加速する「オープン化」と「実用化」の波、衛星データ×機械学習でできること
衛星データと機械学習の相性はどうなのか、衛星データには一体どのような面白さがあるのかなど実際のコンテストプロジェクトの裏側に迫るべく、今回は運営の株式会社SIGNATEの代表取締役社長の齊藤さんと一般財団法人リモート・センシング技術センターソリューション事業第二部部長の向井田さんにインタビューし、その対談の様子をお届けします。

衛星データプラットフォームTellusでは、第1回の土砂崩れ検出や第2回の船舶検出など衛星データを使った機械学習解析コンテストに取り組んでいます。
衛星データと機械学習の相性はどうなのか、衛星データには一体どのような面白さがあるのかなど実際のコンテストプロジェクトの裏側に迫るべく、今回は運営の株式会社SIGNATEの代表取締役社長の齊藤さんと一般財団法人リモート・センシング技術センターソリューション事業第二部部長の向井田さんにインタビューし、その対談の様子をお届けします。
機械学習と宇宙業界の近年の動きとトレンド
— 齊藤さんがSIGNATEを立ち上げるに至った経緯は何ですか?
齊藤氏:SIGNATEを立ち上げた理由としては2つあって、1つ目は、ビックデータやAI人材不足の解消です。始めたころからビックデータやAI人材が足りないと思っていたので、人材を集めたり育成したりしています。
2つ目は、AIや機械学習モデルの性能評価の仕組みの構築です。公開でコンテストを開催することによりクオリティの可視化を行うことで、プロダクトの第3次評価ができるという客観性にこだわっています。
現状、どこの機械学習モデルが優秀かというのを客観的に評価できる仕組みがないですよね。でも、色んな製品にAIモデルが搭載される時代が早々に来ると思っているので、そのときに性能評価できる仕組みを整えておきたいと考えています。

— 機械学習における最近5~10年のトレンドやSIGNATEを運営するなかで変わってきたことはありますか?
