【2024年10月】衛星データ利活用に関する論文とニュースをピックアップ!
2024年10月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました
2024年10月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
・Human bias and CNNs’ superior insights in satellite based poverty mapping
(専門家のバイアスを減らし、CNNによる自動特徴抽出で衛星画像から貧困レベルを高精度に推定する手法)
・Quantitatively detecting ground surface changes of slope failure caused by heavy rain using ALOS-2/PALSAR-2 data: a case study in Japan(豪雨による斜面崩壊領域の迅速かつ高精度な抽出手法)
・Space-Based Mapping of Pre- and Post-Hurricane Mangrove Canopy Heights Using Machine Learning with Multi-Sensor Observations(ハリケーン後のマングローブ樹冠高をマルチセンサーで推定する手法)
・Enhancing spatial resolution of satellite soil moisture data through stacking ensemble learning techniques(スタッキングアンサンブル学習を用いて衛星土壌水分データの空間解像度を高める手法)
・Deep-Learning for Change Detection Using Multi-Modal Fusion of Remote Sensing Images: A Review(異なる解像度・センサーからのデータを統合し、ディープラーニングを用いてリモートセンシング画像の変化検出精度を向上させる手法)
宙畑の連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
また、「#MonthlySatDataNews」「#衛星論文」とハッシュタグがつけられた投稿もピックアップをしており、2024年10月に投稿いただいたのはこちらの方でした!
Human bias and CNNs’ superior insights in satellite based poverty mapping | Scientific Reports #衛星論文
専門家による目視判読と機械学習による貧困地域推定に関する比較 https://t.co/gye862h5tE
— たなこう (@octobersky_031) October 2, 2024
それではさっそく2024年10月の論文を紹介します。
Human bias and CNNs’ superior insights in satellite based poverty mapping
【どういう論文?】
・本論文は、専門家のバイアスを減らし、CNNによる自動特徴抽出で衛星画像から貧困レベルを高精度に推定する手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
①データの欠如や不整合
・多くの発展途上地域では、所得データや支出データが不完全であったり、季節的な影響を受けやすい現金取引に依存していたりするため、従来の所得や支出ベースの貧困指標が信頼性を欠くことがある
②人間のバイアス
・従来の貧困測定法では、地域の貧困レベルを評価するために、現地で得られる「資産データ」が使われている
・資産データとは、各家庭が持っている家電、家の構造や素材などに関する情報である
・ただし、従来の資産ベースの貧困指標は、専門家の観察や経験に基づいており、評価の一貫性や客観性に限界がある
・また、専門家による視覚的判断は「中央傾向バイアス(曖昧な状況や確信が持てないときに現れやすく、評価結果が「真ん中寄り」になること)」に影響されやすく、実際の貧困分布を正確に反映しない場合が多い
