【2024年7月】衛星データ利活用に関する論文とニュースをピックアップ!
2024年7月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
宙畑の新連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
実は、本記事を制作するために、これは!と思った論文やニュースをTwitter上で「#MonthlySatDataNews」をつけて備忘録として宙畑編集部メンバーが投稿していました。宙畑読者のみなさまも是非ご参加いただけますと幸いです。
2024年7月の「#MonthlySatDataNews」を投稿いただいたのはこの方でした!
Big mobility data reveals hyperlocal air pollution exposure disparities in the Bronx, New York #MonthlySatDataNews
個人の移動データと大気汚染データを組み合わせ、PM2.5曝露の格差を調査。特にヒスパニック系低所得地域が深刻な影響を受けてそうとのこと https://t.co/Z5fabBoOzo
— たなこう (@octobersky_031) July 29, 2024
それではさっそく2024年7月の論文を紹介します。
Transformer-based land use and land cover classification with explainability using satellite imagery
【どういう論文?】
・本論文は、計算コストが課題となるトランスフォーマーモデルにおいて、効率良く学習を行うための転移学習とファインチューニングの戦略を適用し、リソースの使用を最適化しながら、土地利用および土地被覆(LULC)分類を高い精度で行う手法を提案する
・加えて、解釈可能なAI技術(XAI)を組み込むことで、モデルの判断根拠を可視化し、モデルの信頼性を向上させることに取り組む
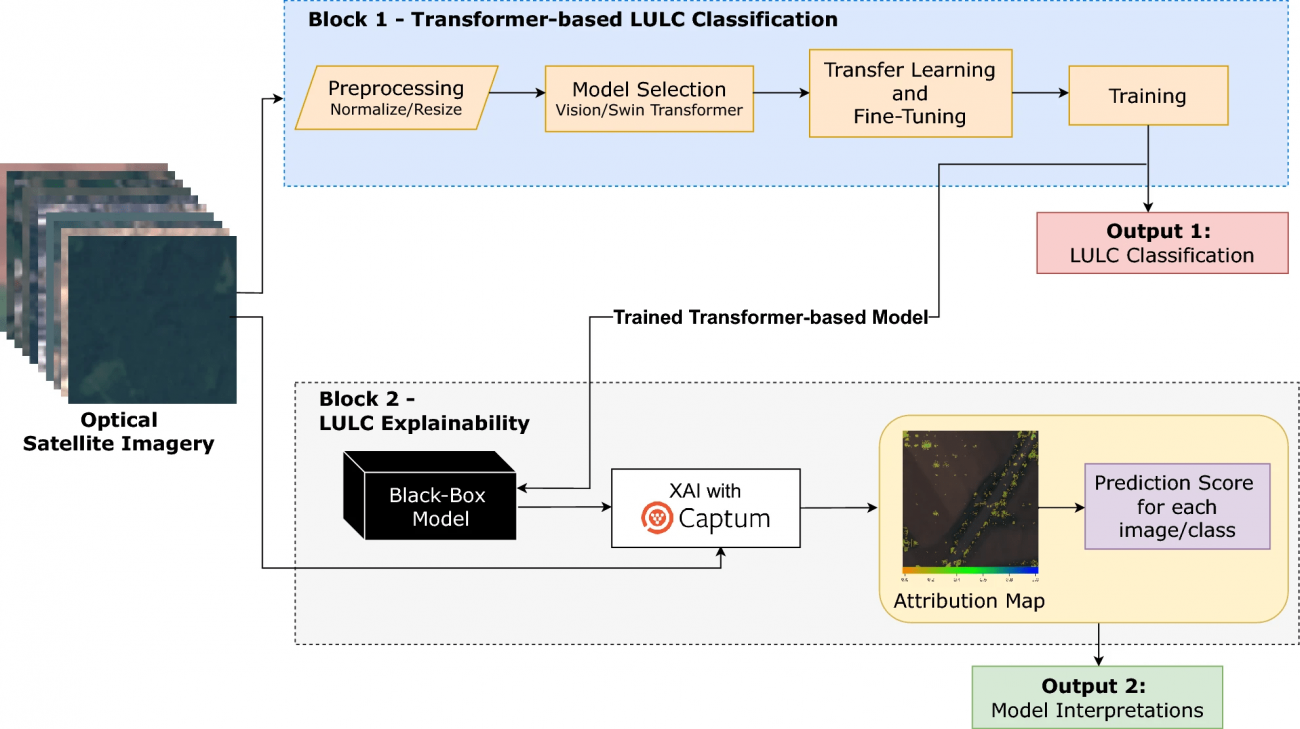
【技術や方法のポイントはどこ?】
◾️検証モデル:トランスフォーマーベースモデル
①Vision Transformer-Base (ViT-Base) & Vision Transformer-Large (ViT-Large)
・画像を小さな領域ごとに順番に見ていく(画像の離れた部分の関係性を捉えることが難しい)CNNベースのモデルと比較して、画像全体を一度に見て、すべての部分の関係性を同時に考慮することができるアーキテクチャである
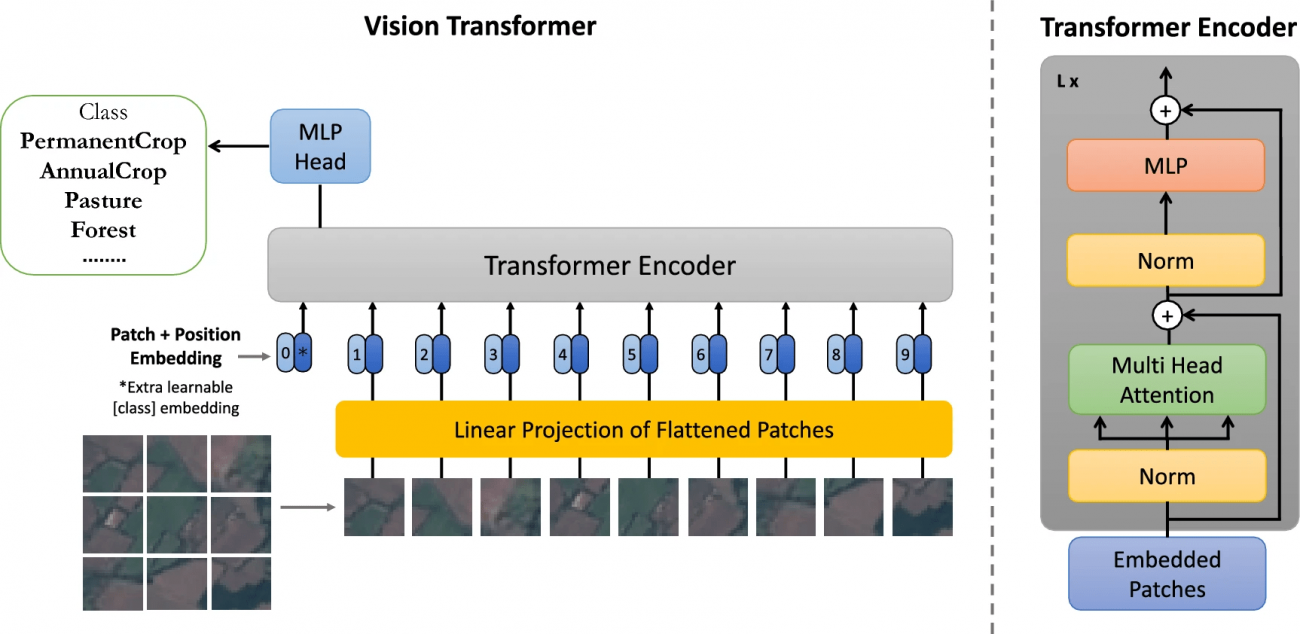
②Swin Transformer-Small & Swin Transformer-Large
・階層的なウィンドウベースのアプローチを採用し、局所的および全体的な特徴の両方を捉える
・ViTのような他のトランスフォーマーモデルと比較して、より局所的な情報の処理に優れ、計算効率が高い
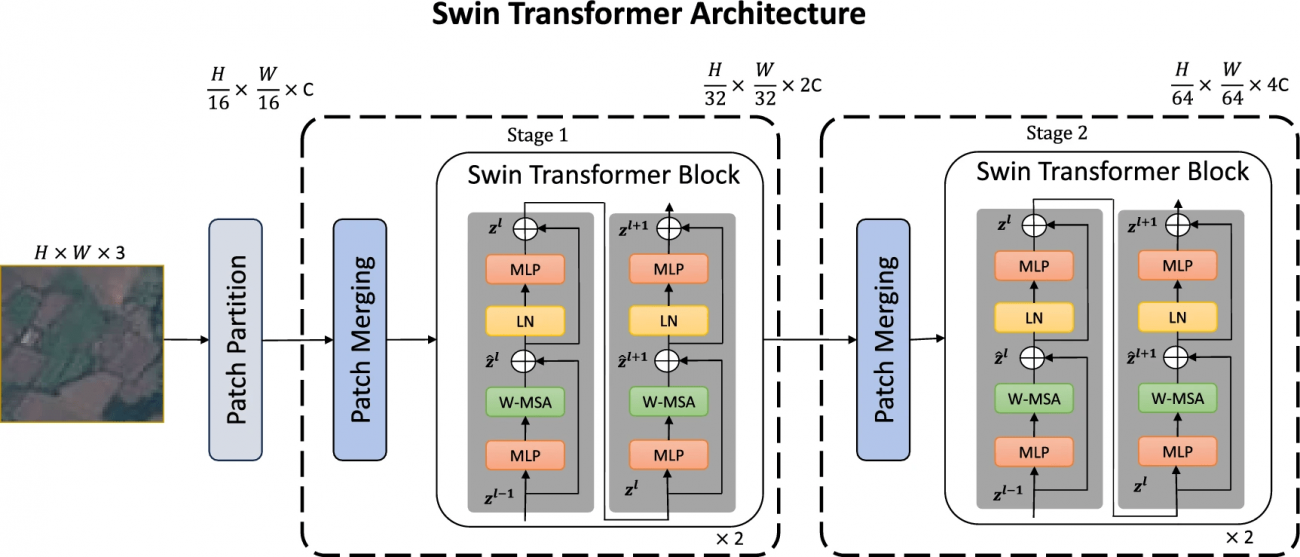
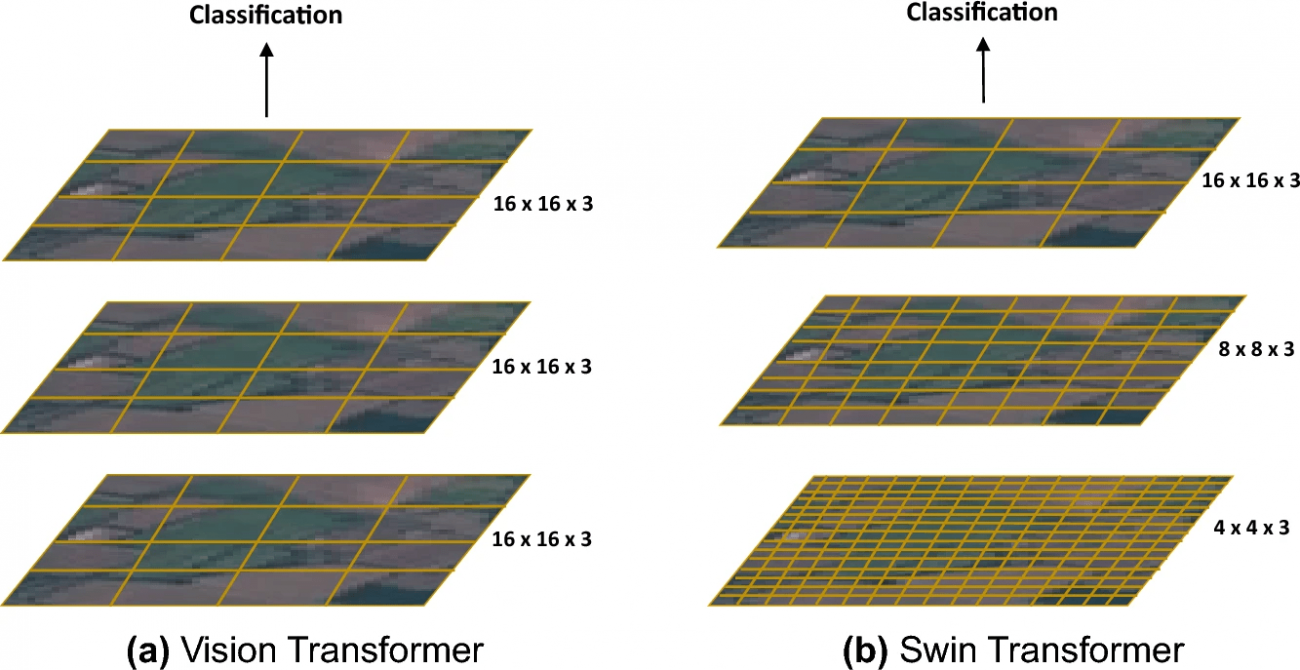
※Mehak Khan, Abdul Hanan, Meruyert Kenzhebay, Michele Gazzea, Reza Arghandeh(2024).Transformer-based land use and land cover classification with explainability using satellite imagery
③Data-efficient image Transformers-Base (DeiT-Base)
・トレーニングデータが少なくても効率的に学習できるように設計されたトランスフォーマーモデルである
◾️比較対象モデル:CNNベースモデル
①ResNet50 & ResNet101
・「残差学習」を用いて深いネットワークでも学習を安定させる
・InceptionやDenseNetと比較して、シンプルなスキップ接続が特徴である
②Inception V3
・異なるサイズのカーネルを同時に適用し、それらの出力を統合することで、異なるスケールの特徴を捉える
・DenseNetやResNetに比べ、複数の異なる処理を行う「マルチスケール処理」が特徴である
③DenseNet161
・各層からの出力を後続のすべての層の入力に接続することで特徴の再利用を促進し、効率的な学習を可能とする
・ResNetやInceptionと比べて、より強力な特徴伝達と再利用を行うことで、より少ないパラメータで高い性能を達成することができる
④GoogleNet
・Inceptionモジュールを用いて、異なるスケールの特徴を一度に捉えつつも、計算資源の効率的な使用を目指す
・初期のInceptionモデルであり、V3と比較するとやや単純な構造を持つが、マルチスケールの特徴抽出は共通している
◾️XAI手法
①Captum
[利点]
・ディープラーニングモデルの各レイヤーでの処理を可視化できる
・複雑なデータ構造を直接扱え、大規模データセットや複雑なモデル構造にも対応できる
・CNNだけでなく、Vision Transformer(ViT)のような非畳み込みアーキテクチャにも適用可能である
[課題]
・多層可視化が可能である一方、生成される帰属マップ(Attribution Maps)が複雑であり、特に非専門家にとって解釈が難しい場合がある
・視覚化された結果は非常に細かく、モデルがどのように決定を下しているかを理解するためには、追加の知識が必要となる場合がある
[LULC分類での利点]
・衛星画像の複雑な特徴(植生、都市構造など)を各レイヤーでどのように処理しているか理解できる
・大規模な衛星画像データセットに対しても効率的に解析を行える
