0.12%に相当する)
・南極全体にわたる検出結果では、植生の大部分が海洋性南極地域(南極半島とその周辺の諸島)に集中していることが明らかになった
・また、植生の約40%が南極の重要な鳥類生息地(IBAs)から5km以内に存在していることが確認できた
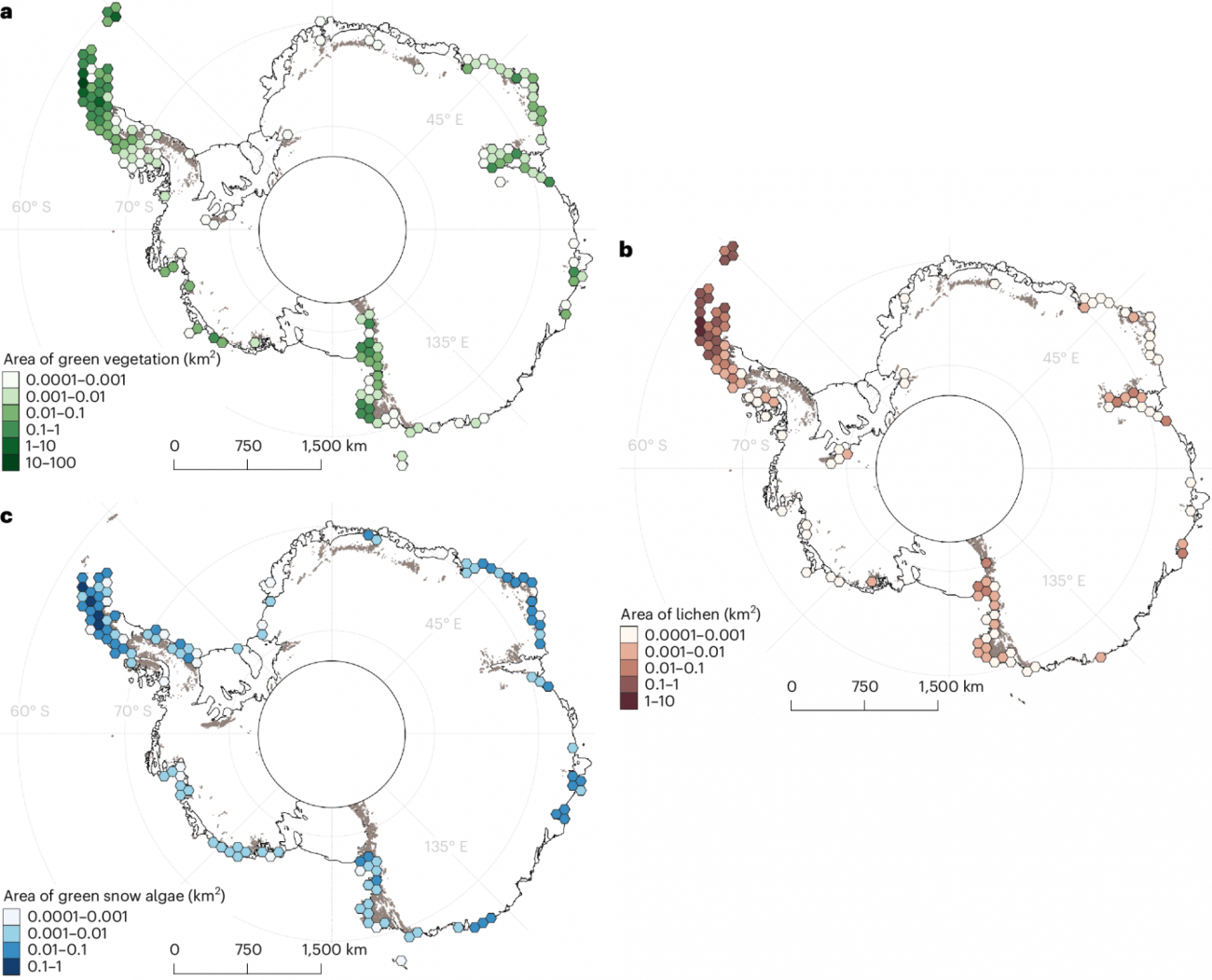
※c: 氷圏植生(緑雪藻類)
※Walshaw, C.V., Gray, A., Fretwell, P.T. et al. A satellite-derived baseline of photosynthetic life across Antarctica. Nat. Geosci. 17, 755–762 (2024).
◾️精度関連
・以下の表では、Sentinel-2のピクセル内で各植生クラスを検出するために必要な最小面積が示されている
・緑色スノーアルジーは、ピクセルのわずか10分の1(11m²)をカバーしているだけで検出可能であり、氷床上のアルジーの検出感度が高いことがわかる
・対して、緑色植生は、少なくともピクセルの半分(52m²)をカバーする必要があり、地衣類は検出が最も困難で、ピクセルの3/4(79m²)を占める必要があることが示されている
・なお、リモートセンシングによる植生検出は、陸地・海洋のいずれにおいても偽陽性が発生した
・また、研究所のインフラが誤って植生として検出されるケースも0.01km²(10,000m²)だけ存在した
・スノーアルジーに関しては、混合ピクセルや氷のクレバス、さらには雪中の鉱物破片などが誤検出の原因となったと考えられる
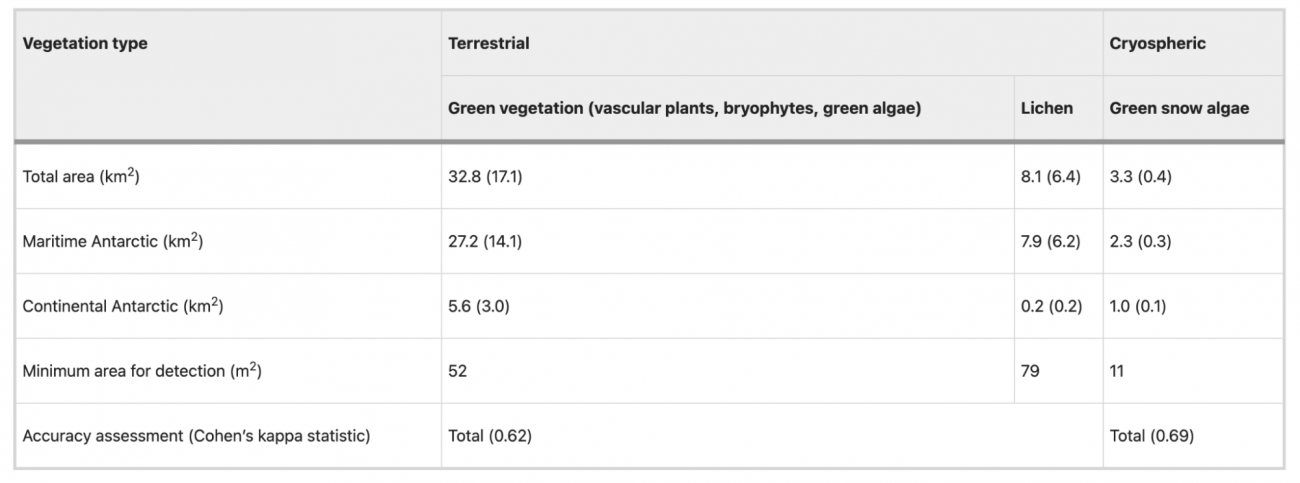
#南極大陸 #光合成生物 #維管束植物 #コケ #緑藻 #地衣類 #緑雪藻 #Sentinel-2 #Landsat #NDVI #NDMI #GRVI #NDRE
A deep learning-based combination method of spatio-temporal prediction for regional mining surface subsidence
【どういう論文?】
・本論文は、K-meansクラスタリングによる空間分割とGRUモデルを組み合わせた新しい地盤沈下予測手法を提案し、スネーク最適化アルゴリズムを用いてパラメータを最適化することで高精度な予測を実現する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
①空間的相関の欠如
・現行のディープラーニングモデルは、地域ごとの地盤沈下の関連性(空間的相関)を十分に考慮しておらず、予測の精度が低下している
②時間的非線形性の不考慮
・地盤沈下は時間的に非線形に変化するが、その特性が十分に捉えられていない
(たとえば、初期の沈下は緩やかであっても、地下構造の崩壊が進むにつれて急激に沈下が進行する場合がある)
③パラメータ調整の難しさ