③衛星画像の活用における制限
・衛星画像は広範囲かつ頻繁にデータ収集できる利点があるが、主に物理的な地形を記録するため、人的条件を判別するには不十分なデータとみなされてきた
・人間が画像から貧困を判断する際には、解像度や画像の扱いに制約があり、特定の特徴に依存しすぎる傾向がある
◾️本研究の方針
①機械学習による高精度な貧困推定
・CNNのような機械学習モデルは、人間が気づかない貧困の指標やパターンを衛星画像から抽出し、専門家の判断よりも精度の高い貧困レベルの推定が可能であると考える
②人間の介入を少なくする
・人間のバイアス(特に「中央傾向バイアス」)があるため、人間の介入を減らすほど貧困推定の精度が向上すると考える
◾️データセット
①正解データ
・Tanzania 2015 DHSというデータセットを利用する
・DHS(Wealth Index )とは、各世帯の相対的な経済的豊かさを示す資産ベースの指標であり、教育や健康の情報とは独立して家計の相対的な経済的福祉を評価する
・評価指標としては、資産の所有とサービスへのアクセス(電気など)、建物の構造が利用される
・本論文では、DHSデータの世帯ごとの富インデックスを5つのカテゴリ(poorer, poor, average, wealthy, wealthier)に分類する
②衛星(学習)データ
・Google Maps APIを利用して、補正済み座標に基づいた計608枚の高解像度画像を取得して利用する
③専門家が利用する情報
・住宅の特徴:建物の種類、屋根材、屋根の状態、建物のサイズ
・景観の特徴:集落構造、建物密度、緑被率、主要土地利用(農地、商業地域など)、画像の色合い
・インフラ / 資産:道路の質、道路幅、道路の覆われ具合、車両の存在、農地サイズなど
◾️分析手法
①多項ロジスティック回帰
・専門家が定義した特徴量(例:建物密度や緑被率)を用いて、多項ロジスティック回帰モデルを構築し、各クラスターの貧困レベルを予測する
②ランダムフォレスト
・同様に専門家定義の特徴量を使用し、ランダムフォレストモデルで貧困レベルを予測する
③CNN