②Grad-CAM
[利点]
・モデルが注目している画像の領域をヒートマップで表示する
・特定のクラス(例:森林、都市部)に対する注目領域を可視化できる
[課題]
・トランスフォーマーモデル(ViT、Swin Transformer)のような非畳み込みアーキテクチャには最適化されていない
[LULC分類での利点]
・利点: 都市部、農地、森林などの分類において、モデルがどの領域に注目しているかを直感的に理解できる
[LULC分類での課題]
・課題: 本研究で使用されているViTやSwin Transformerモデルには直接適用しにくい場合がある
◾️データセット
・利用するデータセットは以下の通りである

【議論の内容・結果は?】
◾️パフォーマンス比較
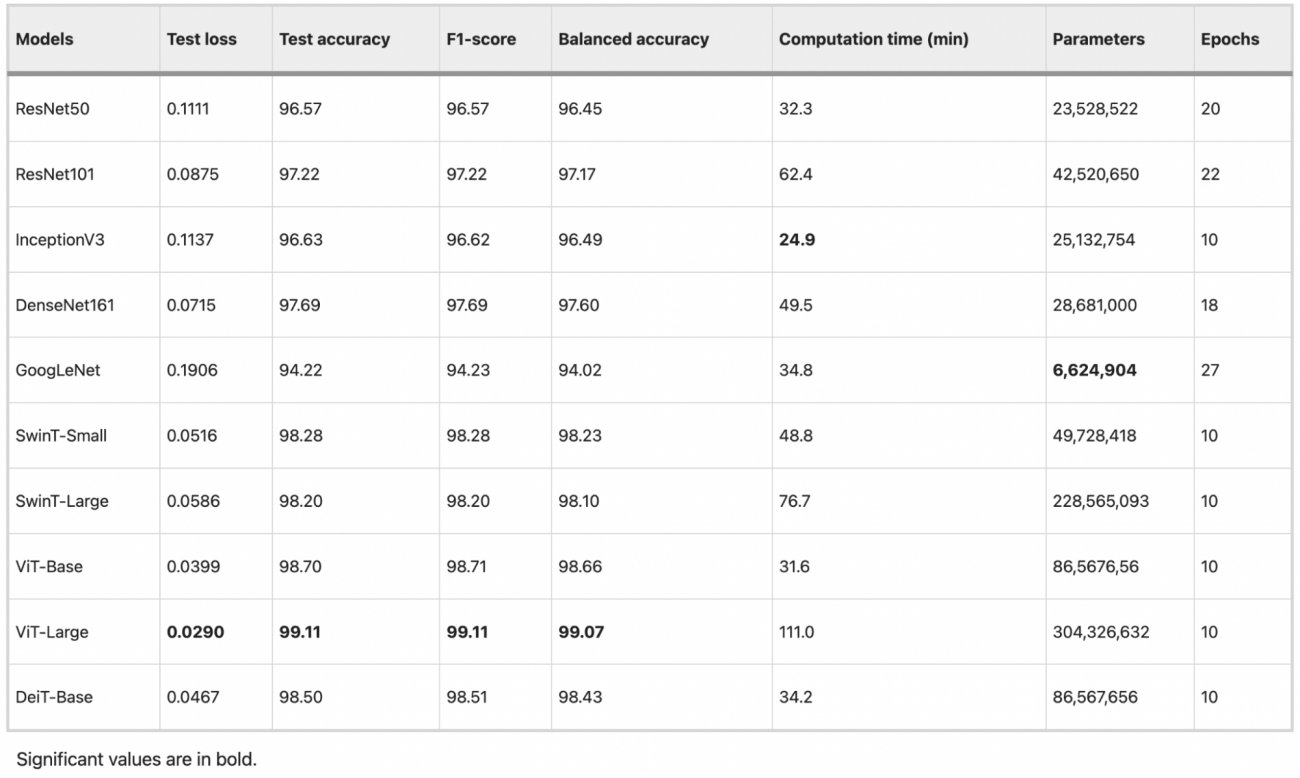
・ViT-Large は、テスト損失が最も低く (0.0290)、テスト精度が最も高く (99.11%)、画像分類タスクにおける優れた精度と堅牢性を示した
・SwinT-Smallも、特にバランス精度 (98.23%) と効率の点で優れたパフォーマンスを示し、ViT-Large (111.0分) と比較して計算時間が比較的短い (48.8分)
・非トランスフォーマー モデルの中では、DenseNet161がテスト精度 (97.69%) とバランス精度 (97.60%) の両方で高く、計算時間が比較的短かった(49.5 分)
※Mehak Khan, Abdul Hanan, Meruyert Kenzhebay, Michele Gazzea, Reza Arghandeh(2024).Transformer-based land use and land cover classification with explainability using satellite imagery
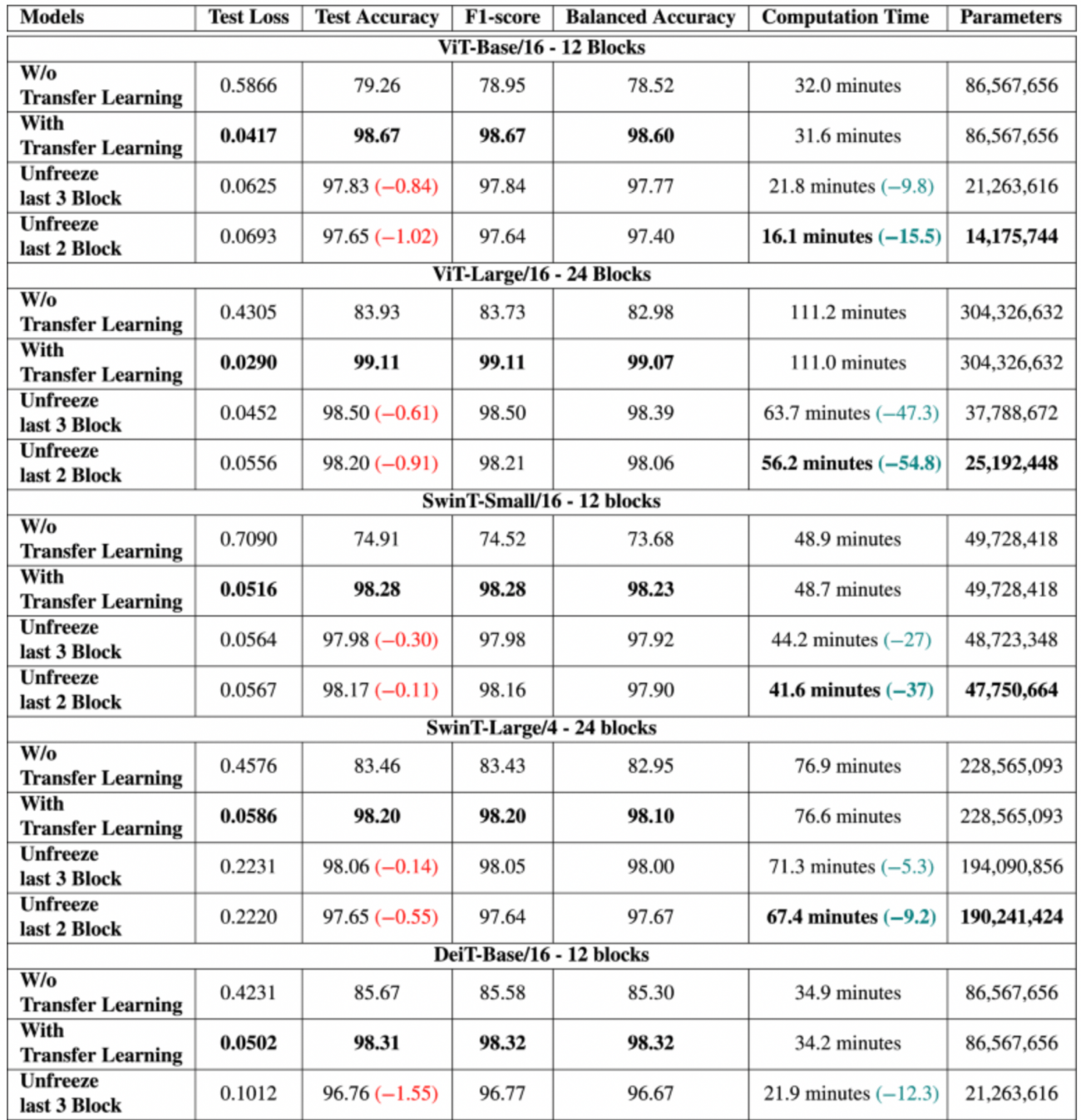
◾️転移学習とファインチューニング
①ViT-Baseモデル(12ブロック構成)
・テスト損失は、0.5866(転移学習前)から0.0417(転移学習後)へと約93% 減少した
・テスト精度は、79.26%から98.67%へと約24% 向上した
・F1スコアは、78.95から98.67 へと約25%改善された
・計算時間は、32.0分から31.6分へと1.25% 減少した
・ファインチューニング(最後の3ブロックのアンフリーズ)では、テスト精度が若干低下するが、計算効率が大幅に向上し、パラメータ数も減少している
・本手法によって、効率と精度のバランスを取ることができる
※トレーニング済みモデルを転移学習で利用する場合、すべてのレイヤーを再度学習する必要がないため、多くのレイヤーを「凍結(Freeze)」してそのまま利用することが一般的である
※しかし、特定のタスクに特化した調整を行うために、一部のレイヤーを「凍結解除(アンフリーズ)」し、その部分だけを再度学習させることがある
②ViT-Largeモデル(24ブロック構成)
・転移学習により、テスト精度とF1スコアが99%以上に達し、バランス精度も高水準を維持している
・ファインチューニングでは、性能のわずかな低下(精度やF1スコアの微減)が見られるものの、計算時間が約50%減少し、モデルの複雑さも減少している
③SwinT-Smallモデル(12ブロック構成)
・テスト損失は、0.7090から0.0516へと約93% 減少した
・テスト精度は、74.91%から98.28%へと約31%向上した
・F1スコアも同様に 74.52から98.28へと約32%改善された
・計算時間は、48.9分から48.7分へと0.4%減少した
・ファインチューニングによって、テスト精度は98.28%から97.98%へと0.30%減少したものの、計算時間は48.7分から44.2分へと約9%減少しており、リソースが限られた環境でのモデル展開に有利となっている
④SwinT-Largeモデル(24ブロック構成)
・
・転移学習を適用することで、テスト損失は0.4576から0.0586へと約87% 減少した
・テスト精度は、83.46%から98.20%へと約18%向上した
・F1スコアも83.43から98.20へと向上し、モデルがクラス不均衡なデータでも高い分類性能を示すことを示した
・ファインチューニングによって計算時間が大幅に短縮される一方で、精度の微減が見られるが、トレードオフとして許容できるレベルである
※Mehak Khan, Abdul Hanan, Meruyert Kenzhebay, Michele Gazzea, Reza Arghandeh(2024).Transformer-based land use and land cover classification with explainability using satellite imagery
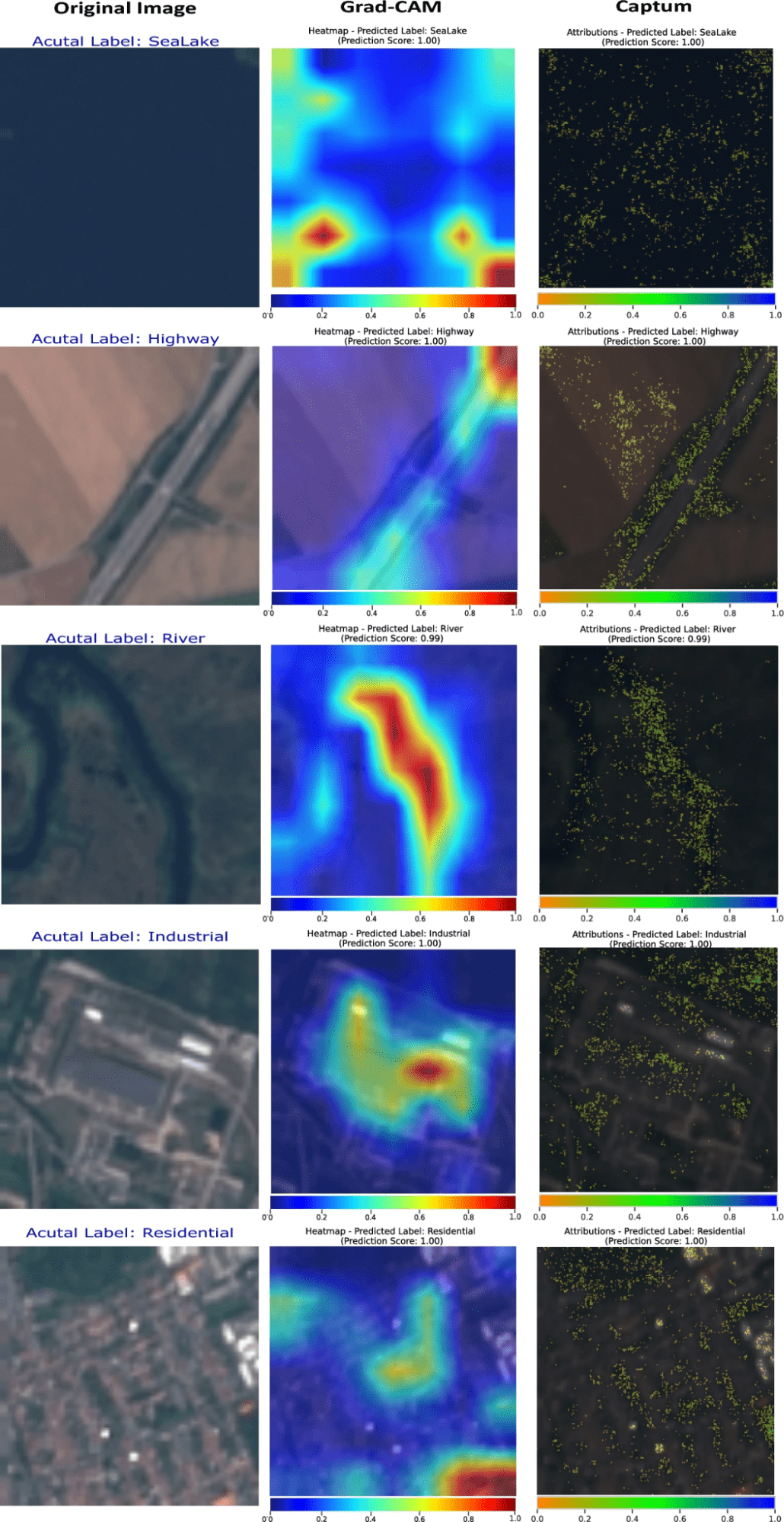
◾️Attribution Maps(XAI手法の適用結果)
①方法
・CaptumのIntegrated Gradientsを用いて、画像内の各ピクセルがどれだけ予測結果に貢献しているかを計算し、重要度に応じて色を変えて表示する
本方法は、モデルがどの特徴を重視しているかを示すことで、より透明性の高い解析が可能にする
②結果
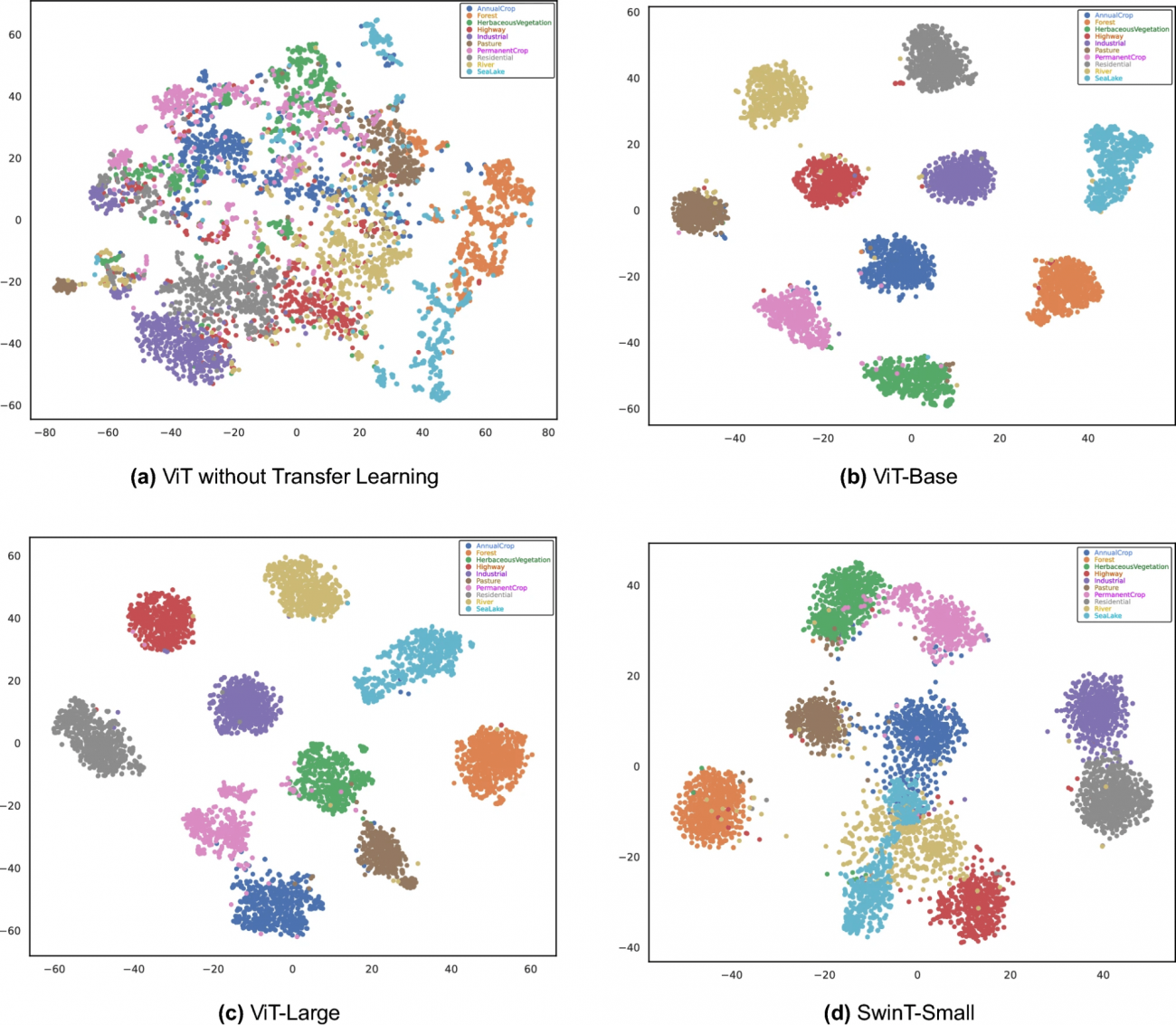
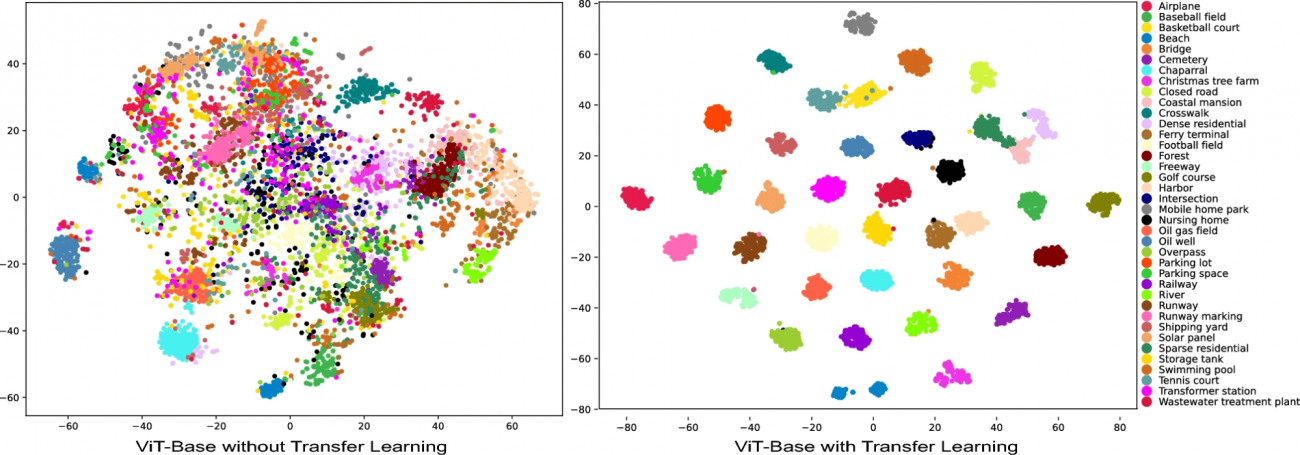
・ViT-Base、ViT-Large、SwinT-Smallの三つのアーキテクチャから派生した画像と、それに対する帰属マップを比較している
・本比較から、各モデルがどのように画像の特定のクラスを識別しているかの違いが明らかになる
・例えば、ViT-Largeはより広範囲の特徴を捉えることで、より複雑な景観を詳細に分析できる一方で、SwinT-Smallは特定の構造要素に焦点を当てている