・高精度な予測を行うためには、モデルのパラメータ(学習率、ニューロン数など)を手動で調整する必要があり、これが非常に複雑である
◾️本研究のアプローチ
・ 地域ごとの地盤沈下パターンの違いを考慮するために、K-meansクラスタリングを用いて空間的にデータを分割し、それぞれの地域に対して個別のモデルを適用し、各地域の地盤沈下パターンを正確に捉え、全体としての予測精度を向上させる
・ゲートリカレントユニット(GRU)という、リカレントニューラルネットワークの一種で、時間依存性のあるデータの非線形的な変化を学習するのに適しているモデルを利用して、地盤沈下の時間的な非線形性を効率的に捉え、長期間にわたる地盤沈下の予測精度を向上させる
・スネーク最適化アルゴリズム(SO)を使用して、GRUモデルのパラメータを自動的に最適化し、手動での調整の手間を省くことで、精度と効率を向上させる
◾️データセット
・Sentinel-1A/B衛星によって収集されたCバンド合成開口レーダー(SAR)データを利用する(2019年1月10日から2021年4月5日までの66枚のSAR画像)
◾️手法
①SBAS InSARによるデータ処理
・SBAS InSARは、地表の微小な変位を高精度に捉え、広範囲の地盤沈下を時空間的に解析する技術である
・補間処理を行い、地盤沈下の時系列データを得ることができる
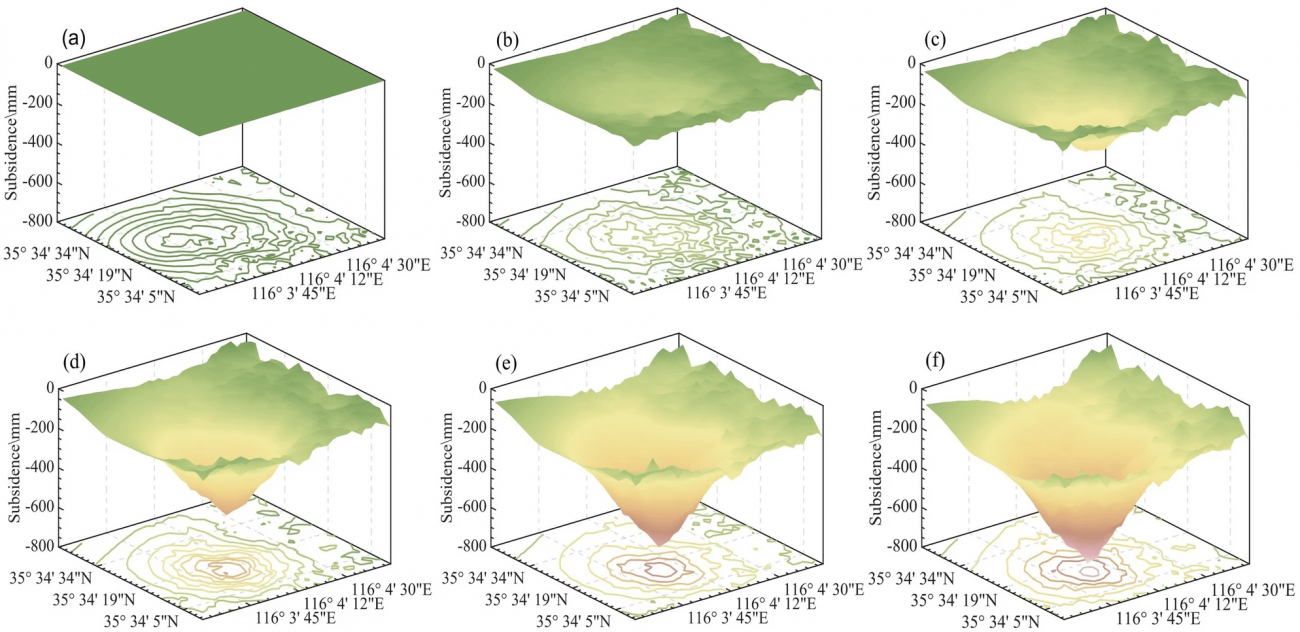
※(a) 2019 年 1 月 10 日~2019 年 3 月 11 日
※(b) 2019 年 1 月 10 日~2019 年 7 月 9 日
※(c) 2019 年 1 月 10 日~2021 年 11 月 18 日
※(d) 2019 年 1 月 10 日~2020 年 3 月 17 日
※(e) 2019 年 1 月 10 日~2020 年 9 月 13 日
※(f) 2019 年 1 月 10 日~2021 年 4 月 5 日
※Xiao, Y., Tao, Q., Hu, L. et al. A deep learning-based combination method of spatio-temporal prediction for regional mining surface subsidence. Sci Rep 14, 19139 (2024).
②水準測量データとの比較
・211の測定点で収集された水準測量データとSBAS InSARの結果を比較し、結果の整合性と精度を検証する
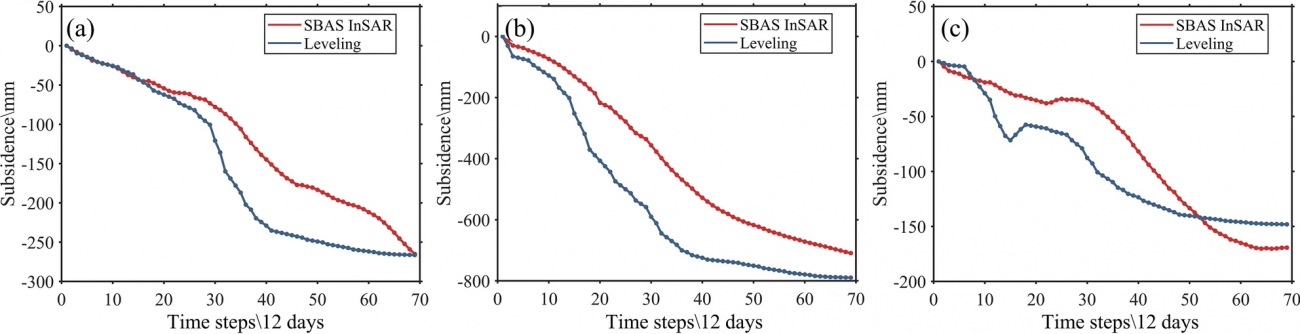
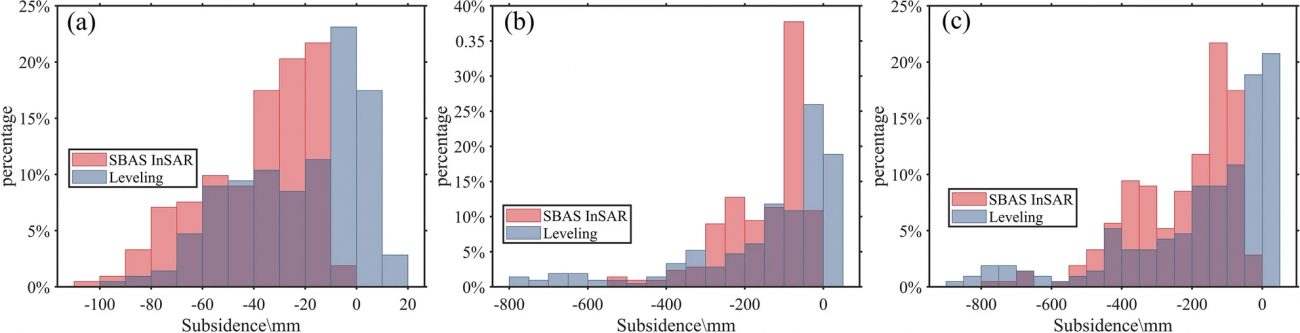
③K-meansクラスタリングによる空間分割
・K-meansクラスタリングを用いて、時空間的な距離に基づいて観測データをクラスタリングする
・上記により、空間的に相関の強いピクセルを同じクラスターに分類し、それぞれ異なるモデルを適用する準備を行う
④GRUモデルの適用と最適化
[GRUのアーキテクチャ]