齊藤氏:SIGNATEの会員数は指数関数的に伸びていて、去年は8000人から1万6000人になり、2倍増えました。理由としては、ここ直近で「ディープラーニング(深層学習)」のテーマがトレンドとなったこともあり、業界の関心が高まっておりプレイヤーが徐々に増えたという点です。
深層学習のテーマでは、パフォーマンスが出る領域でアプリケーションを探索するので、中でも衛星画像のテーマのように画像を使ったタスクが多いです。
さらにディープラーニングにおけるここ3年のトレンドとしては、前までは新しいモデルが論文で紹介されていて色んなアプローチを使って切磋琢磨している状況でしたが、最近は代表的なアルゴリズムが決まってきていますね。
— 宇宙業界における最近5〜10年の流れはどうですか?変わってきたことや向井田さんが注目していることはありますか?
向井田氏:技術は5年間で進んだけれども、利用はそんなに進んでいないというのが業界の共通認識としてあると思います。そこは反省するところです、とはいっても、ITは物凄く進んだので、その恩恵を受けて効率や品質がよくなり、通信速度やデータを蓄積する機能や処理速度などはかなりスペックアップしました。
スペックアップすることによって、衛星を小型化できるようになってきています。ただ、小型化することで姿勢が安定しなくなってくるというように、新しい技術が入ることによって新しい課題が出てきます。どんどん課題が出て解決されて課題が出て解決されてというのが、5〜10年だったんじゃないかなと思いますね。

ただ、これに反して、我々のような衛星データを使って地球観測を行うリモートセンシング側がやっていることは、そんなに変わっていないんですよ。
結局カメラが高性能化しても、画質の評価指標や検査方法があまり変わっていないのと同じで、結局良い画像って何?という評価指標だったりその良い画像を使って何をするの?といった活用の部分もそんなに変わらないできている現状があります。