・CaptumとGrad-CAMという二つの解釈可能性ツールの性能を比較し、特にDenseNet161モデルを用いた土地利用・土地被覆(LULC)分析の文脈で評価した
・CaptumのIntegrated Gradientsは特に重要なトップ5%の特徴を強調しており、モデルの判断に最も影響を与える領域に焦点を当てることで、解釈の明確さを向上させてる
・Grad-CAMは、特定のクラスに関連する勾配を最終的な畳み込み層の特徴マップに重み付けし、その結果をヒートマップとして表示している
#土地被覆 #LULC #DeiT-Base #ResNet #InceptionV3 #DenseNet #GoogleNet #CNN #VisionTranformer #SwinTransformer #t-SNE #ファインチューニング #転移学習 #Captum #Grad-CAM
An explainable embedded neural system for on-board ship detection from optical satellite imagery
【どういう論文?】
・本論文は、衛星や航空機からの光学画像を用いた自動船舶検出システムに関する研究であり、特にハードウェア指向のカスタマイズされた畳み込みニューラルネットワーク「HO-ShipNet手法」を提案する
【技術や方法のポイントはどこ?】
◾️データセット
・Kaggleのデータセット「Ships in Satellite Imagery」を使用する
・本データセットは、カリフォルニア州のサンフランシスコ湾およびサンペドロ湾エリアのPlanet衛星から収集された画像を含んでいる
・80×80×3ピクセル(赤、緑、青の3つのカラーチャネルを指す)のサイズで4000枚の画像がある

※「Ship」クラスには船の一部が写っている画像も含まれている
※Credit:Cosimo Ieracitano, Nadia Mammone, Fanny Spagnolo ,Fabio Frustaci, Stefania Perri, Pasquale Corsonello, Francesco C. Morabito(2024).An explainable embedded neural system for on-board ship detection from optical satellite imagery
◾️HO-ShipNet
①概要
・FPGA(Field-Programmable Gate Array)上で効率的に実装されるように設計されたカスタム畳み込みニューラルネットワーク(CNN)である
・本ネットワークは、船舶の存在有無を検出するために設計されており、特に限られたハードウェアリソースを最適に活用することを目的としている
②制約
・FPGAは、普通のコンピュータに比べて使用できるリソース(部品)が限られている
・特に、情報を処理するための「ルックアップテーブル(LUT)」や「フリップフロップ(FF)」、「ブロックRAM(BRAM)」、「デジタルシグナルプロセッサ(DSP)」という部品が限られている
・このため、AIモデルを作る際に、これらのリソースを無駄なく効率的に使う工夫が必要となる
③ハードウェア/ソフトウェア共同設計戦略
・最も計算量が多い部分をFPGAに任せている
・具体的には、画像から特徴を抽出する畳み込み層や、それを単純化するためのReLU層、そしてデータを圧縮する最大プーリング層はFPGAに埋め込んでいる
・上記により、同時に多くの計算を行うことができ、スピードが速く、電力もあまり消費せずに済む
・一方、全結合層やソフトマックス層といった、計算というよりも大量のデータを処理する部分は、FPGAではなくCPUで処理(実装)する
・上記により、FPGAのリソースを節約しながら、全体のシステムを効率的に運用できる
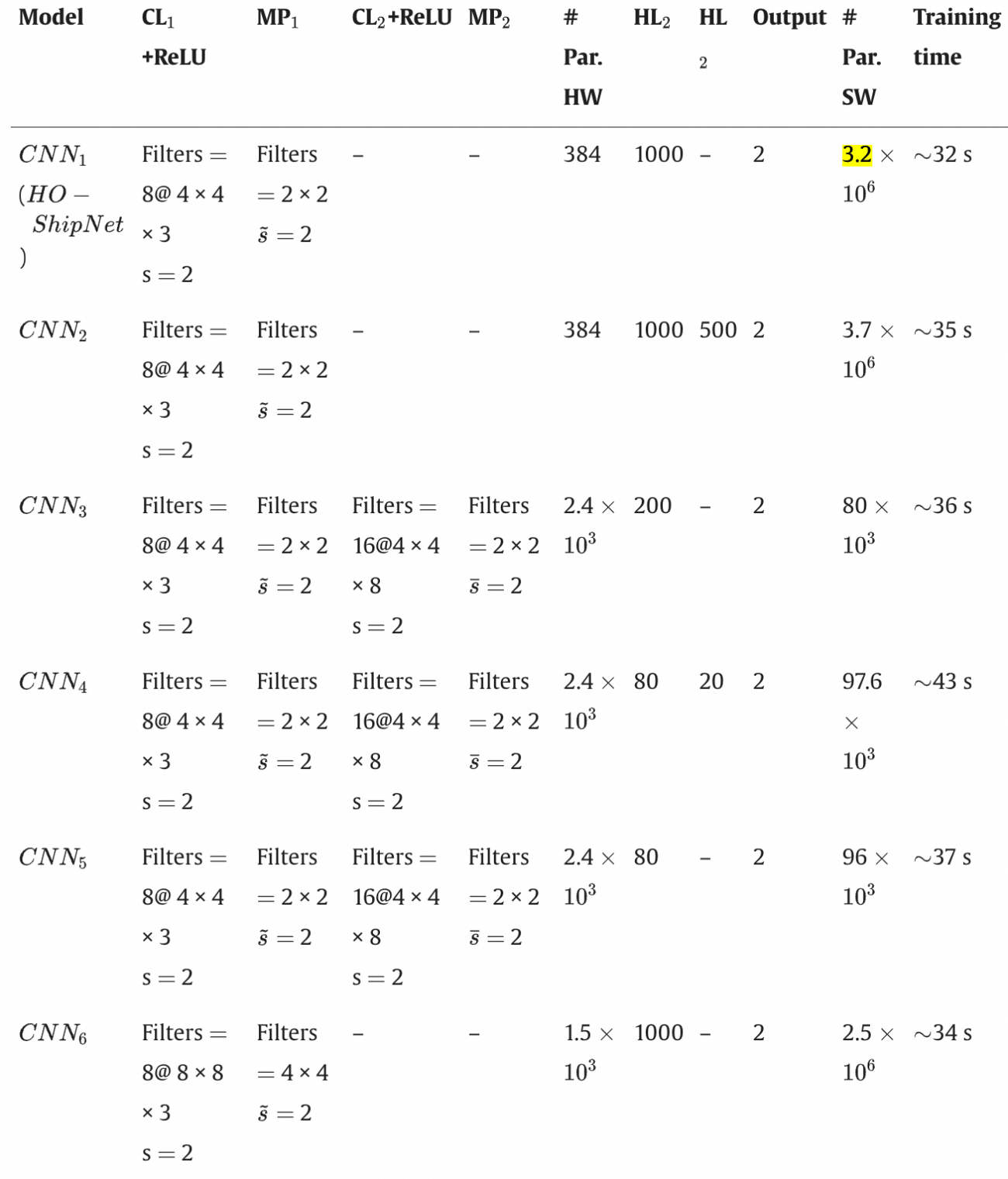
④パラメータの最小化
・本AIモデルでは、FPGAでの実装を考慮して、使用するパラメータを最小限に抑えている
・具体的には、以下のような設計がされている
– 畳み込み層: 8つのフィルター(サイズ:4×4×3)、移動幅(ストライド):2、画像の端の処理(パディング):1
– 最大プーリング層: フィルターサイズ:2×2、ストライド:2
– 全結合層:1000個の隠れニューロン
– ソフトマックス出力層: 船があるかないかの2クラスに分類
※Credit:Cosimo Ieracitano, Nadia Mammone, Fanny Spagnolo ,Fabio Frustaci, Stefania Perri, Pasquale Corsonello, Francesco C. Morabito(2024).An explainable embedded neural system for on-board ship detection from optical satellite imagery
◾️Explainable Artificial Intelligence(XAI)手法
①Local Interpretable Model-Agnostic Explanations (LIME)
[概要]
・LIMEは、AIモデルの複雑な意思決定を、よりシンプルで理解しやすい代理モデル(線形回帰モデル)で置き換える手法である
[具体例]
・LIMEは、特定の画素(ピクセル)を含めたり除外したりすることで、後工程の代理モデル(線形回帰モデル)に入れ込む複数の「代理画像」を生成し、それらをHO-ShipNetに入力してクラス(例えば、Ship/No-Ship)に属する確率を予測する
・
・上記ステップを通じて、元の複雑なモデル(HO-ShipNet)がどの画像領域に最も依存しているかを分析する