・ GRUには2つのゲート(更新ゲートとリセットゲート)があり、これが「いつ、どの情報を保存し、どれを忘れるか」を決定するというゲート機構がある
・LSTMと比べて、GRUはゲートが少ないため、素早く意思決定でき、更新ゲートとリセットゲートによって、どの情報を残すかを調整することで、長期間の依存関係を効果的に保持することで、時間依存性のあるデータの非線形な変化に対応する
[内容]
・GRU(ゲートリカレントユニット)モデルを用いて、クラスタごとに時間的な非線形関係を学習する
・本ステップは、地盤沈下の進行が時間とともに非線形的に変化する場合に、予測精度を高めるための重要である
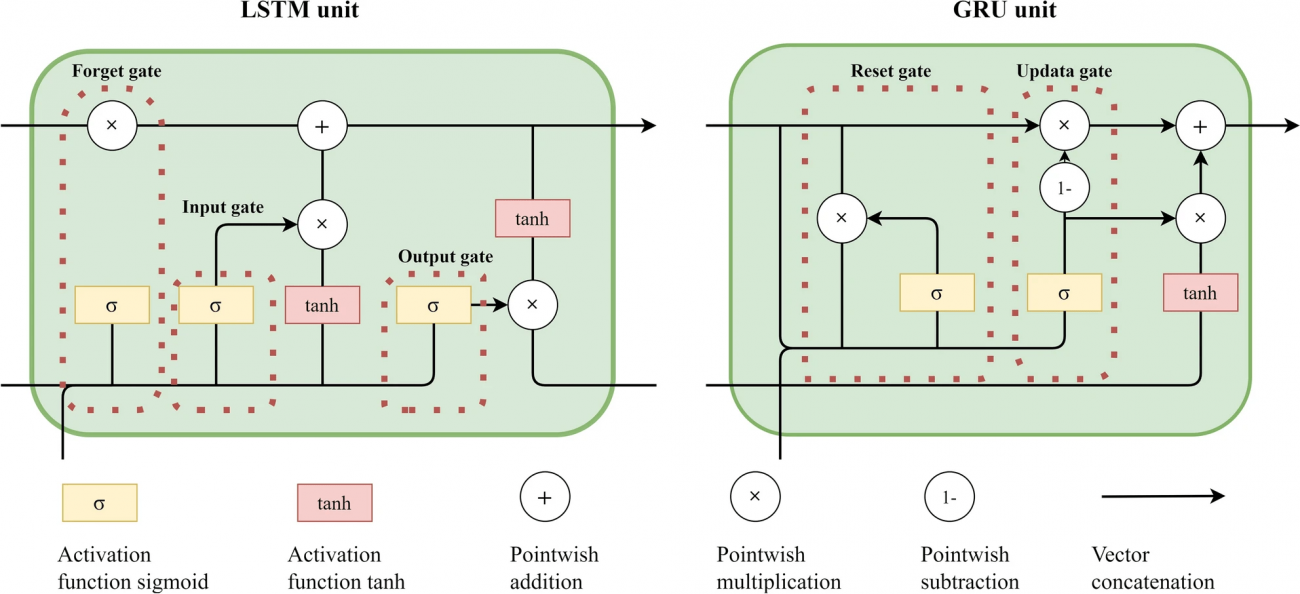
⑤スネーク最適化アルゴリズム(SO)によるパラメータ最適化
[既存手法]
・勾配降下法は、勾配(最も急な下り坂)に沿って目的関数の最小化を行うが、局所最適解に捕らわれることが多く、グローバルな最適解を見つけるのが難しい場合がある
[SOの特徴]
・ある程度のフィットネス(適応度)が良いパラメータセットに向かってゆっくりと「移動」する一方で、ランダムな変異(突然変異)を導入することにより、最適な解を探索する
・上記により、探索過程が滑らかであると同時に、新しいパラメータ領域も効率的に探索できる
・フィットネスの評価基準としてはRMSEを用いる
【議論の内容・結果は?】
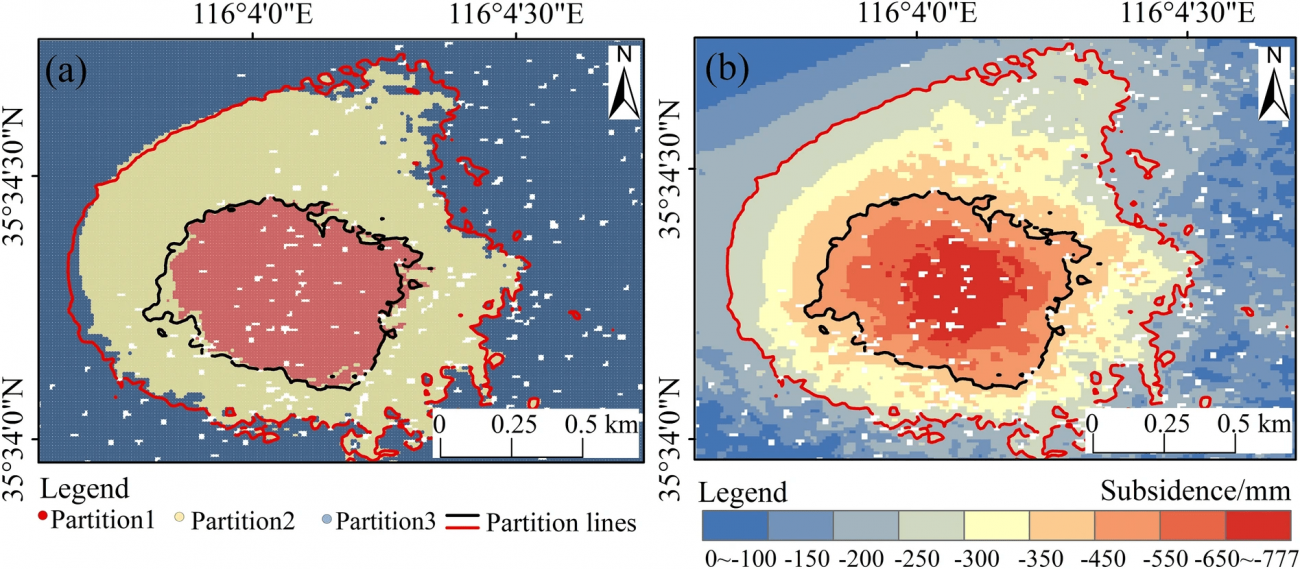
◾️K-meansクラスタリング結果
・クラスター数3の設定にて、SSE(各データポイントとそのクラスターの中心点との距離の二乗和)の明確なひじ点(SSEの減少幅が急激に小さくなる点)を確認することができた
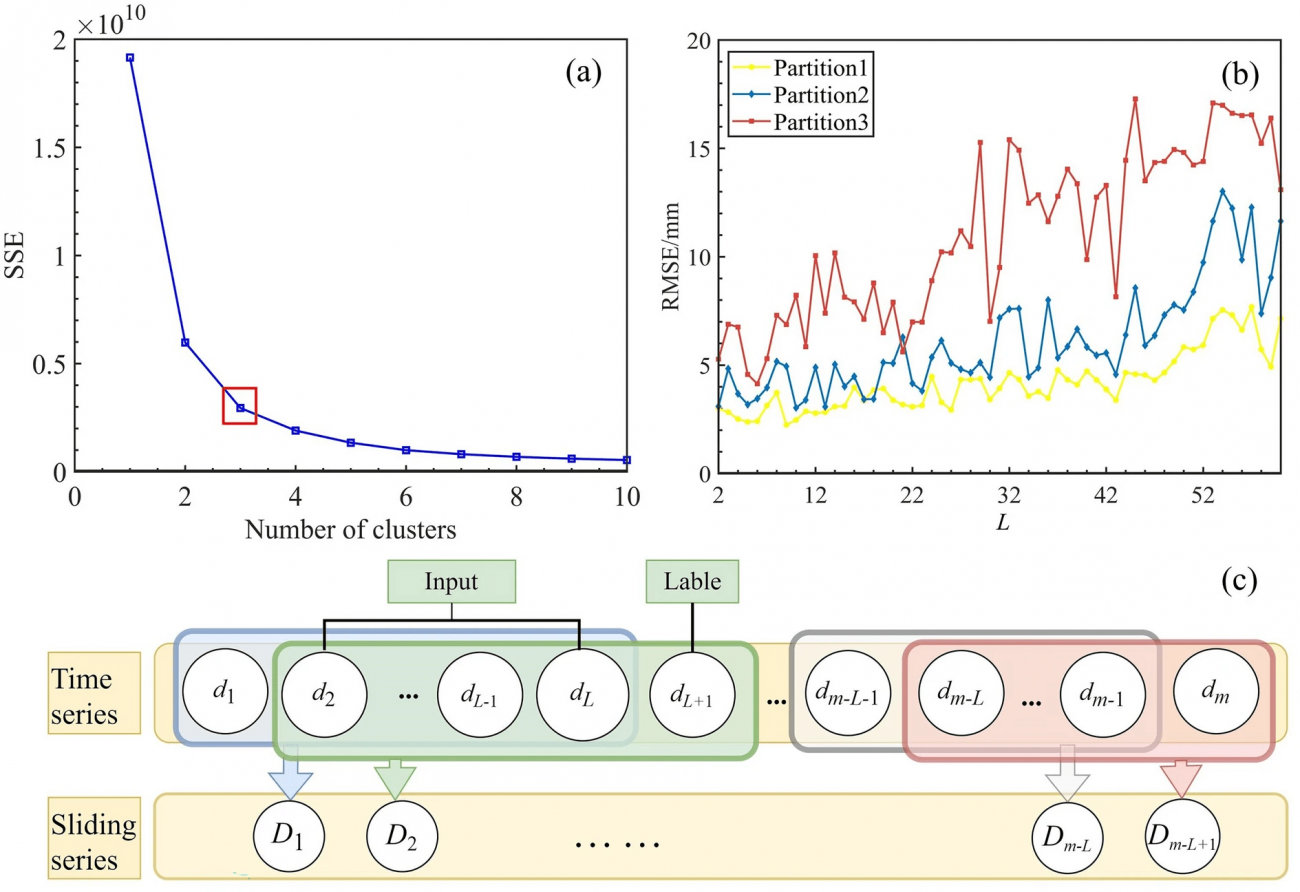
・上記に基づいて3つの領域に空間を分割できた
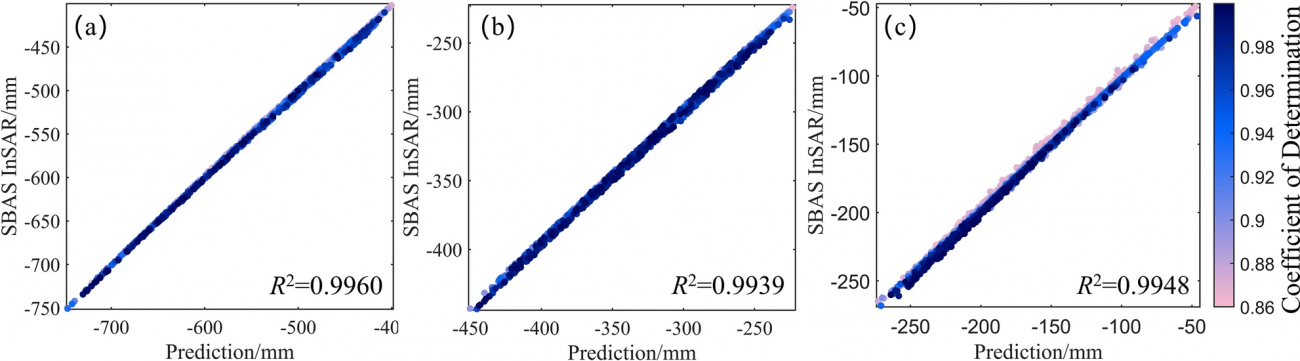
・各クラスター内の予測値と実測値の相関が視覚化され、全てのクラスターで決定係数R²が0.99に達した
・提案手法が他の2つの手法(GRUのみおよびLSTMのみ)に対して、明らかに優れた予測精度を持っていることが示された
・特に、複合予測法における99.1%のエリアが8mm未満の誤差範囲に収まっており、空間的分割とパラメータ最適化が予測精度向上に重要であることが視覚的に示唆されている
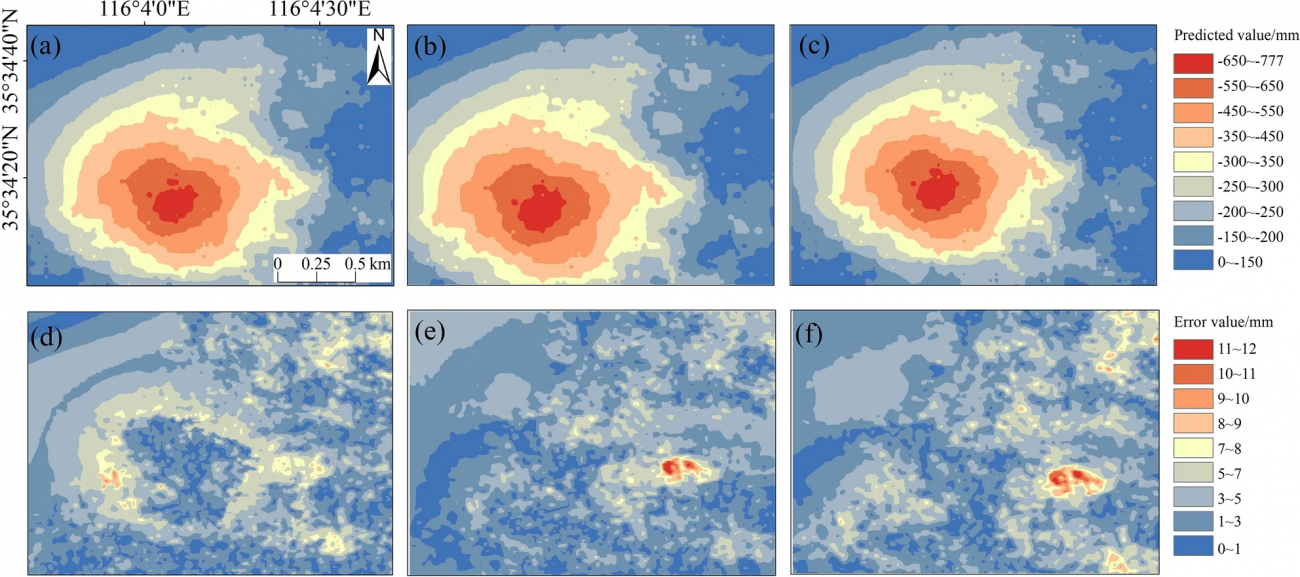
※(b)GRU による予測沈下
※(c)LSTM による予測沈下
※(d)複合予測法による予測誤差
※(e)GRU による予測誤差
※(f)LSTM による予測誤差
※Xiao, Y., Tao, Q., Hu, L. et al. A deep learning-based combination method of spatio-temporal prediction for regional mining surface subsidence. Sci Rep 14, 19139 (2024).