でも、ここ2〜3年で大きく成長して変わったのは、「簡単にデータを掘ることができるようになった」ところです。
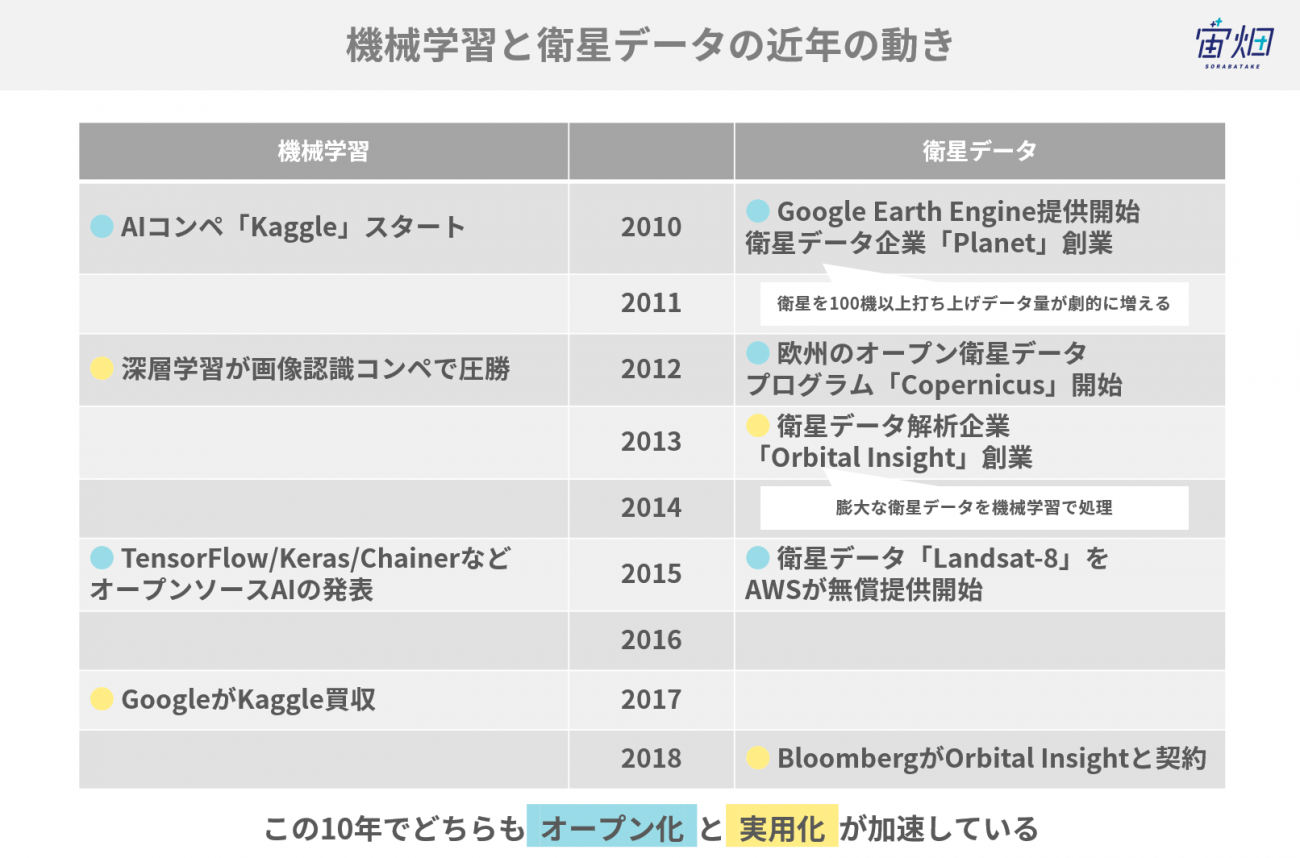
「どべしゃー」と増え続ける衛星データの実情と面白さ
— 「簡単にデータを掘ることができるようになった」というのは具体的にどういうことでしょうか?小型衛星が大量に増えたことにより膨大なデータの自動処理が可能になったということでしょうか?
向井田氏:もう少し細かく言うと、小型衛星のデータの増え方って急に”どべしゃー”って増えるじゃないですか。
観測頻度や観測範囲が上がって、時間軸的かつ2次元的に、急に密度が高く取れ始めるんですよ。ランドサット(※1)やデジタルグローブ(※2)、スポット(※3)などの衛星により観測された、画質や精度が担保されたデータが増え、それ以外にもスタートアップなどの小型衛星が増えたため、観測範囲が広がって使えるデータが一気に増えました。
衛星が増え続けている中で、さらに日々の観測頻度が増えているので密度が濃いデータが増えて、2次元的にも時間軸的にも増え、全体が持ち上がっていくんです。
● 画像自体が持つ情報が増えることで、深いデータにアクセスして意味を見い出せるようになったこと
● これから2次元的な広がりを持ちつつ、時間軸の方向においても増えていくこと
この2つが大きな転換期であり価値になっていくと思っています。
(※1)Landsat:アメリカ航空宇宙局 (NASA) の衛星
(※2)Digital Globe:人工衛星を活用したリモートセンシングを手がけるアメリカの企業
(※3)SPOT:フランスの宇宙機関CNESの衛星
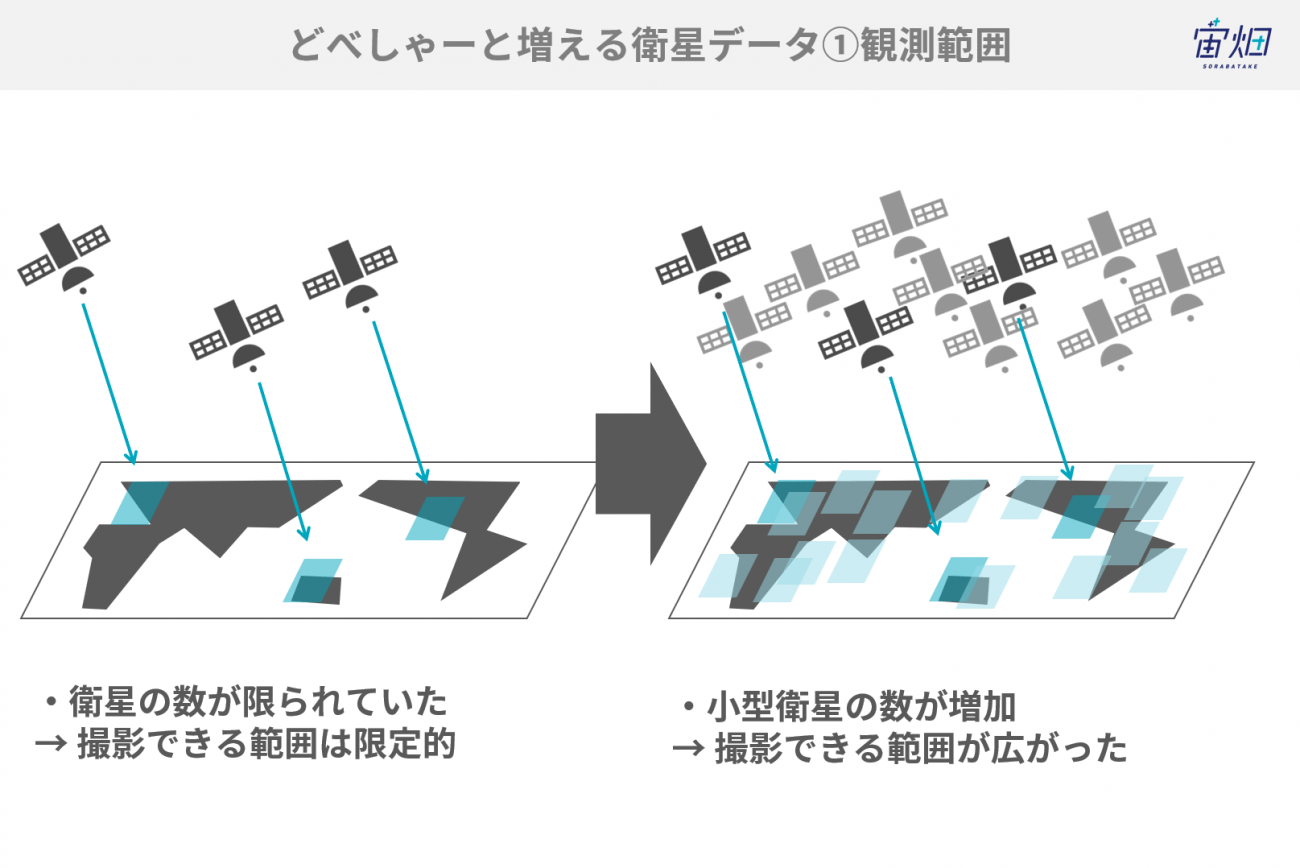
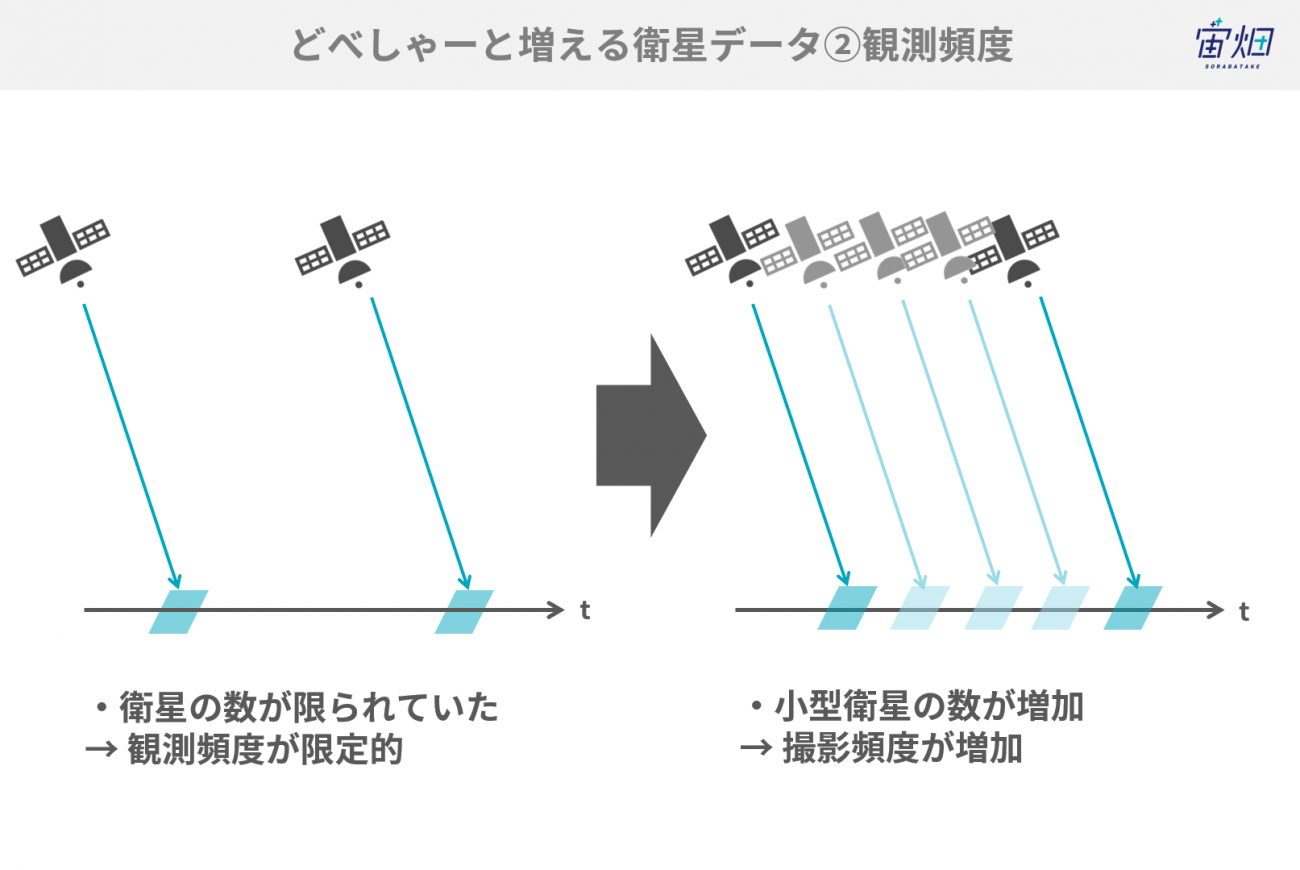