・具体的には、生成された代理画像の結果を基に、どの部分が重要な特徴であるかを特定するために線形回帰モデルを適用する
・その際の説明変数としては、各代理画像に対して、どの領域(スーパーピクセル)が保持され、どの領域が無効化されたかを示す特徴量を利用する
・目的変数はその代理画像に対してHO-ShipNetが予測した「船が存在する確率」となる
②Occlusion Sensitivity Analysis (OSA)
[概要]
・OSAは、モデルに入れ込む画像を直接的に操作(遮蔽)して、その影響を評価する手法である
・モデルの判断がどの部分に依存しているかを直感的に理解できるが、操作方法によってはモデルの挙動に影響を与えやすい
[具体例]
・画像全体に対して、例えば、小さな矩形のマスクを使って、部分的にピクセルを隠しますす
・本遮蔽は、画像全体にわたって複数の位置で実行され、元の画像に対してわずかな変更(遮蔽された画像)が生成される
・例として、船の画像であれば、船の一部(例えば、船首や船尾)を隠して、新しい画像を生成する
・遮蔽された画像をHO-ShipNetに入力し、クラス(例えば、Ship/No-Ship)に属する確率がどのように変動するかを測定する
・上記ステップを通じて、遮蔽された部分がモデルの判断にどれだけ重要であるかが明らかになる
・例えば、船の一部が隠された場合、その部分が予測結果に大きな影響を与えるのであれば、ネットワークがその部分に強く依存していることが分かる
【議論の内容・結果は?】
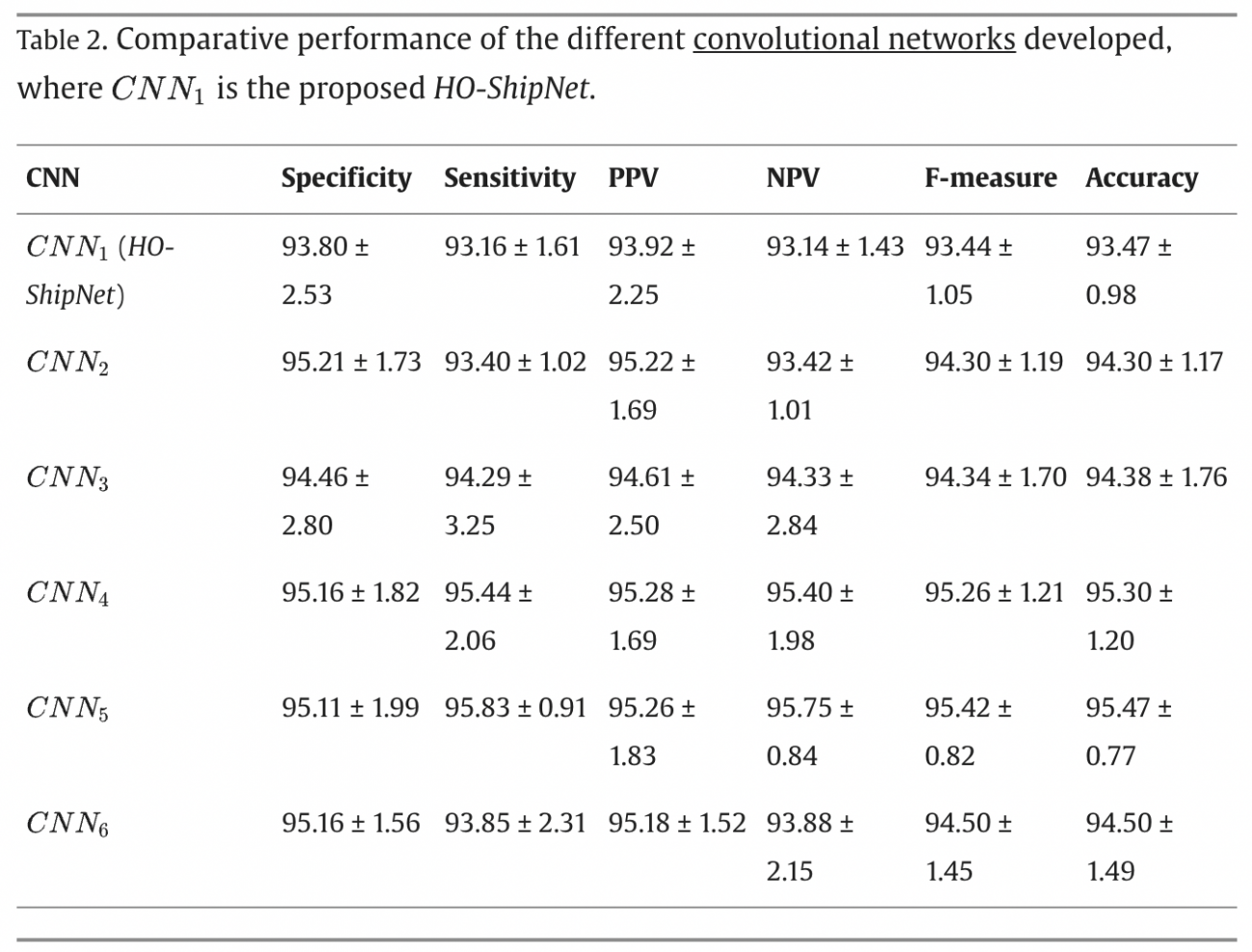
◾️結果
・HO-ShipNetの平均的な分類精度(Accuracy)は93.47%、Fスコアは93.44%であった
・上記は、他のモデルに比べて若干低いものの、実装のシンプルさとハードウェアリソースの最適化を考慮すると、非常に優れたパフォーマンスといえる
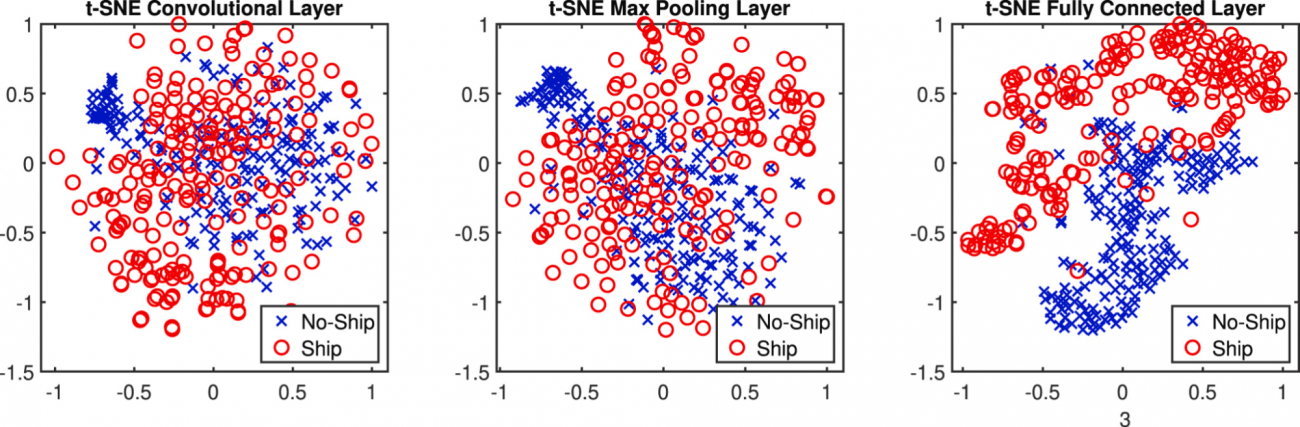
◾️t-SNEによる特徴分析
・t-SNE(t-distributed Stochastic Neighbor Embedding)を用いた特徴分析により、畳み込み層、プーリング層、全結合層から抽出された特徴の分布を視覚化した
・以下に示されるように、最初の段階では特徴が重なり合っているが、全結合層の後では、「Ship」と「No-Ship」クラスをより明確に区別できている
◾️XAIの適用結果
①OSA(以下図の中段)
・入力画像の船検出に最も関与する領域が、青(低重要度)から赤(高重要度)までのカラーグラデーションでハイライトされている
・具体的には、船体の中部、船尾、船首が特に重要であることがわかる
②LIME(以下図の下段)
・画像を小さな領域(スーパー・ピクセル)に分割し、ネットワークの決定に基づく最も重要な特徴を特定していることがわかる
・OSAとは対照的に、LIMEは船の全体の形状を考慮しており、部分的な船でも関連性を持つ特徴を見つけている

③総括
・OSAは特定の重要領域を明示的にハイライトするのに対し、LIMEは全体的な形状を考慮するため、より包括的な説明が可能となっている
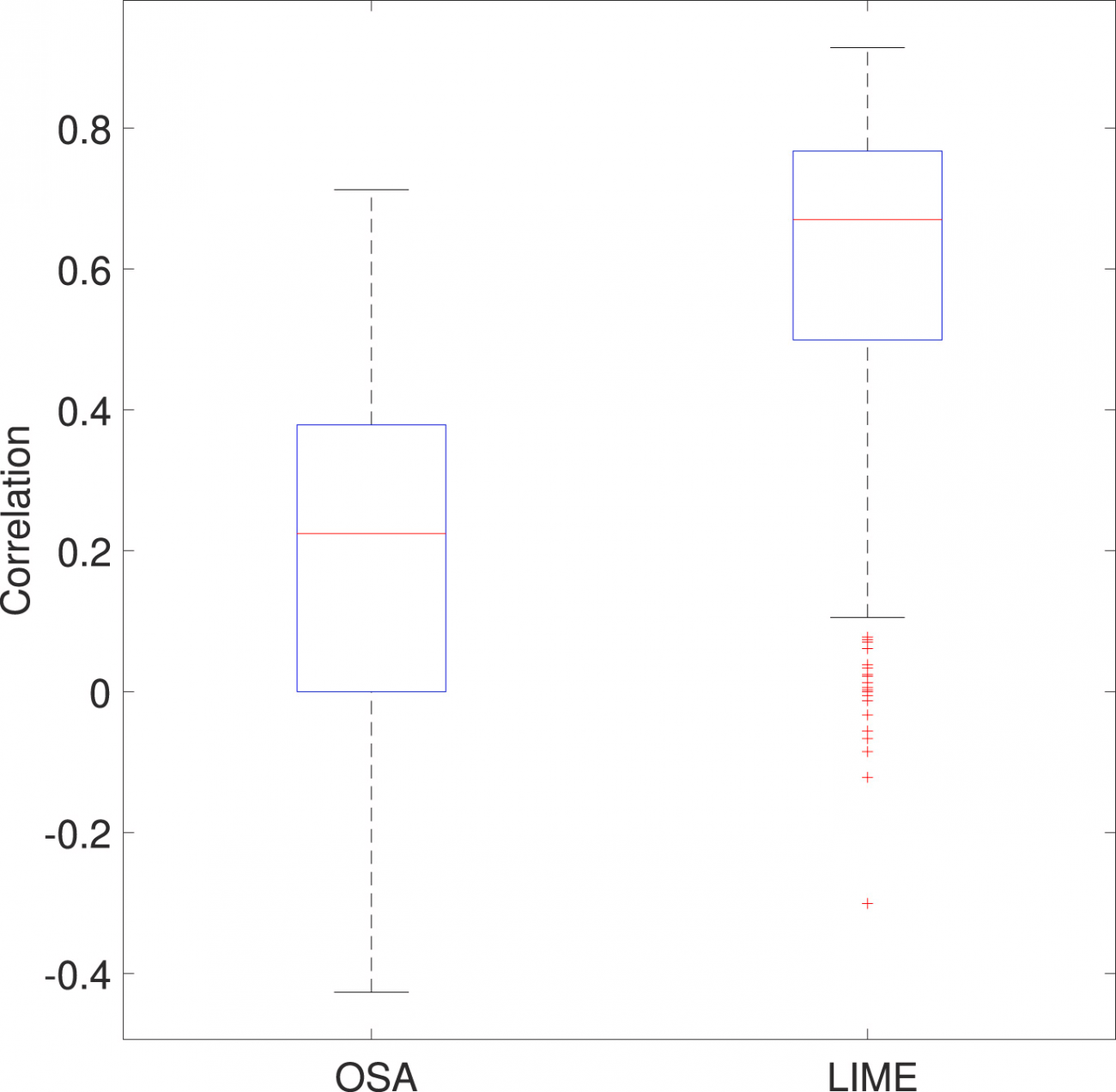
・以下のボックスプロットは、LIMEとOSAによる相関スコアの分布を視覚的に表現している
・LIMEの分布は中央値が約0.7であり、OSAの中央値約0.2と比べて強い類似性を示している
・つまり、LIMEはOSAに比べて、より一貫して高い相関を示しており、船の画像と対応するヒートマップの間に強い類似性を持つことを示しており、LIMEがHO-ShipNetの判断根拠をより明確に示す能力があることを意味する
#船舶検出 #Planet衛星 #CNN #FPGA #t-SNE #XAI #LIME #OSA
A fusion approach using GIS, green area detection, weather API and GPT for satellite image based fertile land discovery and crop suitability
【どういう論文?】
・本論文は、GPTモデルを活用して、精密な作物適合性分析を行う手法を提案する
【技術や方法のポイントはどこ?】
◾️インプット
①衛星画像
・Apple Mapsを主要なリソースとして利用する
②地理空間属性データ
・土壌湿度、気温、天気属性(降水量、風速、湿度、日照時間など)、土壌特性を取得する
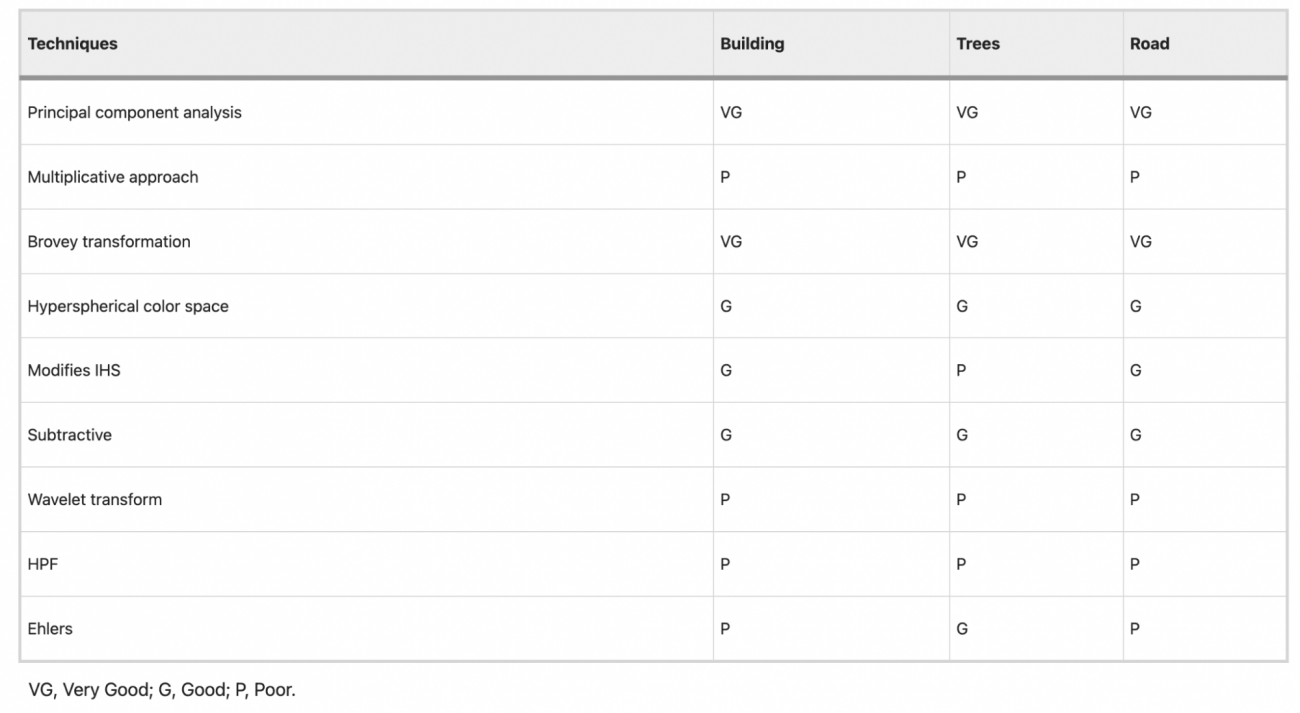
◾️画像処理
①パンシャープニング
・衛星画像の空間解像度を向上させるための技術である
・具体的には、高解像度のパンシャープニング画像と、低解像度のマルチスペクトル画像を融合させることで、鮮明な画像を生成する

②グレースケール変換
・次に、マルチスペクトル画像をグレースケールに変換する
・本変換は、赤(R)、緑(G)、青(B)チャネルの加重平均を取ることで行われる
・上記ステップにより、画像がより単純な形式に変換される
③リサンプリング
・グレースケール画像とパンシャープニング画像が同じピクセル寸法を持つように、パンシャープニング画像をリサンプリングする
④高域フィルタリング
・LaplacianフィルタやDifference of Gaussian(DoG)フィルタなどのフィルタを使用して、画像のエッジやディテールを強調し、特徴抽出を容易にする
⑤Brovey変換
・パンシャープニング画像とマルチスペクトルバンドを融合する
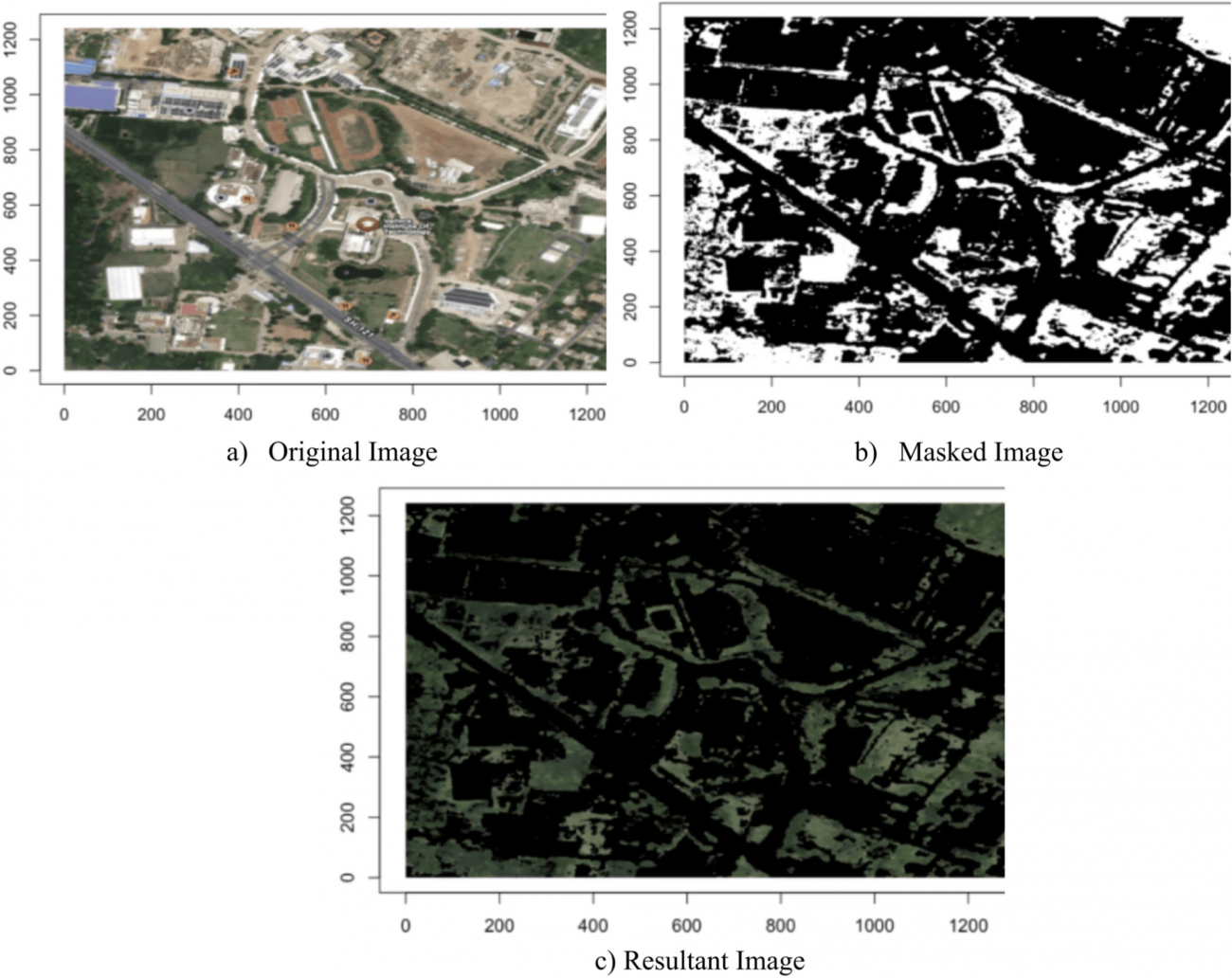
⑥カラー マスキング、セグメンテーション
・マップ画像から緑色の領域を抽出するためのカラー マスキングおよびセグメンテーション手法を適用する
・本手法では、画像をRGB色空間からHSV色空間に変換し、緑色のスペクトルをより効果的に捉える