#K-meansクラスタリング #GRUモデル #地盤沈下予測 #スネーク最適化アルゴリズム #Sentinel-1 #LSTM
Semi-Automatic Detection of Ground Displacement from Multi-Temporal Sentinel-1 Synthetic Aperture Radar Interferometry Analysis and Density-Based Spatial Clustering of Applications with Noise in Xining City, China
【どういう論文?】
・本論文は、SBAS-InSAR技術とDBSCANアルゴリズムを組み合わせることで、広範囲の地滑りや地盤沈下を半自動的に検出する手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
①地滑りや地盤沈下の検出手法のばらつき
・従来のInSAR(合成開口レーダー干渉法)を用いた地盤変動検出手法は、干渉縞パターンの変化を基に、地表面のわずかな変位をミリメートル単位で捉える高精度技術である
・しかし、多くの場合、特定の変位量をもって「地滑り」とするか否かは閾値設定に依存する
・本閾値は、変位速度や加速度に基づくものが多く、地域や環境に応じて異なり、特定のしきい値(例えば年間数cm以上の変位)を超えるとリスクとみなされる
・これらの閾値は経験に基づいて設定されるため、同じ現象に対しても研究者によって異なる結果が得られることがある
・さらに、閾値設定は一律ではなく、斜面の傾斜角度や地質の特性などの要因を考慮しなければならないため、統一的な基準を確立するのが困難であった
②大規模データに対する自動化の欠如
・InSARデータは非常に広範囲をカバーすることが可能で、例えばSentinel-1衛星のデータは数百キロメートル単位の領域を数日単位で観測できる
・しかし、地盤変動の兆候を示すInSAR測定点(Interferometric Measurement Points: IMP)は膨大な数にのぼり、1つの観測範囲で数百万点に及ぶことがある
・従来はこれらのIMPから変動を検出する際に、専門家が一部の重要なポイントに着目し、手動で分析を行ってた
◾️本研究のアプローチ
①SBAS InSARとDBSCANを組み合わせた半自動検出の提案
・本研究では、従来の手動閾値設定の代替として、SBAS-InSAR技術とDBSCANアルゴリズムを組み合わせた手法を提案する
・広範囲のデータから地盤変動を半自動的に検出し、事前にクラスタの数を設定する必要なく、ノイズを除外した自動クラスタリングが可能となる
・特に、DBSCANによりInSARデータの中から活発な斜面を特定し、一貫した検出結果が得られると仮説立てる
②LOS変位から2Dの変位に変換する新しいアプローチ
・本研究では、従来の視線方向(LOS)の変位データを東方向と垂直方向の2次元に変換し、斜面の動きの詳細な動態解析を行う手法を導入する