また、ローカルに蓄積して管理するのではなくクラウドストレージにちゃんと載ってAPIで一発で呼べるようになったということも大きいです。簡単なことだけど物凄く大きいことで、おそらくリモートセンシング業界にしてみれば、Google EarthやGoogle Mapが出たときと同じかそれ以上の驚異でした。ネガティブな意味ではなく、これができるようになったらできることが更に増えるよねという可能性に対する期待感、プラスの意味です。
データが増えて、それにアクセスするのが容易になったことがものすごく大きな出来事です。
実はプロフェッショナルな専門家のアプローチと機械学習のアプローチは同じだった?!
— 実際、衛星データ×機械学習の取り組みはやってみると大変でしたか? 衛星データならではの大変さやユニークさはありましたか?
齊藤氏:1番大変だったのは、「手軽に出てこない・扱えない」という部分ですね。当時はまだネットの世界に転がっているというようなオープンフリーな世界ではなかったので、データ調達やフォーマット設計などの準備が大変でした。そういった意味で、宇宙・衛星領域の特殊な知識がないとわからないので、向井田さんと一緒に取り組んだことで出来たことだと思っています。
— 1回目の土砂崩れ検出のコンテストを実施した際の率直な感想を教えてください。

宙畑メモ
2018年に行われた第1回「Tellus Satellite Challenge」では、電波を使って観測を行うSARデータを用いて、画像の中から土砂崩れの有無を判別するアルゴリズムの開発を競いました。
通常のカメラで撮ったような画像である光学画像とは異なり、SAR画像は人間が目で見ても容易ではなく、参加者にとっては難しい挑戦となりました。