◾️作物適合性予測
・GPT-4モデルを用いて気象条件と土壌条件を考慮し、最適な作物を提案する
・例えば、温度が30°Cを超える場合、低湿度ならピーナッツ、ヒマワリ、高湿度なら米、サトウキビなどと判断する
【議論の内容・結果は?】
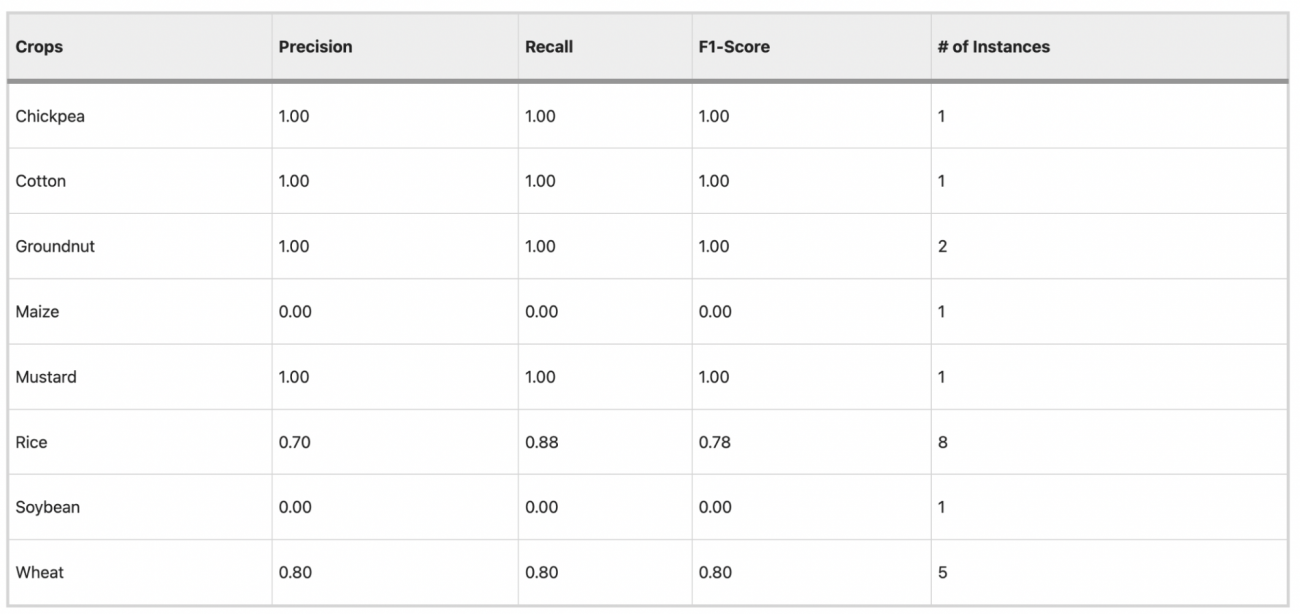
◾️結果
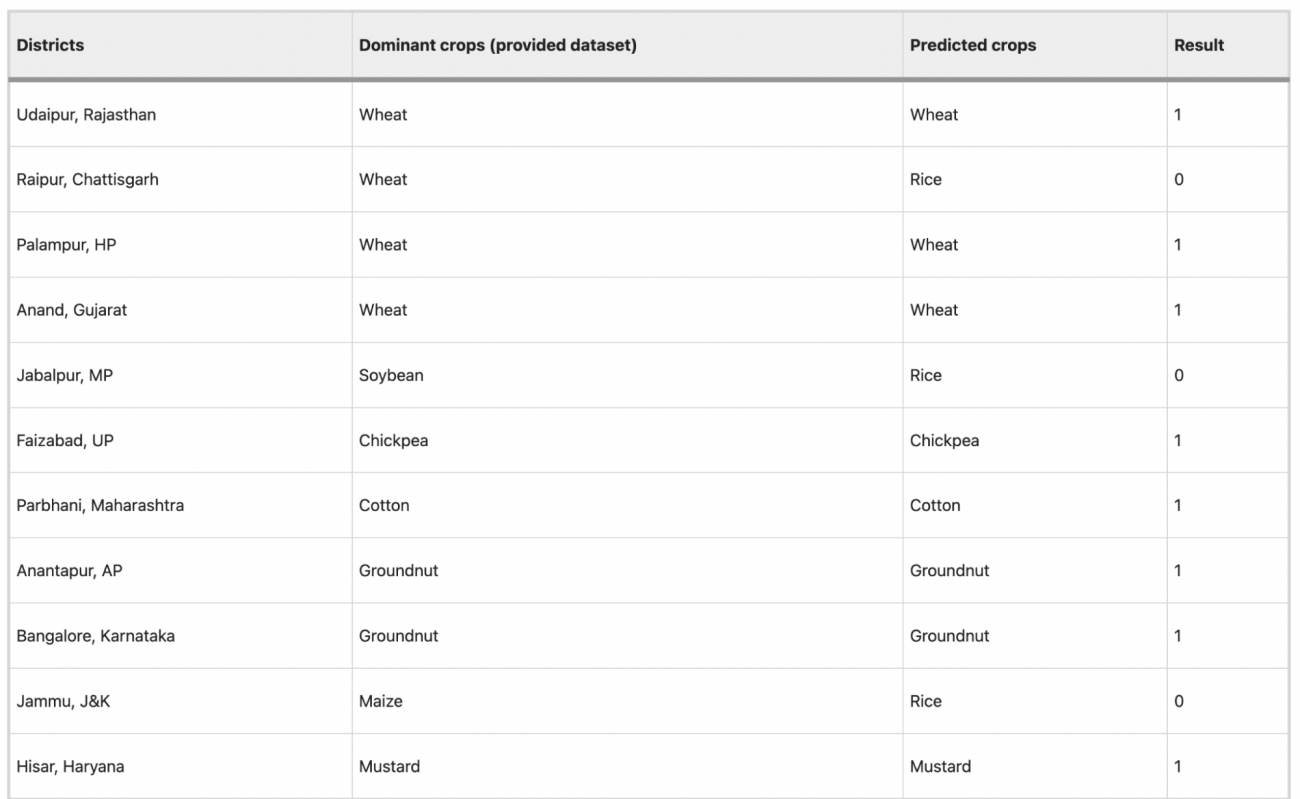
・Chickpea、Cotton、Groundnut、Mustardなどでは非常に高い精度を示しており、RiceやWheatでもまずまずの結果を得られた
・一方で、MaizeやSoybeanでは精度が低く、これらの作物の適性予測には改善の余地があることがわかった
・20のうち15の地区で、予測された作物がデータセットの主要作物と一致しており、80%の一致率を示した
#GPT #AppleMaps #パンシャープニング #グレースケール変換 #Laplacianフィルタ #Difference of Gaussian(DoG)フィルタ #Brovey変換
Segment-anything embedding for pixel-level road damage extraction using high-resolution satellite images
【どういう論文?】
・本論文は、高解像度の衛星画像を用いて道路損傷をピクセルレベルで自動的に識別するための新しいセグメンテーションモデル「RDSeg」を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の手法等に関するまとめ
①変化検出ベースの識別手法
・災害前後の画像の差異を強調することで損傷エリアを抽出する
・本アプローチはピクセルベースの画像解析に基づいている
・変化検出は明確な前後画像が必要となり、時には精度が低下することがある
②分類ベースの識別手法
・機械学習を用いて道路の損傷を分類タスクとしてモデル化する
・本方法では、手作りの特徴に基づくアプローチが一般的である
・ただし、本方法はしばしば局所的な特徴に限定され、大規模な災害評価には不向きであるという欠点がある
③SAM(Segment Anything Model)の衛星画像解析への応用
・SAMは、セグメンテーションデータセットを用いて事前学習され、さまざまな領域でのゼロショット一般化能力を示している
・SAMはその一般化能力から、リモートセンシング画像解析においてもゼロショットセグメンテーションツールとして使用され、セミオートマティックなアノテーションシステムの実装にも貢献している
・ただし、困難なシナリオにおいては満足のいく結果を得るのが難しいため、ドメイン固有のデータセットを用いたファインチューニングが重要視されている
◾データセット
・CAU-RoadDamage Datasetという、自然災害後の道路損傷の識別と解析を目的として作成されたデータセットを利用する
・本データセットは、中国四川省の二つの異なる地域で発生した地震後の衛星画像を基に構築されている
・使用されている衛星画像は、GeoEye1、Kompsat3、Pleiades1、WorldView2といった複数の衛星から取得されており、空間解像度は0.27メートルとなっている
◾️RDSegモデル
①全体アーキテクチャ
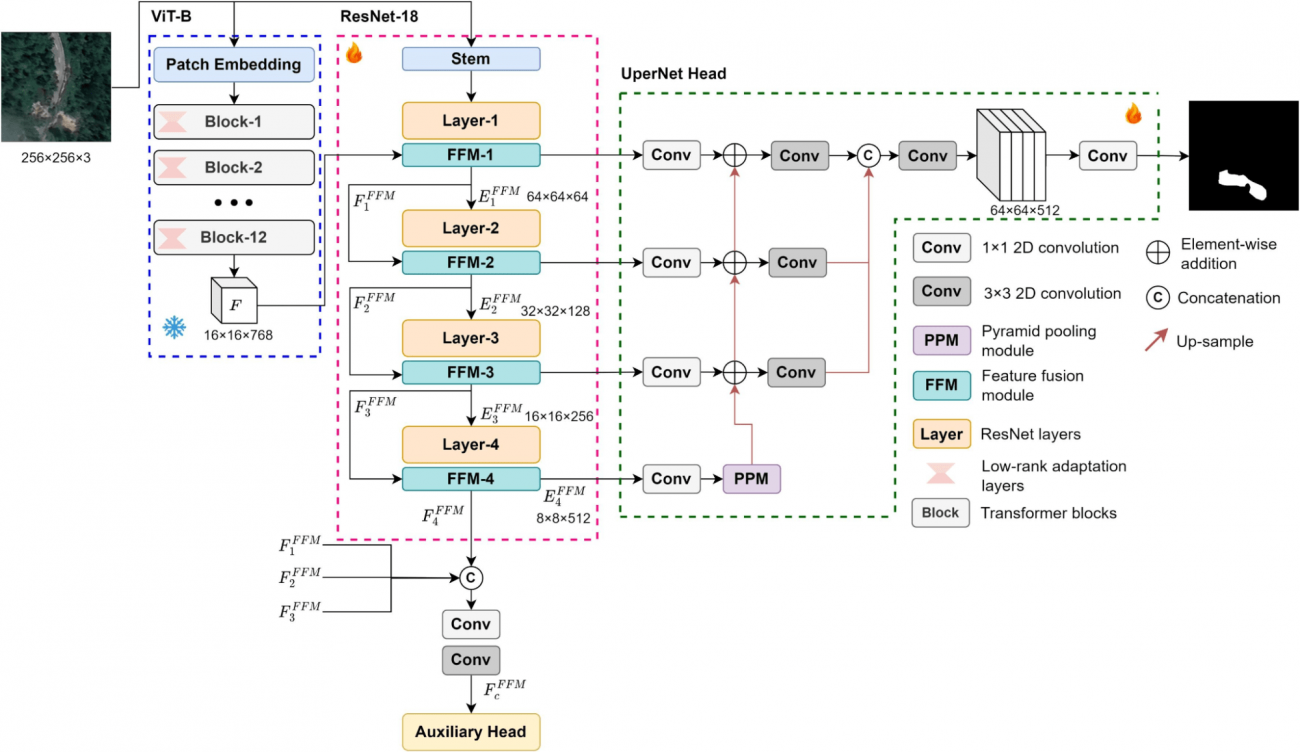
②ViT-B エンコーダー
・画像をパッチに分割し、それぞれのパッチを個別の入力として扱い、トランスフォーマーによる深い関係性と文脈を学習する
③ResNet-18エンコーダー
・ViT-Bの広範な文脈認識能力と、ResNet-18の局所的特徴抽出能力を組み合わせることで、画像の大局的な理解と細かいディテールの両方を捉える
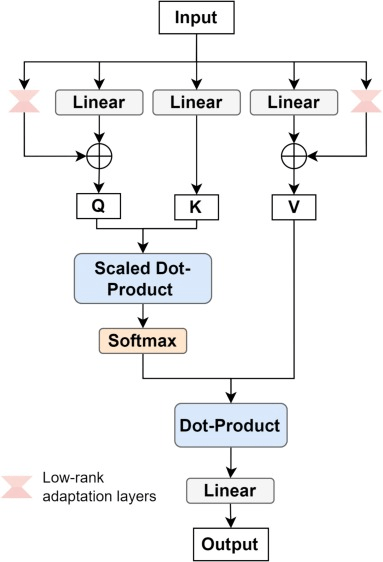
④低ランク適応層(LoRA)
・事前学習したモデル(この場合はViT-B)に対して特定のタスクのための調整を施す技術である
・LoRAは、深層学習モデル特にトランスフォーマーモデルのパラメータを、直接全て再学習するのではなく、重要なパラメータのみを微調整するアプローチとなっており、計算負荷とメモリ使用量を削減しながら、モデルの特定タスクへの適応性を向上させることができる
・具体的には、トランスフォーマーの各層(特に自己注意層のキー、クエリ、バリューの計算に使われる線形変換)に対して、元の行列を低ランク行列で近似することで、パラメータ数を削減する(元の高次元の行列を、積の形で表される低ランクの行列二つに分解する)
・今回の低ランク適応においては、ViT-Bの各トランスフォーマーブロック内の自己注意メカニズムやフィードフォワードネットワークの各層に適用する
⑤特徴融合モジュール(FFM)
・これらの異なる「言語」で表現された特徴を翻訳し、統合する役割を持っている
・具体的には、各特徴セットが他の特徴セットの「クエリ」(質問)に対して「キー」と「バリュー」(回答とその内容)として機能し、最適な特徴融合を実現する
⑥UperNetヘッド
・複数のスケールで得られた特徴を組み合わせて、ピクセル単位での分類を行う
【議論の内容・結果は?】
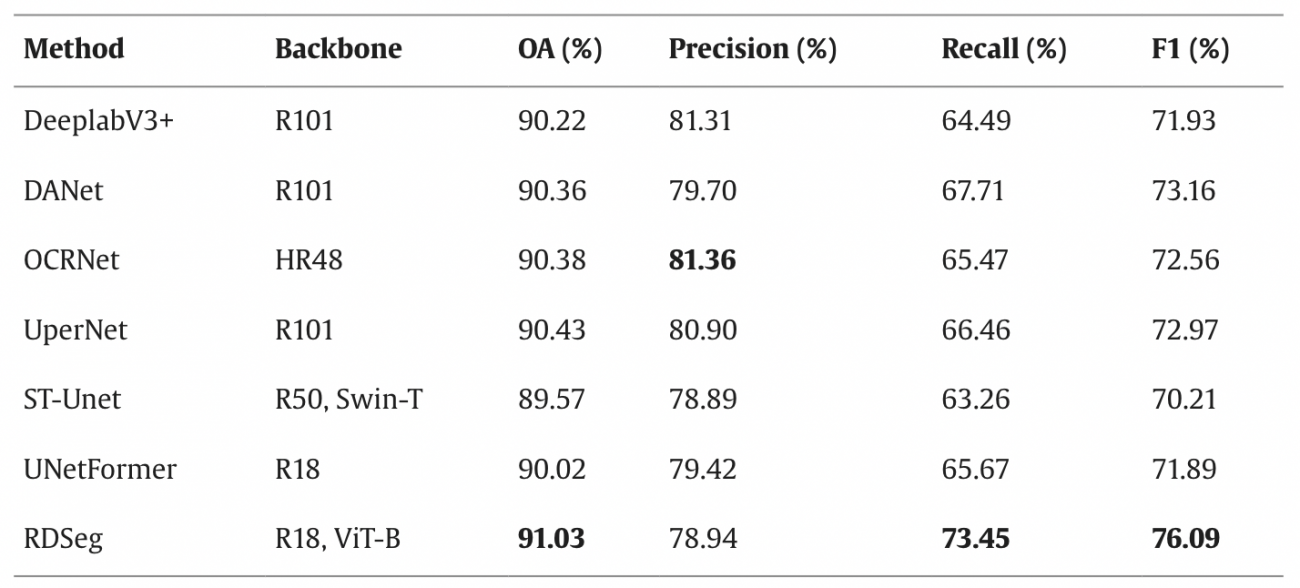
◾️結果
・DSegはこれらのモデル中で最高のF1スコア76.09%を達成しており、特にリコール値が73.45%と他モデルに比べて顕著に高い
・つまり、RDSegが道路に関する損傷を見逃しにくいということを示している

◾️マルチレベルでのViT特徴の使用結果
・RDSegでは、最終トランスフォーマーブロックの出力のみを利用するのではなく、第3、第6、第9、第12ブロックの出力を合算して特徴融合に利用している
・上記により、異なるレベルの表現力を画像解析に活かすことができる