・本アプローチにより、地滑りの加速要因や臨界点を明らかにすることができ、地滑りのメカニズムをより正確に把握できると考える
◾️データセット
・2014年10月から2022年9月までの期間に取得されたSentinel-1衛星データを使用する
・具体的には、上昇軌道(path 128)からは197シーン、下降軌道(path 135)からは177シーンのSAR(合成開口レーダー)データを利用する
・これらのデータはTOPSAR(Terrain Observation with Progressive Scans SAR)モードを使用しており、解像度はレンジ方向および方位方向でそれぞれ5 mおよび20 mとなる
◾️手法
① SBAS InSAR解析
[データの準備と基準画像の選定]
・最初に、2018年1月2日に取得された衛星画像を「基準」として使用する
・本基準画像は、他の全ての画像(「二次画像」と呼ばれる)と比較するための基準点となる
・たとえば、10枚の画像がある場合、これらを一つの基準画像に揃えるように整列させる
・本プロセスは、画像の中の同じポイント(例えば建物の屋根や山の頂上)が正確に一致するように行う
[差分干渉画像の生成]
・次に、「差分干渉画像」というものを作成する(2枚の異なる時期の写真を重ね合わせて、その違いをハイライトする作業)
・上記により、地表面のわずかな動きを可視化できる
・たとえば、1年の間にほんの数ミリメートル動いた地面を、画像のピクセル単位で見つけ出すことができる
・マルチルックファクターを使って画像を滑らかにし、最終的な解像度を約20mにする
[時系列解析]
・ある地点が時間とともにどのように動いているかを追跡するための解析を行う
・データのノイズを減らし、信頼性の高い変位を計測するために、振幅の変動や時間的な安定性を基準にピクセルを選別する(振幅分散値(0.3)を基準とする)
[位相アンラッピング]
・地形や大気の影響を取り除き、地表面の正確な変動を計算するためのステップである
②2次元(2D)変位の抽出
[LOS方向の変位を東方向と垂直方向に分解]
・地表の動きは、衛星が観測する「視線方向」(LOS)の変位として測定されるが、この視線方向のデータを「東方向」と「垂直方向」に分ける
(衛星が斜めから地面を見ているため、動きが斜めのまま記録されるが、この斜めの動きを「縦方向」と「横方向」に分解するイメージ)
[ピクセルのリサンプリングと平均化]
・上昇軌道と下降軌道のデータは異なる時点や位置で取得されるため、まず両者を「リサンプリング」して、同じ場所でのデータを揃える
[多次元SBAS法による変位時系列の取得]
・時間とともにどのように地面が動いたかを追跡する時系列データを作成する
③DBSCANによるクラスタリングと地滑り検出
[DBSCANアルゴリズムの概要]
・DBSCANは、データの密集した場所(変位が多く発生している地点)を自動的に見つけるアルゴリズムである
・密度が高いエリア(変動が多い場所)は「コアポイント」として識別され、ノイズの多い領域や変動がほとんどない場所は「ノイズポイント」として分類される