齊藤氏:人間が見て判別できないということは、物理的に判別できる条件は情報量として揃っていないということになります。実際に推論する際に利用するのは、SARの衛星データを利用しますが、”地すべり”の正解データの定義をより正確にするために、正解ラベル付きの教師データは、SARの衛星データではなく、ドローンで撮影するなど人が撮影したGround Truth(※4)のデータを使っているんです。ということは、厳密に衛星から見えるという保証はなく、むしろ見えないので極めて難しいチャレンジでした。
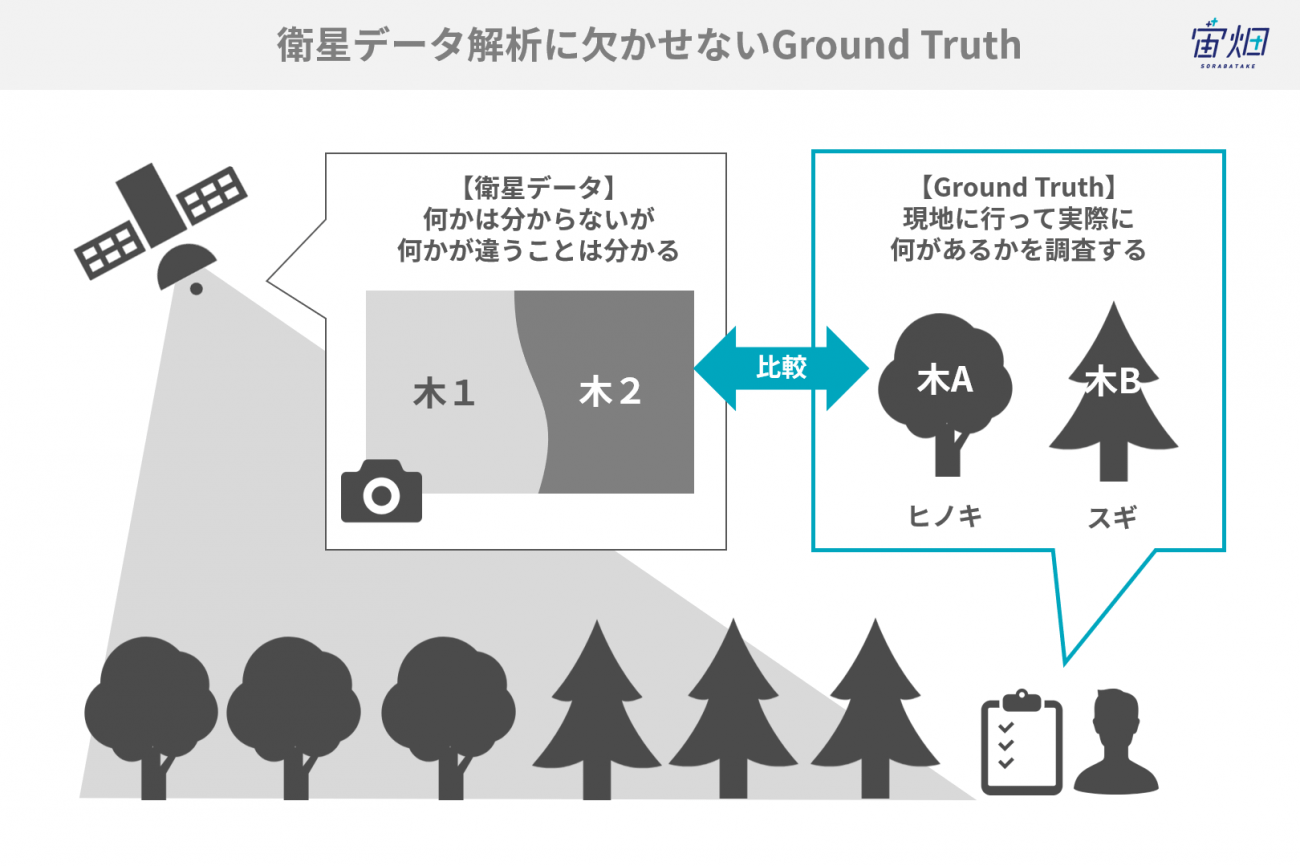
(※4) Ground Truth:リモートセンシングで得られる画像データから対象物を判読する場合に、その代表的な対象物の実際の地上のデータをいう。
齊藤氏:また、光学衛星の場合は目で見て山肌が崩れているのが分かるため、スナップショット(1枚の画像だけ)で領域を識別すればいいのですが、SARの衛星データ(※5)の場合、目で見ても分からないため地震前後の差分でディープラーニングをかけるという工夫が必要です。そのため、変化を見るためによくある物体検出とは違うテクニックが必要とされた部分も難しいタスクでした。
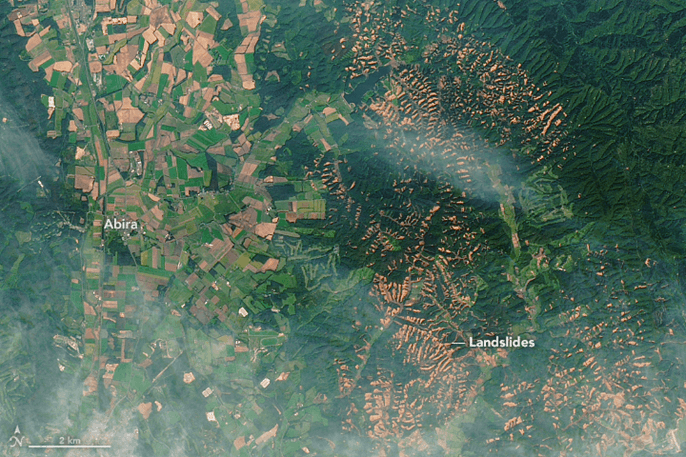

(※5)SARデータとは:https://sorabatake.jp/3364/
向井田氏:面白かったのは、結局人間と似たロジックで解いていたことです。コンテストで上位に入賞したアルゴリズムでも、引いて見てありそうなところとないところを大枠のエリアで識別して、細かい判読に入っていくという、普段自分たちが目視で行うのと同じようなアプローチをとっていました。
齊藤氏:入賞者が用いていた畳み込みニューラルネットワーク(CNN)は、周辺の情報をあわせて見ていくネットワークなので人間の感覚と少し近かったのかもしれないです。実際、コンテスト用の画像として提供したグリッドを超える巨大な地すべりもあり、与えたデータセットが少し細切れすぎたので、皆さん繋げて拡張した領域でみていました。
— モデルのパフォーマンス含め、コンテストの結果に対してはどう感じましたか?