・以下の結果から、マルチレベルの特徴を活用することがモデルの性能に繋がることがわかる

◾️ 低ランク適応層と特徴融合の効果
・低ランク適応層(LoRA)と特徴融合モジュール(FFM)を取り除いた場合の影響を検証した結果、以下の通りである
・LoRAとFFMがRDSegの性能に重要な貢献をしていることが明らかになったが、特にFFMの除去は性能低下に大きく影響しており、異なる種類の特徴を効果的に統合することの重要性を強調している
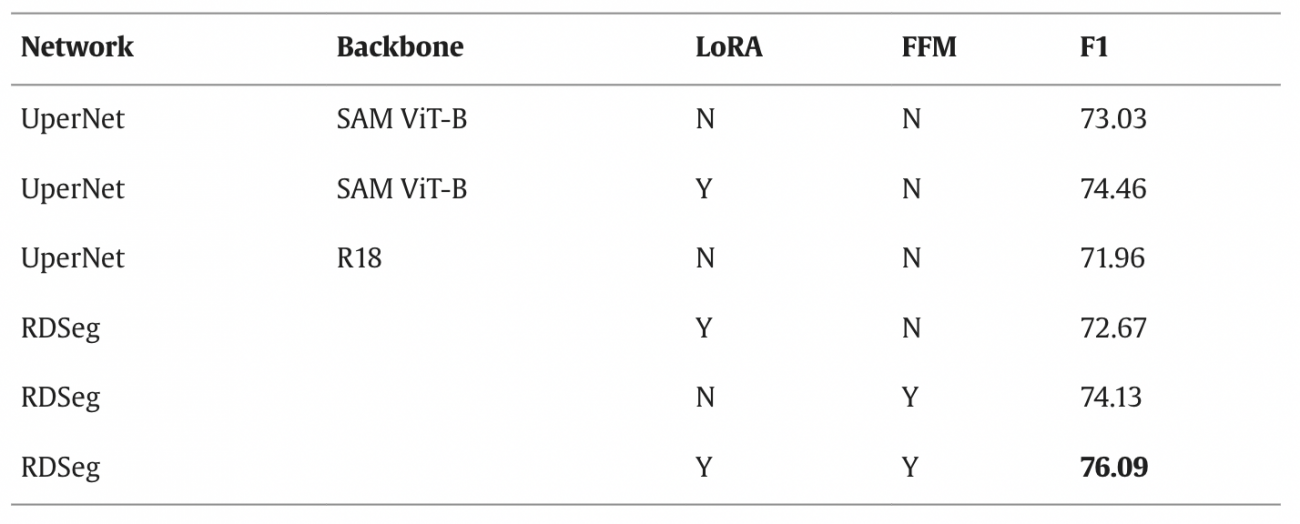
#地震 #災害 #Segment-Anything-Model #CAU-RoadDamage #GeoEye1 #Kompsat3 #Pleiades1 #WorldView2 #ViT #ResNet #LoRA #FFM #RDSeg
Advancements in high-resolution land surface satellite products: A comprehensive review of inversion algorithms, products and challenges
【どういう論文?】
本論文は、衛星リモートセンシング技術における光学センサーとアクティブセンサーの特性と、その応用プログラムなどを紹介する
【センサーの大分類】
◾️光学センサー(パッシブセンサー)
・太陽光などの自然光(可視光や近赤外線)を利用して地表面の反射光を記録する
◾️アクティブセンサー
・自らエネルギーを発信し、その反射や散乱を測定することでデータを取得する
・夜間や天候に関わらず観測が可能であるため、特に森林の垂直構造、氷の厚さ、地形の変動、災害監視などの分野で重要な役割を果たす
【高解像度の光学センサーを持つプログラム一覧】
◾️Landsatプログラム
①MSS (Multispectral Scanner System)センサー
[搭載衛星]
・Landsat-1, Landsat-2, Landsat-3, Landsat-4, Landsat-5
[空間解像度]
・80m
[バンド構成]
・バンド1: 可視光
・バンド2: 可視光
・バンド3: 近赤外線
・バンド4: 近赤外線
[運用期間]
・Landsat-1: 1972年7月23日〜1978年6月1日
・Landsat-2: 1975年1月22日〜1982年2月25日
・Landsat-3: 1978年5月3日〜1983年3月31日
・Landsat-4: 1982年7月16日〜1993年12月14日
・Landsat-4: 1984年1月3日〜2013年1月31日
②TM (Thematic Mapper)センサー
[搭載衛星]
・Landsat-5
[空間解像度]
・30m (可視光, 近赤外線,短波赤外線)
・120m (熱赤外線)
[バンド構成]
・バンド1: 可視光(青)
・バンド2: 可視光(緑)
・バンド3: 可視光(赤)
・バンド4: 近赤外線
・バンド5: 短波赤外線
・バンド6: 短波赤外線
・バンド7: 熱赤外線
[運用期間]
・Landsat-5: 1984年1月3日〜2013年1月31日
◾️EOS (Earth Observing System)プログラム
①ASTER (Advanced Spaceborne Thermal Emission and Reflection Radiometer)センサー
[搭載衛星]
・Terra (EOS衛星)
[空間解像度 / バンド構成]
・15m 解像度
– バンド1: 可視光
– バンド2 : 可視光
– バンド3N: 近赤外線
– バンド3B: :近赤外線
・30m 解像度
– バンド4: 短波赤外線
– バンド5: 短波赤外線
– バンド6: 短波赤外線
– バンド7: 短波赤外線
– バンド8: 短波赤外線
– バンド9: 短波赤外線
・90m 解像度
– バンド10: 熱赤外線
– バンド11: 熱赤外線
– バンド12: 熱赤外線
– バンド13: 熱赤外線
– バンド14: 熱赤外線
[運用期間]
・1999年12月18日〜現在
◾️Sentinel-2プログラム
①MSI (MultiSpectral Instrument)センサー
[搭載衛星]
・Sentinel-2a, Sentinel-2b
[空間解像度 / バンド構成]
・10m 解像度
– バンド2: 可視光(青)
– バンド3: 可視光(緑)
– バンド4: 可視光(赤)
– バンド8: 近赤外線
・20m 解像度
– バンド5: レッドエッジ
– バンド6: レッドエッジ
– バンド7: レッドエッジ
– バンド8a: 近赤外線
– バンド11: 短波赤外線
– バンド12: 短波赤外線
・60m 解像度
– バンド1: 可視光
– バンド9: 近赤外線
– バンド10: 短波赤外線
[運用期間]
・Sentinel-2a: 2015年6月23日〜現在
・Sentinel-2b: 2017年7月3日〜現在
◾️ECOSTRESSプログラム
①ECOSTRESS PHyTIR (ECOsystem Spaceborne Thermal Radiometer Experiment on Space Station)センサー
[搭載衛星]
・国際宇宙ステーション (ISS)
[空間解像度]
・70m 解像度
[バンド構成]
・バンド1: 短波赤外線
・バンド2: 熱赤外線
・バンド3: 熱赤外線
・バンド4: 熱赤外線
・バンド5: 熱赤外線
・バンド6: 熱赤外線
[運用期間]
・2018年6月29日〜現在
◾️HJプログラム
①HJ WVC (Wide-View Camera)センサー
[搭載衛星]
・HJ-1A, HJ-1B
[空間解像度]
・30m 解像度
[バンド構成]
・バンド1:可視光
・バンド2:可視光
・バンド3:可視光
・バンド4:近赤外線
[運用期間]
・HJ-1A: 2008年6月9日〜2022年12月31日