[コアポイントの選定とクラスタ拡張]
・まず、DBSCANは未処理のデータポイントを選択し、その近くに十分な数のポイントがあれば、その地点をコアポイントとする
・次に、このコアポイントを基準にして、密度の高いデータを一つの「クラスタ」にまとめる
[パラメータの選定]
・DBSCANでは、クラスタを決める2つの重要なパラメータがある
・一つは「eps」(エプシロン)という、どれくらい近くのポイントを同じクラスタとして扱うかを決める距離、もう一つは「minPts」という、クラスタを形成するために必要な最小のポイント数である
・epsが大きすぎると、一つのクラスタが大きくなりすぎてしまい、小さな地滑りを見逃す可能性があり、逆に、minPtsが少なすぎると、意味のないデータが多く含まれてしまう可能性がある
[パラメータの最適化]
・本パラメータの設定は難しいため、OPTICSアルゴリズムを使って、epsの値を最適化する
[結果の評価と分類]
・最後に、クラスタリングの結果を光学リモートセンシング(地形の写真データ)と組み合わせて、どの地点が地滑りのリスクが高いかを手動で評価する
・上記により、変動の多い斜面や沈下地域を正確に分類し、地滑りリスクの高いエリアを特定する
【議論の内容・結果は?】
◾️平均 LOS と 2D 変位率マップ
・(a)と(b)に示されているのは、上昇軌道(ascending)と下降軌道(descending)のSentinel-1データセットから得られた視線方向(LOS)変位率マップである
・具体的には、衛星に向かって動いている場所(つまり、地面が少し持ち上がっている場所)は青色(正の値)で示され、逆に衛星から遠ざかっている場所(つまり、地面が沈んでいる場所)は赤色(負の値)で示されている
・なお、上昇軌道データのLOS変位率は−69.2 mm/年〜42.4 mm/年、下降軌道データでは−63.5 mm/年〜46.7 mm/年の範囲となっており、ほとんどの地点では、年間に10mm未満の変位しか発生しておらず、全体的に見てこの地域は比較的安定してるといえる
・(c)と(d)は、東方向(eastward)および垂直方向(vertical)の変位率マップとなる
(東方向: 最大で−56.5 mm/年、垂直方向: 最大で−68.2 mm/年)
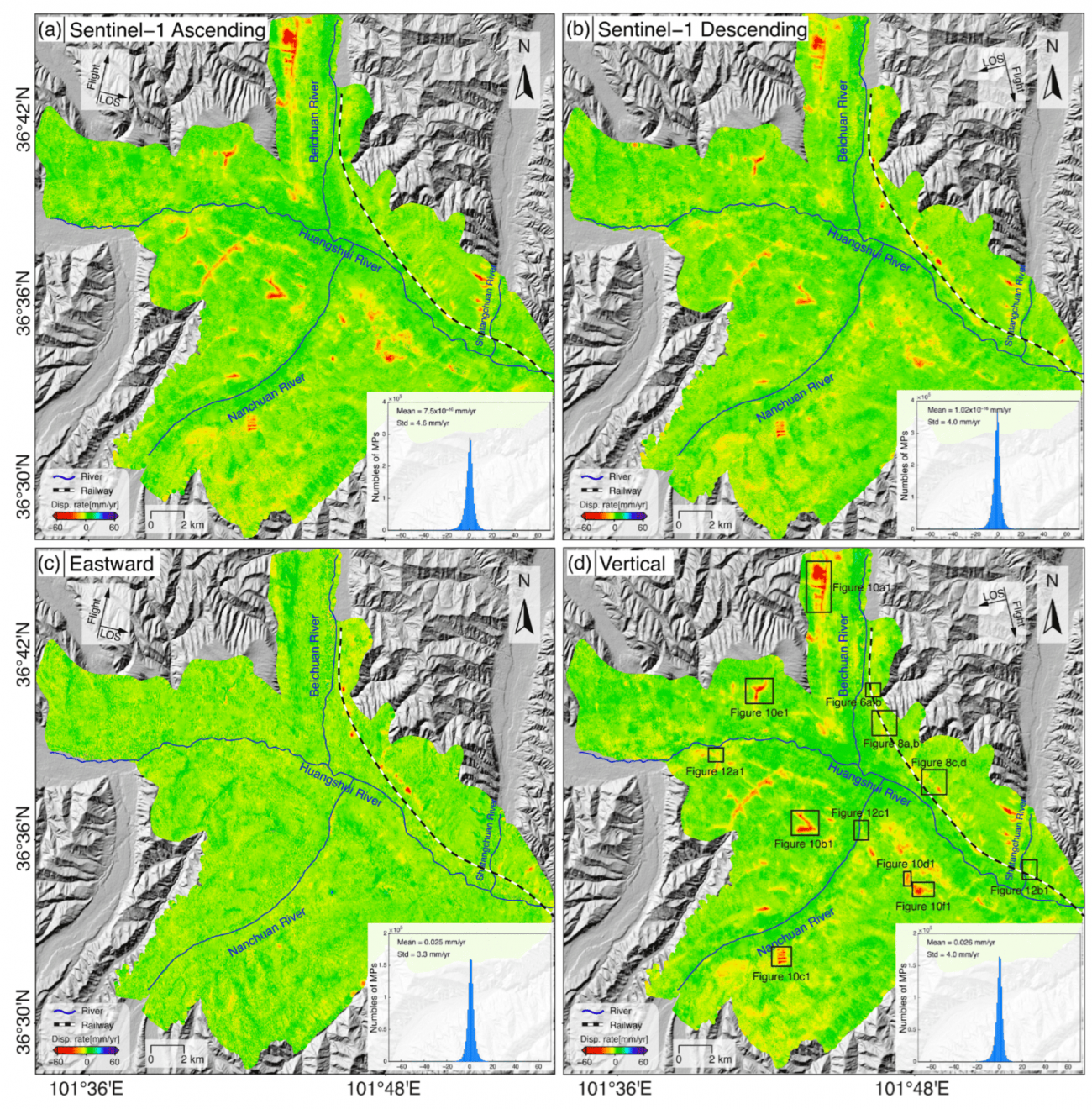
◾️視線方向(LOS)変位を2次元(2D)変位に変換した後の結果
・(a)は上昇軌道、図5(b)は下降軌道のDBSCANクラスタリングマップとなる
・これらは、地滑りや沈下のリスクが高い地域を自動的にグループ化して示している
・結果をさらに詳細に分析するため、地形学的特徴(地形の形状や地質情報)と2次元の変位マップを組み合わせた(c,d)
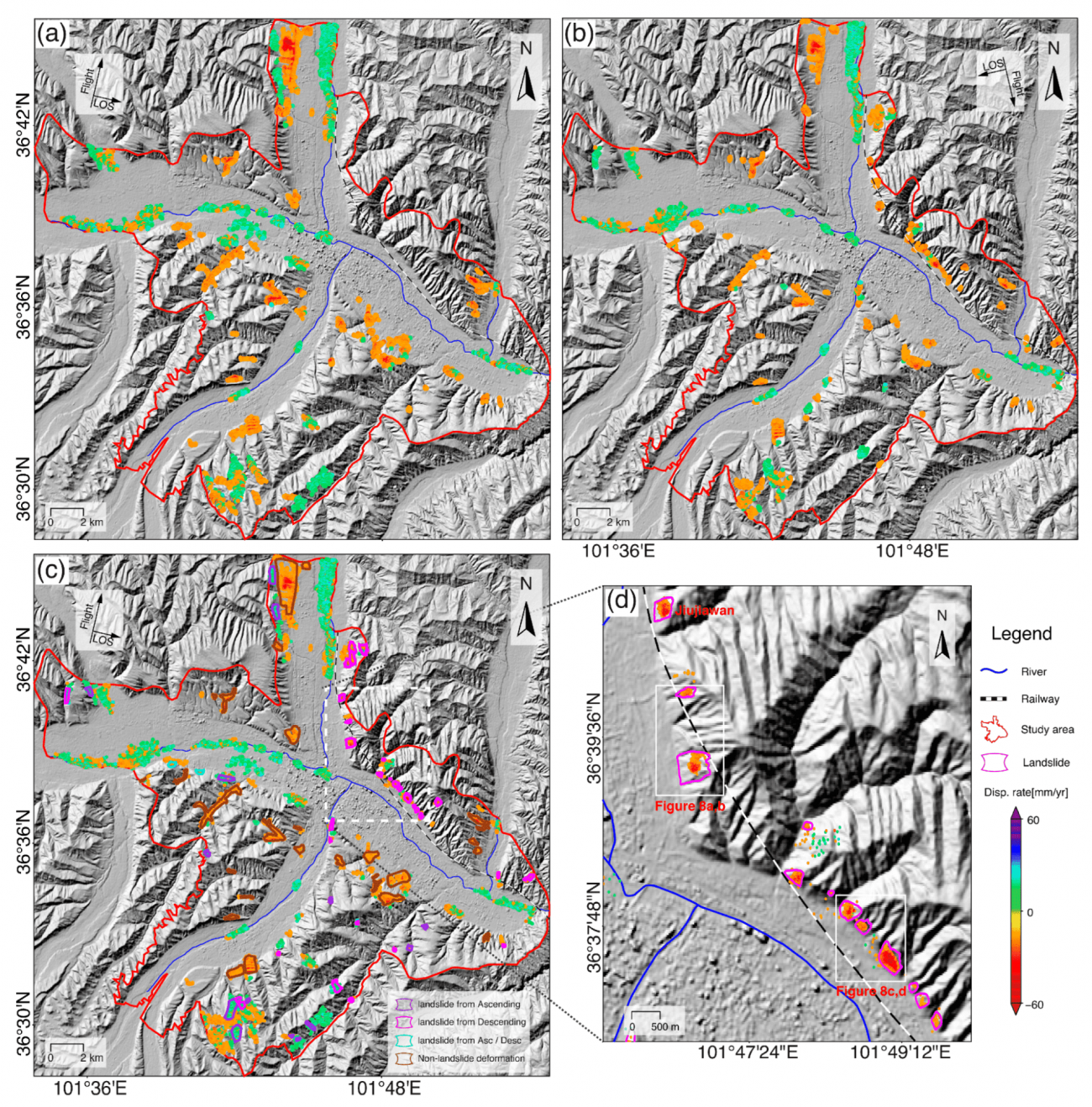
#SBAS-InSAR #DBSCAN #地滑り #地盤沈下 #Sentinel-1 #LOS