向井田氏:元々教師データは、プロがSARから読み取った正解ではないので、おそらく良い精度は出ないんじゃないかと思っていました。
しかし、自分たちも実際目視で行う際には、新聞やWEBニュースなどあらゆる周辺の情報を集めて参考にしながらデータを見るので、全く別の独立したデータを教師データとして利用することもあるんです。蓋を開けてみたら、自分たちと似たアプローチをとっており、妥当な値だと思いました。
— 実際プロフェッショナルな専門家が目視で行うのとほぼ同レベルの精度だったのでしょうか?
向井田氏:条件が違うため、比較しようがないんですよね。条件というのは、例えば自分たちはSARデータのみを見て識別するとは限らないし、どれくらい時間が経ってからデータを与えられるかも違うからですね。
ただ、正答率と与えられた情報をとったときに高いか低いかという肌感覚で言えば、すごく妥当だと思います。
決して人間を超えたとは思わないけれども、やり方を解きほぐしていくと自分たちがやっているのとそんなに変わらないということもあり、自動でもここまでできるのかという納得感がありました。人に依存しなくなるため、人の手を介さなくもできるようになるというのは大きなアドバンテージになると思います。
ただ、課題としては、今回実施したのは熊本の地震だったので、北海道など場所を変えた際に果たして同じアルゴリズムで同等の精度が出るのかというところですね。
齊藤氏:山の傾斜など地理的な特徴もあるんですが、教師データを増やせば精度は高くなる可能性があるので、人間だと抱えきれないほどの特徴量を覚えさせることができるかもしれないというのがポテンシャルとしてありますね。今回はPoCで熊本のケースでしたが、世界中のデータで行えばいつか人間を越えるときがくると思います。そういったところに機械学習の期待があります。
物理学的アプローチから統計学的アプローチへと少しずつ裾野を広げる宇宙業界
— 過去のコンテストを踏まえて、今後どういったテーマでの実施を考えていますか?
齊藤氏:私の視点でいくと、Tellusの意義にも繋がるので、産業応用的なものがしたいです。民間企業が衛星データを利用したい際に、AIの技術に関するリテラシーは必ずしも高くないと思うので、Tellusのデータセットと具体的な産業事例に関連するテーマのコンテストを提供するのは重要かなと思います。そこから衛星データとAI技術で何ができるかを理解し、様々なビジネスへ応用されていくことが期待されます。