・HJ-1B: 2008年6月9日〜2022年12月31日
②HJ HSI (Hyperspectral Imager)センサー
[搭載衛星]
・HJ-1A
[空間解像度]
・100m 解像度
[バンド構成]
・115バンド: 可視光から近赤外線まで
[運用期間]
・HJ-1A: 2008年6月9日〜2022年12月31日
◾️GFプログラム
①GF PMC (Panchromatic Multispectral Camera)センサー
[搭載衛星]
・GF-1
[バンド構成]
・PAN: パンクロマティックバンド
・B1: 可視光
・B2: 可視光
・B3: 可視光
・B4: 近赤外線
[運用期間]
・2013年4月26日〜2022年12月31日
②GF WFI (Wide-Field Imager)センサー
[搭載衛星]
・GF-1, CBERS-4
[空間解像度 / バンド構成]
・B1: 可視光
・B2: 可視光
・B3: 可視光
・B4: 近赤外線, NIR
[運用期間]
・GF-1: 2013年4月26日〜2022年12月31日
・CBERS-4: 2014年7月12日〜2017年12月31日
③GF PMC-2 (Panchromatic Multispectral Camera-2)センサー
[搭載衛星]
・GF-2
[バンド構成 / 空間解像度]
・PAN: パンクロマティック / 0.8m
・B1–B4: 可視光~近赤外線 / 3.2m
[運用期間]
・2014年8月19日〜2022年12月31日
④GF AHSI (Advanced Hyperspectral Imager)センサー
[搭載衛星]
・GF-5
[空間解像度 / バンド構成]
・330バンド: 可視光から近赤外線
[運用期間]
・2019年7月9日〜現在
◾️PROBAプログラム
①CHRIS (Compact High Resolution Imaging Spectrometer)センサー
[搭載衛星]
・PROBA-1
[空間解像度 / バンド構成]
・62バンド: 可視光および近赤外線
・34バンド: 0.77–1.04µm
・18バンド: 0.40–1.95µm
[運用期間]
・2002年10月17日〜2021年12月31日
②HRC (High-Resolution Camera)センサー
[搭載衛星]
・PROBA-1
[空間解像度]
・5〜20m
[バンド構成]
・PAN: パンクロマティック
[運用期間]
・2002年10月17日〜2021年12月31日
③VGT-P (Vegetation Product)
[搭載衛星]
・PROBA-V
[空間解像度 / バンド構成]
・100m / 可視光, 赤外線
・200m / 短波赤外線
[運用期間]
・2013年7月5日〜2021年12月31日
◾️HRVプログラム
①HRV (High-Resolution Visible)センサー
[搭載衛星]
・SPOT-1、SPOT-2、SPOT-3
[空間解像度 / バンド構成]
・10m / パンクロマティック
・20m / マルチスペクトラル(可視光 赤, 可視光 緑, 近赤外線)
[運用期間]
・SPOT-1: 1986年2月22日〜2003年11月31日
・SPOT-2: 1990年1月22日〜2009年7月31日
・SPOT-3: 1993年9月26日〜1996年9月31日
②HRVIR (High-Resolution Visible and Infrared)センサー
[搭載衛星]
・SPOT-4
[空間解像度 / バンド構成]
・10m / パンクロマティック
・20m / マルチスペクトラル(可視光 赤, 可視光 緑, 近赤外線, 短波赤外線)
[運用期間]
・1998年3月24日〜2013年6月29日
③HRG (High-Resolution Geometry)センサー
[搭載衛星]
・SPOT-5
[空間解像度 / バンド構成]
・5m / パンクロマティック
・10m / マルチスペクトラル(可視光 赤, 可視光 緑, 近赤外線)
・20m / 短波赤外線
[運用期間]
・2002年4月5日〜2015年3月31日
④NAOMI (New Advanced Optoelectronic Multispectral Instrument)センサー
[搭載衛星]
・SPOT-6
・SPOT-7
[空間解像度 / バンド構成]
・1.5–2.5m / パンクロマティック
・6–10m / マルチスペクトラル(可視光 赤, 可視光 緑, 近赤外線, 短波赤外線)
[運用期間]
・SPOT-6: 2012年9月9日〜現在
・SPOT-7: 2014年6月30日〜現在
【高解像度アクティブセンサーを持つプログラム一覧】
◾️GEDI Lidarセンサー
①搭載衛星
・国際宇宙ステーション (International Space Station)
②空間解像度 / バンド構成
・22m
・近赤外線
③運用期間
・2018年8月11日〜現在
◾️LVIS (Land, Vegetation, and Ice Sensor)センサー
①搭載プラットフォーム
・エアボーン
②空間解像度 / バンド構成
・5m
・近赤外線
③運用期間
・2016年〜現在
◾️MABEL (Multiple Altimeter Beam Experimental Lidar)センサー
①搭載プラットフォーム
・エアボーン
②空間解像度 / バンド構成
・2m
・近赤外線
③運用期間
・2010年1月12日〜2012年12月31日
◾️GLAS (Geoscience Laser Altimeter System)センサー
①搭載衛星
・ICESat
②空間解像度 / バンド構成
・70m
・近赤外線, 可視光(緑)
③運用期間
・2003年12月1日〜2021年12月31日
◾️ATLAS (Advanced Topographic Laser Altimeter System)センサー