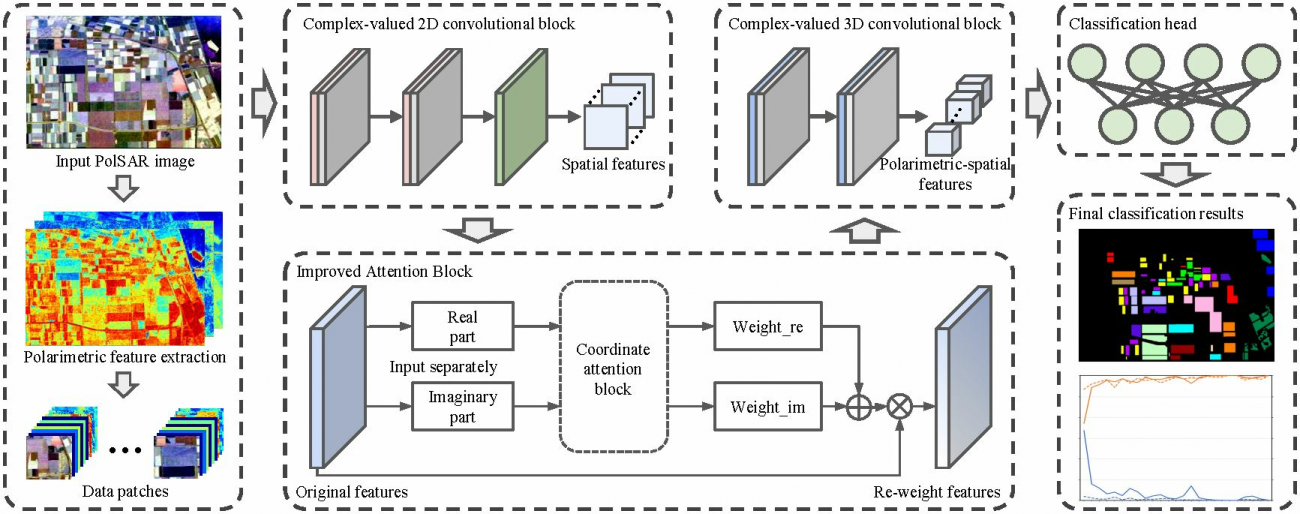
Complex-Valued 2D-3D Hybrid Convolutional Neural Network with Attention Mechanism for PolSAR Image Classification
【どういう論文?】
・本論文は、Polarimetric Synthetic Aperture Radar (PolSAR) 画像分類のための複素数値2D-3Dハイブリッド畳み込みニューラルネットワークを提案する
【技術や方法のポイントはどこ?】
◾️前提知識
①Polarimetric(偏波)とは
・偏波とは、電磁波が振動する方向のことを指す
・電磁波は一般に、水平偏波(H)と垂直偏波(V)の2種類の振動モードを持つ
・PolSARは、この偏波情報を利用して、物体の表面特性や形状、材質を識別することができる
②PolSARのデータ構造
・PolSARデータは複素数の行列(散乱行列)として表され、位相(物体の反射の仕方によって電波の「戻ってくるタイミング」)と振幅(物体の反射の仕方によって電波の「戻ってくるタイミング(位相)情報を持つため、通常の画像データとは異なる
・電波が地表にあるいろんな物体にぶつかって反射する様子を4つの視点(水平と垂直の偏波の組み合わせ)から見て、それをまとめて「散乱行列」として表す
・例えば、森と水面をPolSARで見るとした場合に、水面は電波をきれいに反射させるので、戻ってくる信号は強いけれど位相が変わらない一方、森では電波が木の枝や葉っぱにぶつかって散らばりながら戻ってくるので、信号が弱くなり、戻ってくるタイミング(位相)も少しずつズレる
◾️先行研究の課題
①PolSARデータの複素数性の取り扱いの限界
・ 従来の畳み込みニューラルネットワーク(CNN)や機械学習手法は、Polarimetric Synthetic Aperture Radar(PolSAR)データを分類する際、複素数を実数に投影してから処理を行っていた
・具体的には、PolSARデータには位相と振幅の情報が含まれており、この位相情報を捨ててしまうことで、重要な物理的特徴が失われるという問題があった
②高次元データの次元削減と特徴抽出の限界
・PolSARデータは、たくさんの次元にまたがるデータを持っており、地表の物体を正確に分類するには手動で特徴を選び出す必要があった
・例えば、大量のデータを「物体の輪郭」や「色」に分けて、それぞれを専門家が手作業で整理するような作業を要していた
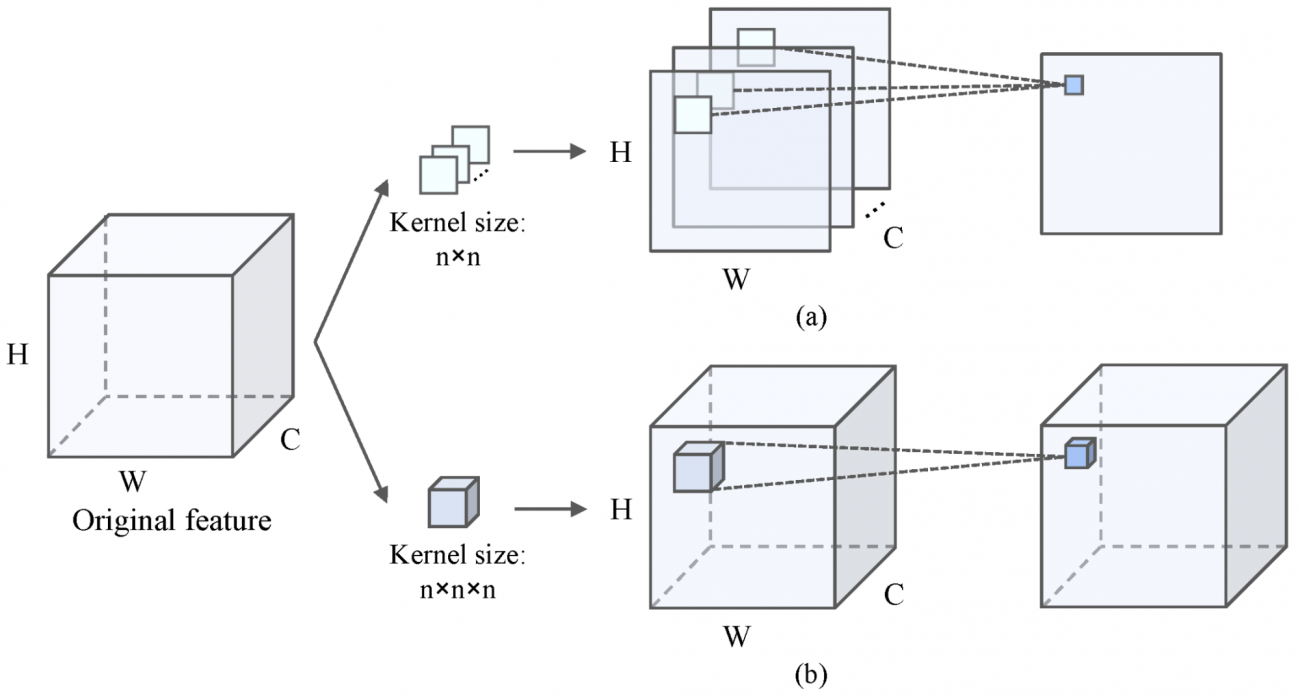
③2D-CNNおよび3D-CNNの計算コストと過学習
・3D CNNは物体の立体的な特徴も含めて捉えることができるものの、膨大な量の計算が必要になり、時間や計算リソースが大量に消費されてしまう
・また、訓練データが少ない場合には、モデルが過学習(してしまい、別のデータに対してうまく機能しなくなることもある
◾️本研究のアプローチ