あと実際コンテストの設計というのは、やりたいことと出来ることの折り合いをつけています。教師データがあるか、Ground Truthを手に入れられるかといった制約も1つの条件になってくると思います。
向井田氏:リモートセンシングの視点では、高解像度、レーダーだけじゃないんだよというところをアピールしていきたいので、梅雨前線を自動で引くとか、降雨レーダーなどを使ってゲリラ豪雨を見つけるなど目で見て分からないような雲や雨も面白いかなと思います。
最近よく色々なところで取り上げられる船とか車とか石油タンクなど(※)にこだわる必要はないかなと思っています。
むしろ自然現象を自動検出したり予測したりというほうが、ビジネスに結びつくケースがあるのではないかと思います。
自然現象を自動検出したり予測したりという部分は、実は今まで地球物理ではご法度だったんです。統計だけではなく、仮説とセオリーのもとに実際現地に行ってGround Truthを手に入れて検証しモデル化するのが研究だと言われていました。
※アメリカの宇宙ベンチャーOrbital Insightでは石油タンクの蓋が貯蓄量に合わせて上下することを利用して、衛星から石油の貯蔵量を算出。先物取引などに役立つデータとなっています。
齊藤氏:それは他の業界や産業でもよくありますね。物理モデルのほうが統計モデルより説明能力が高いので、物理学から導き出される方程式を解くような理論の方が正であるという考えです。
しかし、実際、統計学的アプローチはモデルがブラックボックスだとしても、過去のビッグデータが支持する予測値は極めて正確であり、反対に物理学的アプローチは解釈が容易ではあるけれども予測値は不正確であることが多々あります。そのため敵対する概念というよりは、協調していく概念だと思います。
業界の専門家(つまり物理モデル派)からも機械学習も含めたデータにもとづく統計学的アプローチに可能性を感じているし、機械学習業界では、ブラックボックスになっている部分を解釈できるようにする技術を開発する必要があるし、お互い手を取りあって歩み寄っている印象です。
ブラックボックスでも産業に有利ですというのは一部事実としてあります。理解したいという探究心を突き詰める研究ではなく、わからなくても精度が高ければお金になるのがビジネスなので、それは否定できないと思います。
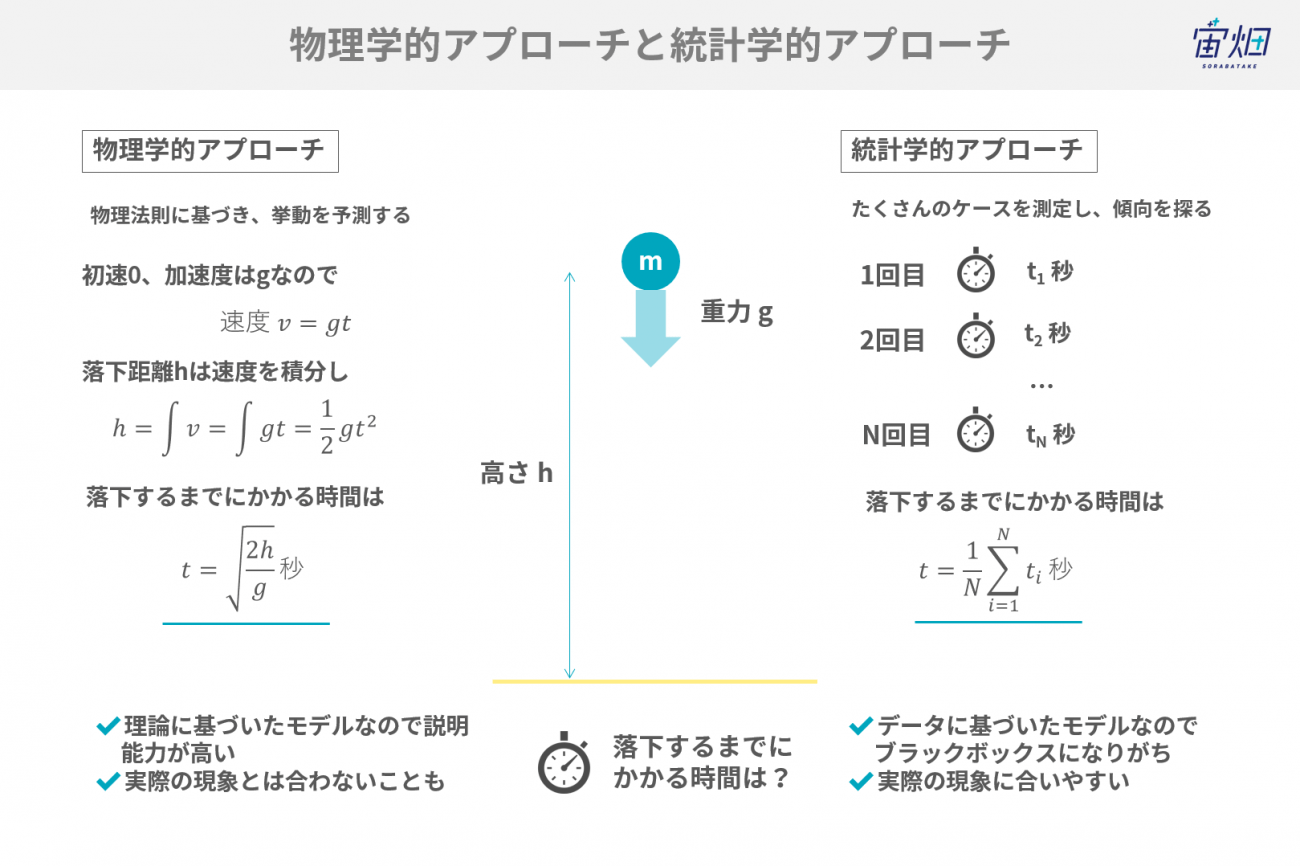
— 統計学的アプローチにおける課題はありますか?