①搭載衛星
・ICESat-2
②空間解像度 / バンド構成
・10m
・可視光(緑)
③運用期間
・2018年9月18日〜現在
◾️VQ480 Scanning Lidarセンサー
①搭載プラットフォーム
・エアボーン
②空間解像度 / バンド構成
・1m
・可視光, 近赤外線
③運用期間
・2011年〜2018年
◾️LD321-A40 Profiling Lidarセンサー
①搭載プラットフォーム
・エアボーン
②空間解像度 / バンド構成
・1m
・近赤外線, 短波赤外線
③運用期間
・2011年〜2018年
【前処理技術】
◾️雲マスク
①雲検出方法
・雲検出には、物理的ルールに基づく方法、時系列に基づく方法、機械学習に基づく方法の3つの主要な手法がある
・物理的ルールに基づく方法は、雲の高い反射率や低い輝度温度に基づいて、閾値を適用して雲ピクセルを識別する
・時系列に基づく方法は、画像の時系列における突然の反射率の増加を検出することで雲を識別する
・機械学習に基づく方法では、スペクトル、空間、時間的特徴を用いて雲と地表を区別する
②課題
・薄雲の検出が困難であったり、明るい地表面(雪や建物など)を雲と誤認識する可能性がある
・また、深層学習ベースの方法は、多数の高品質なトレーニングサンプルを必要とし、これらのデータセットが限られていることが課題となっている
◾️エアロゾル光学的厚さ(AOD)
①概要
・大気の濁り具合を表す
・太陽光を散乱または吸収することで、地球の放射収支に影響を与え、気候変動を引き起こす可能性がある
・また、雲の形成に寄与し、降水パターンに影響を与えることもある
②AOD推定方法
・ダークターゲット法やディープブルーアルゴリズムなど、様々な手法が開発されており、これらの手法を用いて、異なる地表条件でのAOD推定が行われている
③課題
・都市部では、地表面の複雑さやエアロゾルの種類が多様であるため、高解像度のAOD推定には多くの課題が残っている
・現在、高解像度のAODデータ製品はほとんど公開されておらず、広範囲にわたる適用や検証が十分に行われていない
◾️大気補正
①大気補正の手法
・衛星画像の大気補正には、AODや水蒸気の情報が重要である
・高解像度衛星の多くは、これらの情報を直接取得するためのスペクトルバンドを持たないため、MODISなどの低解像度製品からの情報を利用することが一般的となっている
②ソフトウェア
・ATCOR、FORCE、iCOR、LaSRCなどのソフトウェアが、大気補正を行うために使用されている
・これらのソフトウェアは、DT(Dark Target)法や改善されたバージョンを使用しており、異なる地域での補正をサポートしている
◾️地形補正(Topographic Correction)
①概要
・山岳地帯では、地形が地表面の照射条件(例えば、日陰と日向の違い)に大きな影響を与え、地表面のパラメータ推定や土地被覆分類に影響を与える
②地形補正の手法
・地形補正の手法には、物理モデル、半経験モデル、経験モデルがある
・物理モデルは、放射伝達プロセスを詳細に考慮するため、理論的には正確だが、広範囲での適用には低効率である
・一方、半経験モデルは、大規模な地域での適用が容易であり、最近の研究では、経験的パラメータ計算の改良に焦点が当てられている
③課題
・地形補正手法の評価は、異なる研究で異なる結論が得られており、最適な手法についてのコンセンサスはまだ得られていない
・また、地形補正が施された長期的な地表面反射率データセットはほとんど存在せず、将来的には、地形補正の定量的評価に関する研究が必要とされている
【地表放射収支の構成要素】
①アルベド(Albedo)
・太陽光をどれだけ反射しているかを表す
・地表エネルギー収支や地表と大気の相互作用を理解するための重要な要素である
②地表面温度(LST)
・地表面温度(LST)は、水ストレスや火災監視、蒸発散推定などにおいて重要な役割を果たす
①ネット放射(Rn)
・地表面の全波長ネット放射(Rn)は、下向きおよび上向きの短波放射と長波放射で構成され、地表における利用可能な放射エネルギーの基礎的な測定値である
【地上生態系に関するさまざまな変数】
①葉面積指数(LAI)
・単位水平地表面積あたりの総葉面積である
・生態系の光合成と呼吸、植生の動態モニタリング、地表モデルのシミュレーション、そして地球規模の気候変動において重要な変数である
②光合成有効放射吸収率(FAPAR)
・FAPARは、緑色植生によって吸収された光合成有効放射の割合を表す
・これは、植生の光合成、一次生産の推定、および地上炭素循環シミュレーションにおいて重要な変数である
③植生被覆率(FVC)
・FVCは、指定されたエリア内の地面に垂直に投影された植生の面積割合として定義される
・FVCは、広範な空間スケールにおける植生の状態と動態を表す重要な変数である
④森林被覆率(FFC)
・FFCは、垂直方向から見たピクセル全体に対する森林冠被覆面積の割合を表す
⑤樹高
・樹高は、森林生態系の理解や森林バイオマス、炭素蓄積、森林の生産性、地表粗度などの生態学的および生物物理的変数を推定するための重要な構造パラメータである
⑥地上バイオマス(AGB)
・AGBは、森林の炭素循環において重要な役割を果たし、地上バイオマスのオーブンドライマスを表す
#光学センサー #アクティブセンサー #Landsat #EOS #Sentinel-2 #ECOSTRESS #HJ #GF #PROBA #HRV #GEDI #LVIS #MABEL #GLAS #ATLAS
以上、2024年7月に公開された論文をピックアップして紹介しました。
皆様の業務や趣味を考えた時に、ピンとくる衛星データ利活用に関する話題はありましたか?
最後に、#MonthlySatDataNewsのタグをつけてTwitterに投稿された全ての論文をご紹介します。
来月以降も「#MonthlySatDataNews」を続けていきますので、お楽しみに!