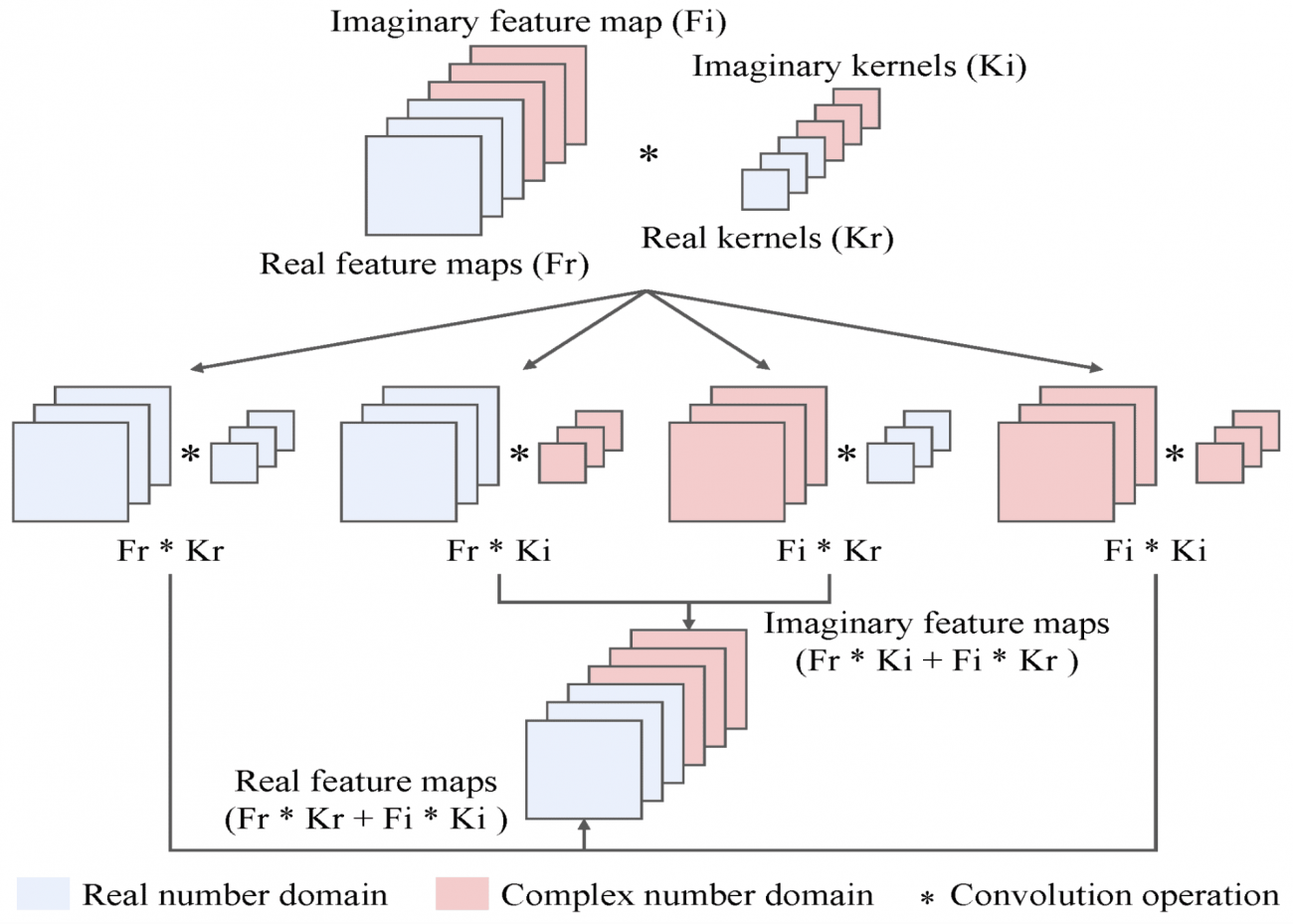
①複素数値CNN(CV-CNN)
・PolSARデータの複素数性をそのまま扱うCNNを導入
・上記により、位相情報を維持したままデータを処理することが可能となる
・具体的には、複素畳み込み層を利用して、複素数の実部と虚部の両方を同時に学習する
②2Dと3Dの良いところを組み合わせたハイブリッドCNN
・2D-CNNは主に空間的特徴を捉えるのに適しており、3D-CNNはチャネル間の依存関係を学習するのに優れている
・次元削減を行いながらも、PolSARデータの重要な空間的特徴とチャネル間の関係を自動的に抽出する
・具体的には、2D-CNNで局所的な特徴をまず捉え、その後、3D-CNNでさらに立体的な特徴やチャネル依存を補完する
③アテンションメカニズムによる特徴の選別
・複素数の実部と虚部に対してチャネルごとに異なる重みを計算し、重要なチャネルや空間的特徴を強調する
・上記により、3D-CNNの膨大な計算コストを削減し、過学習のリスクを軽減する
【議論の内容・結果は?】
・提案手法(CV-2D/3D-CNN-AM)はすべてのカテゴリに対して優れた認識能力を発揮した
・OA (Overall Accuracy)は、提案手法は99.78%と、他の手法よりも高い精度を達成し、CV-2D-CNNと比較しても3.05%の向上が見られた
・AA (Average Accuracy)では、提案手法は9.55%で他手法と比較して大幅に向上、特にCV-2D-CNNに対して7.78%の改善が見られた
・提案手法のKappa値は99.76で、これも他の手法よりも高い値を示しており、安定した分類性能を示している
・CV-2D/3D-CNN-AMは、CV-3D-CNNと比較して訓練時間を半分以下に抑えつつも、精度もわずかに向上させた(OAを98.81から99.78とわずかに上昇、訓練時間は、1303.64秒から480.24秒まで減少))
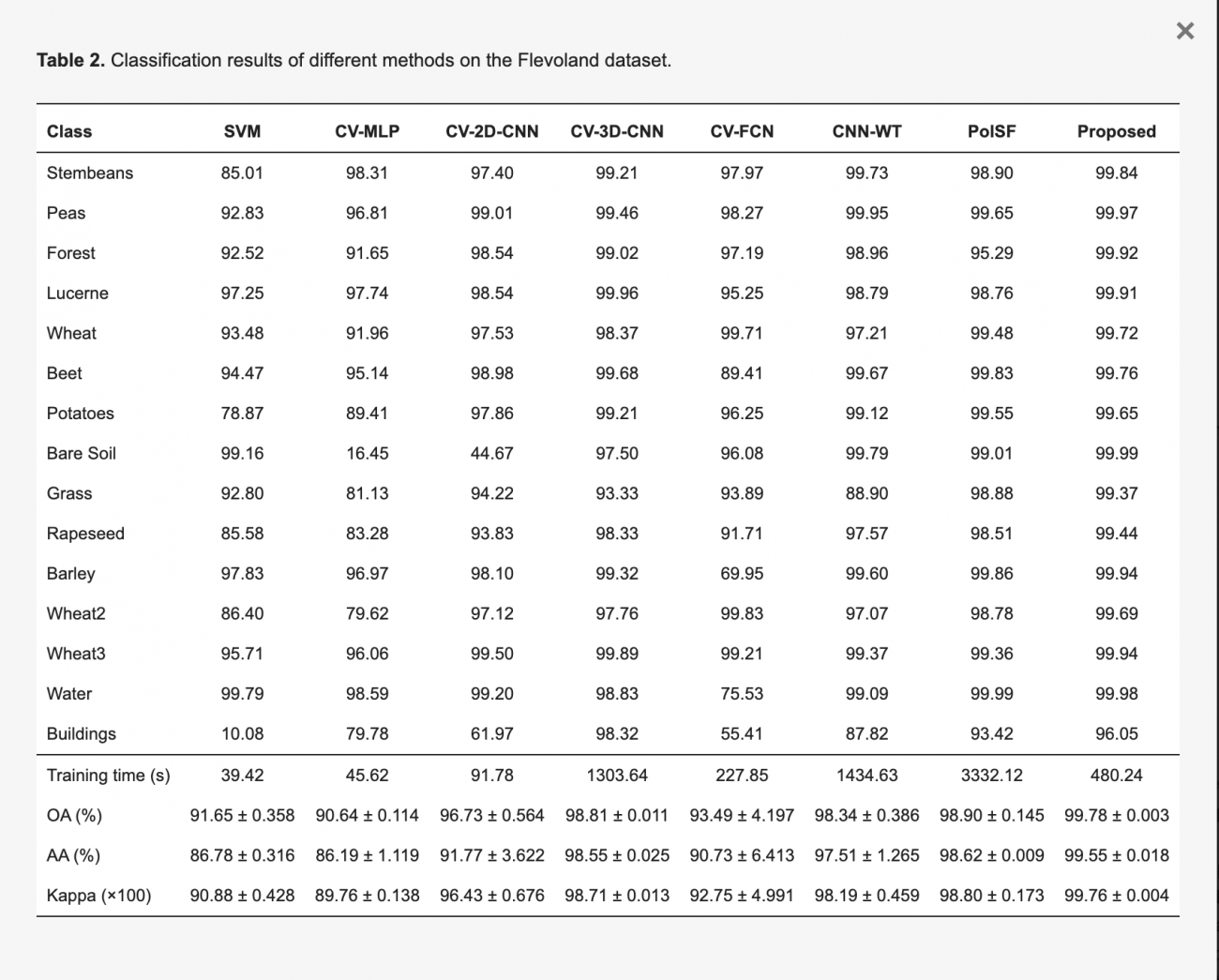
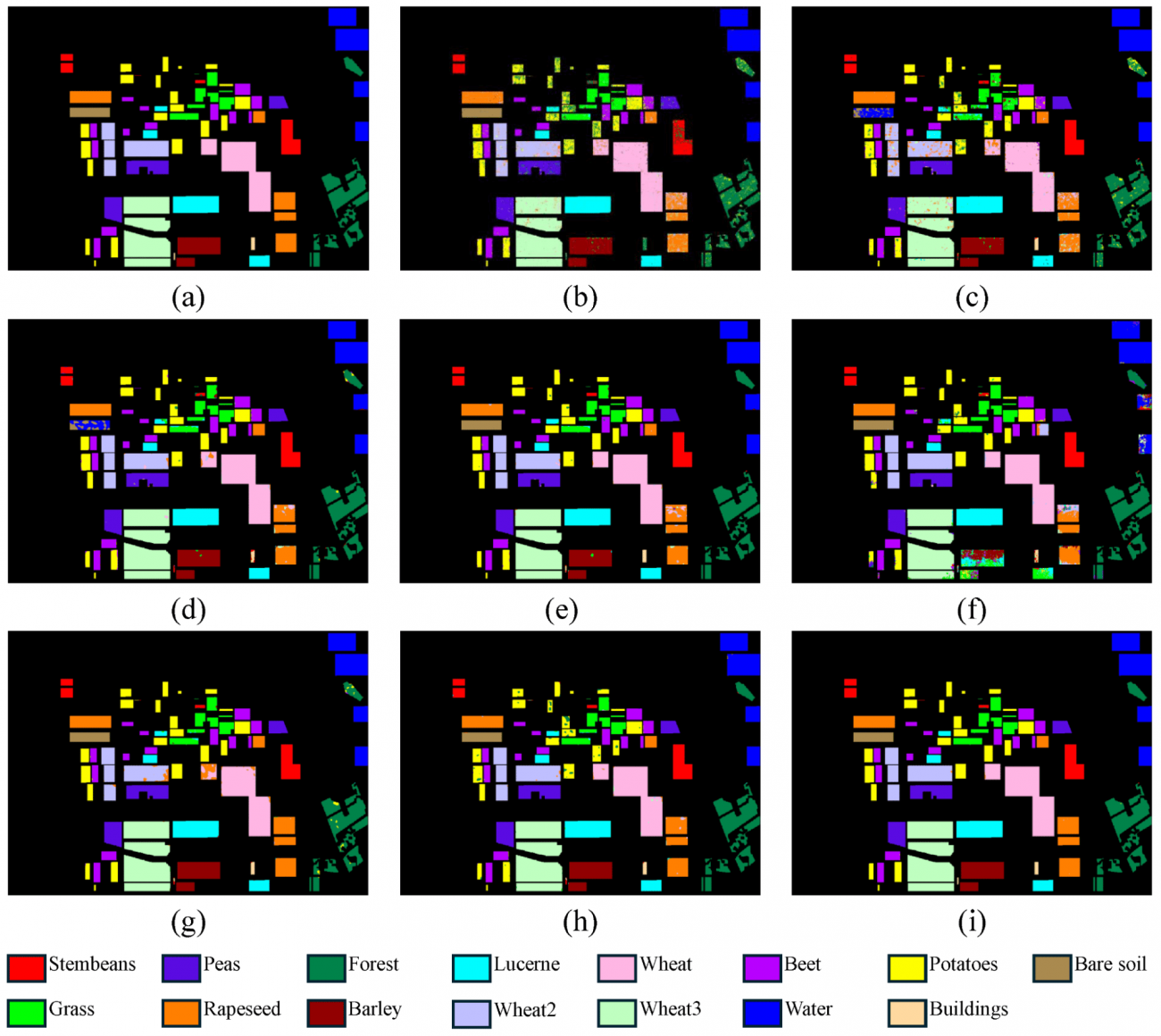
・なお、提案手法であるCV-2D/3D-CNN-AMは、他のデータセット(サンフランシスコエリアなど)でも、小さく地理的に散在するエリアを効率的に分類する優れた能力を示しており、他のアプローチと比較してすべてのカテゴリで精度が高かった
#偏波 #PolSAR #位相 #振幅 #散乱行列 #CNN #CV-CNN #3D-CNN #アテンションメカニズム #SVM #CV-MLP #CV-2D-CNN #CV-3D-CNN #CV-FCN #CNN-WT #PoISF
以上、2024年8月に公開された論文をピックアップして紹介しました。
皆様の業務や趣味を考えた時に、ピンとくる衛星データ利活用に関する話題はありましたか?
来月以降も「#MonthlySatDataNews」を続けていきますので、お楽しみに! 9月はすでに複数名の方に投稿いただいておりました。ありがとうございます!