齊藤氏:説明能力や制御の問題はありますね。例えば、制御システムと連携している場合に、機械学習を利用すると、コントローラブルなものではないときもあります。
理論ベースであれば、ある程度見通しが立ち、上限を設けるなど事前に対処できる(防げる)ことも、統計ベースだと予測は正しくても何故そうなっているかがわからない場合もあるので、異常なインプットがきたときに、異常な予測を出してしまうときがあります。
これだと運用の際に困るので、使うシーンによって理論と統計の塩梅をどうするかなどを考える必要はあります。
向井田氏:関連する話だと、衛星データや自分たちが撮ってきたデータを解析する場合、過去10年分のデータを統計的に解析した際に、100年に1度のイベントを再現できるのかという問題もありますね。
100年に1度だったとしても、もし異常に暑い夏があったらそれをパラメータに入れて再学習すれば良いのですが、過去の情報を学習して予測するため、過去にその異常に暑い夏がなければ、予測することは出来ないです。
齊藤氏:どうしても過去に観測していない事象というのは、今の教師あり学習では難しいですね。教師なしの強化学習ベースの場合も、ルールをきちんと記述してあげる必要があるので、将棋や囲碁など明確なタスクなら実現できるのですが、自然現象は複雑すぎて難しいと思います。
向井田氏:過去の情報が少ないイベントを予測するのは難しいので、万能ではないと思います。
齊藤氏:まずは、定常的に観測できるタスクを自動処理するのがいいと思います。
データを増やしていきたいですね。

機械学習と衛星データの相性
— 衛星データにおいて、機械学習を使う際にあると嬉しい教師データはどんなデータですか?
齊藤氏:アプリケーションを考えると衛星データを解析する際に手がかりとなる、何が起きているかわかる地上のデータがほしいです。人間が目視で観測できる家とか車とかメタな意味付けをされた情報ですね。それを大量にもっていると、Tellusの差別化に繋がると思います。
向井田氏:前から言っていることではありますが、時間と空間が示されていないと正解と突き合わせることができないので、きれいに取れた画像を繋ぎ合わせたベースマップではなく、衛星で撮った時間が分かっている1枚ずつの画像(シーンデータ)がほしいです。
— データサイエンティストの方にとって、人気なコンテストはどのようなものですか?衛星データは機械学習と相性は良いのでしょうか?
齊藤氏:参加者人数が多いことをもって人気とするのであれば、初心者もエントリーしやすくなるため、簡単で身近なタスクがいいです。ファイルサイズが軽いなどエンジニアリング的にも簡単で実装が楽なものは手が出しやすいです。
衛星データのように画像形式でディープラーニングのタスクだと、ディープラーニングを組んでみたいという方は多いので、チュートリアルを公開するなど、エントリーしやすいような施策を打っていくとより集まると思います。
Tellusの前回のコンテストでは、3分の1は海外の方でしたよね。AIやデータサイエンスといった分野は国境関係ないので同じようなレベルで戦えますね。衛星データ自体も国内外関係なく扱えますしね。
向井田氏:それを踏まえると、衛星データとディープラーニングでコンテストをするのは、相性がいいですよね。
齊藤氏:ネット空間で、衛星で、AIで、コンテストで、ということで、国を選ばず誰でもでき、多くの方々の関心を集めることができるので良いと思います。
インタビューを終えて
機械学習側では、深層学習の台頭により、特に画像認識における精度が向上し業界への注目が集まり、TensorFlowなどのフレームワークがオープンソースで公開されたことにより誰でも手軽に開発することができるようになりました。それに伴い、KaggleやSIGNATEのようなコンテストも盛り上がり、結果的にかなり技術向上し、実用化が進んでいます。
宇宙業界側では、衛星データのオープンフリー化や衛星の小型化により安価に衛星を作ることができ2次元的にも時間軸的にも取得できるデータ量の増加の流れがあります。
さらに、今まで実際に現地に行って検証するというようなご法度だった分野ですが、機械学習など統計学的アプローチが注目を集め、使っていこうという流れがあります。
機械学習側の開発基盤の強化と衛星データ取得の容易化・統計学的アプローチへの挑戦のタイミングが重なり合った今、衛星データ解析領域は少しずつ進歩しています。
時系列データのように時間軸方向に増加するデータはよくありますが、観測範囲が広がって2次元的に増加するデータというのは中々なく、画像はディープラーニングで解くのに相性が良いため、もっと多くの方に扱ってみてほしい面白いデータだと感じました。
Tellusの活動を通して、宇宙業界に限らず、様々な業界において衛星データの活用が広がっていった未来が楽しみです。
「Tellus」で衛星データ×機械学習を始めよう!
衛星データプラットフォーム「Tellus」では、オープンフリー化した衛星データを使って様々なデータ解析を行う開発環境を無料で提供しています。
開発環境はJupyter Notebookに対応しており、Tellusに搭載されている衛星データをはじめとする様々なデータをAPIで呼び出し、手軽に機械学習を実行することができます。
【ゼロからのTellusの使い方】Tellusの開発環境でAPI引っ張ってみた
【ゼロからのTellusの使い方】Jupyter NotebookでAVNIR-2/ALOSの光学画像から緑地割合算出
【ゼロからのTellusの使い方】Jupyter Notebookで「つばめ」(SLATS)による高解像度画像を取得する
他にも、【ゼロからのTellusの使い方】シリーズでTellusの使い方について紹介しています。
また、衛星データについてもっと深く知りたい方は、以下の解説記事を合わせてご覧ください!