・特徴量を手動で定義せず、CNNが衛星画像から自動的に特徴を抽出して、各クラスターの貧困レベルを予測する
・本研究では、MobileNetV2という、もともとImageNet(多くの一般的な画像で学習されたデータセット)で事前学習されたモデルの軽量版を利用している
【議論の内容・結果は?】
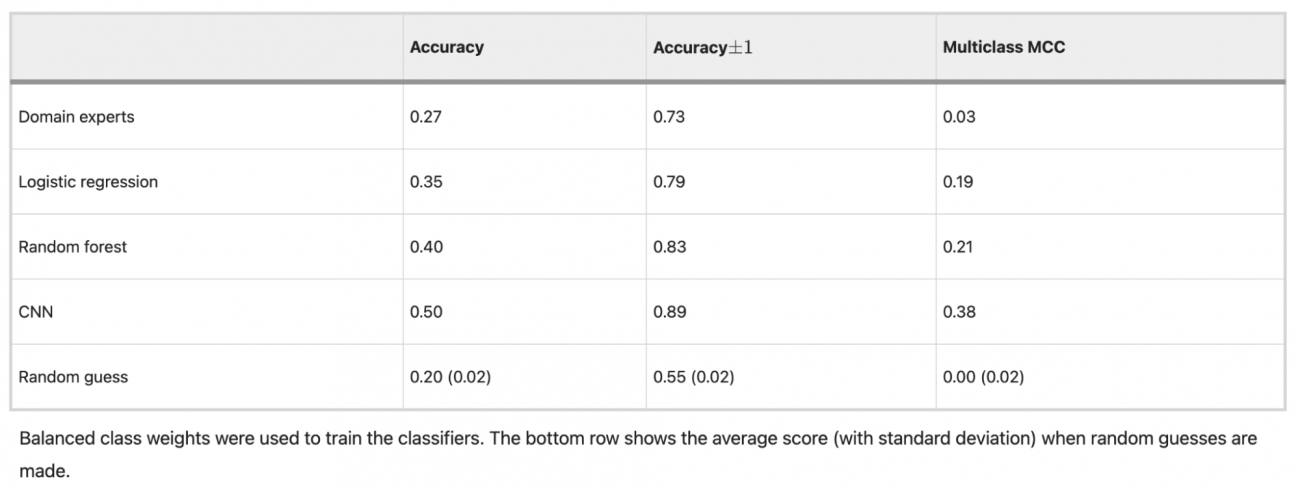
◾️モデル別評価指標
①Accuracy
・最も高いのはCNN(0.50)、次いでランダムフォレスト(0.40)、ロジスティック回帰(0.35)であった
・なお、Domain experts(手動評価)は0.27と最も低かった
②Accuracy±1(推定が実際のカテゴリから1つ以内のクラスに収まる割合)
・CNNが0.89と最も高く、続いてランダムフォレスト(0.83)、ロジスティック回帰(0.79)と続いた一方、専門家のスコアは0.73とやや劣った
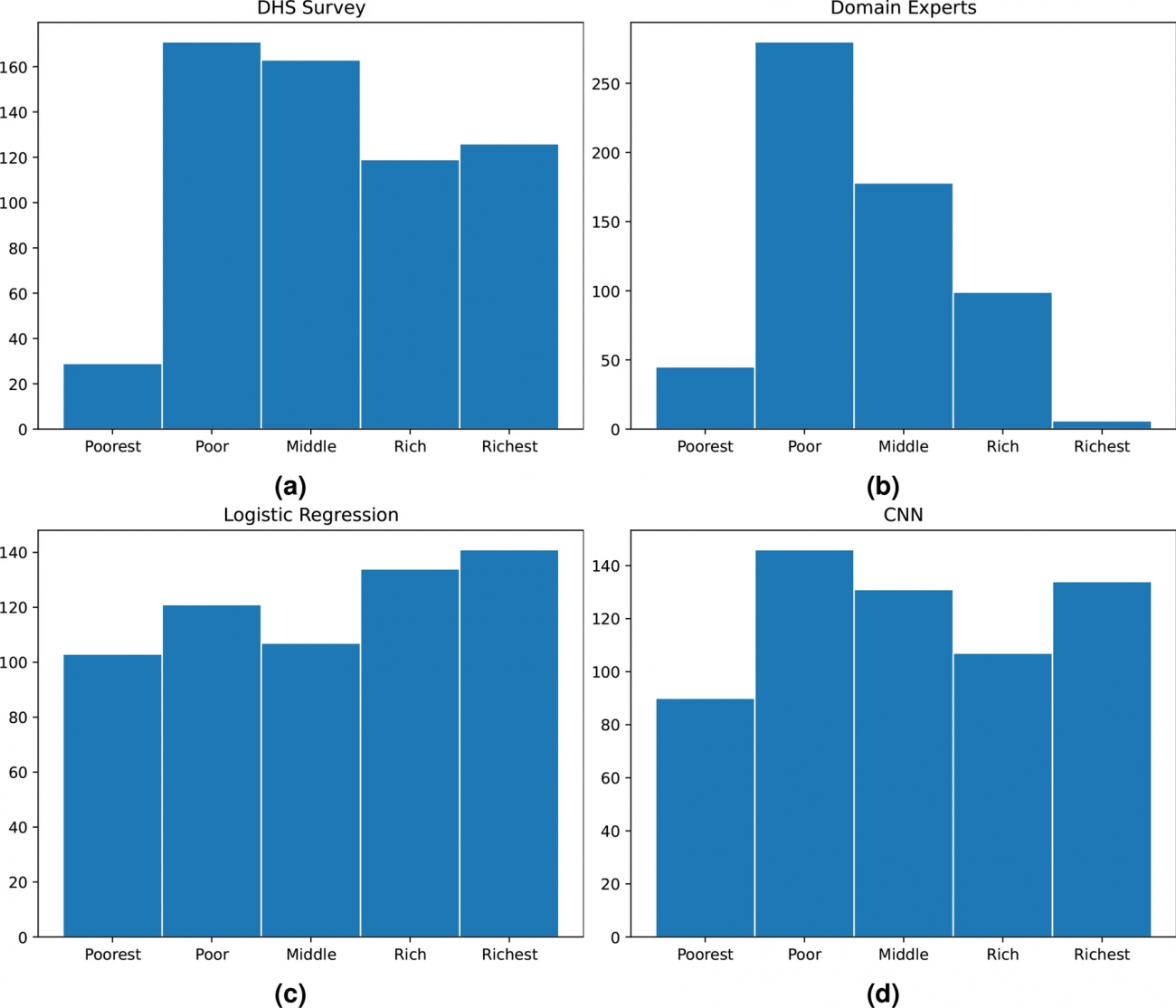
◾️富レベルの分布
①正解データ
・Figure 2aによると、各クラスターの貧困レベルが偏りなく5つのカテゴリに分布している
②専門家評価
・Figure 2bの通り、専門家の評価分布では、富レベルが低めに集中して中央に偏っている
・専門家が平均に寄りがちな「中央傾向バイアス」の影響が見られ、実際の分布と異なる
③ロジスティック回帰とCNNの分布
・Figure 2c, dの通り、CNNはDHSデータセットに最も近い分布を示しており、精度が高いことが確認できる
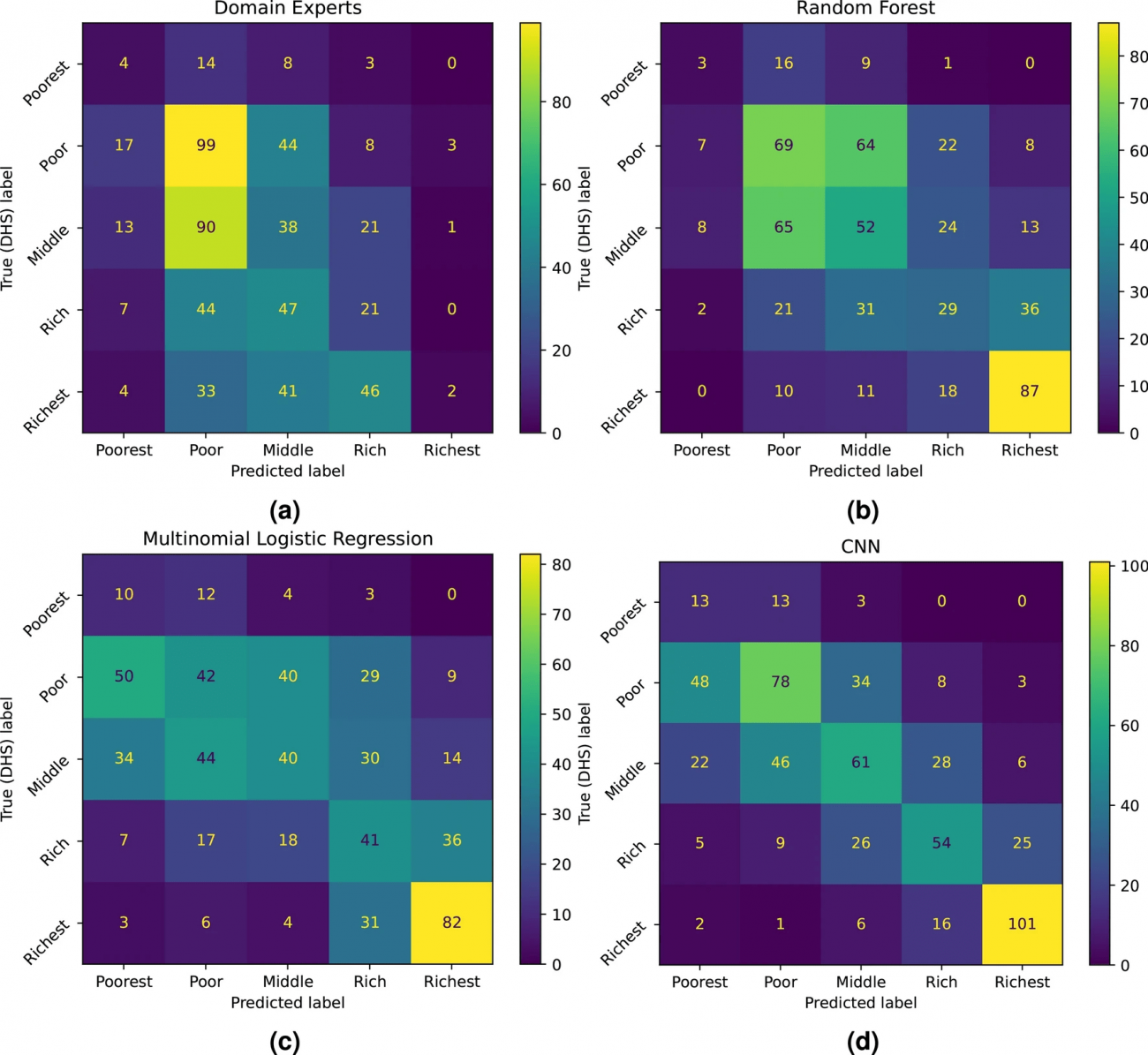
◾️異なる手法による貧困レベルの分類結果を示す混同行列
・以下の図は、専門家、ランダムフォレスト、ロジスティック回帰、CNNの各マトリクスで、予測値と実際の値がどれだけ一致するかを比較している
・専門家は極端な貧困層や裕福層を見分けることが難しい(「Poor」や「Middle」に集中している)一方、CNNは全体的な一致率が最も高く、特に最貧層や最富裕層で良好な結果を示している
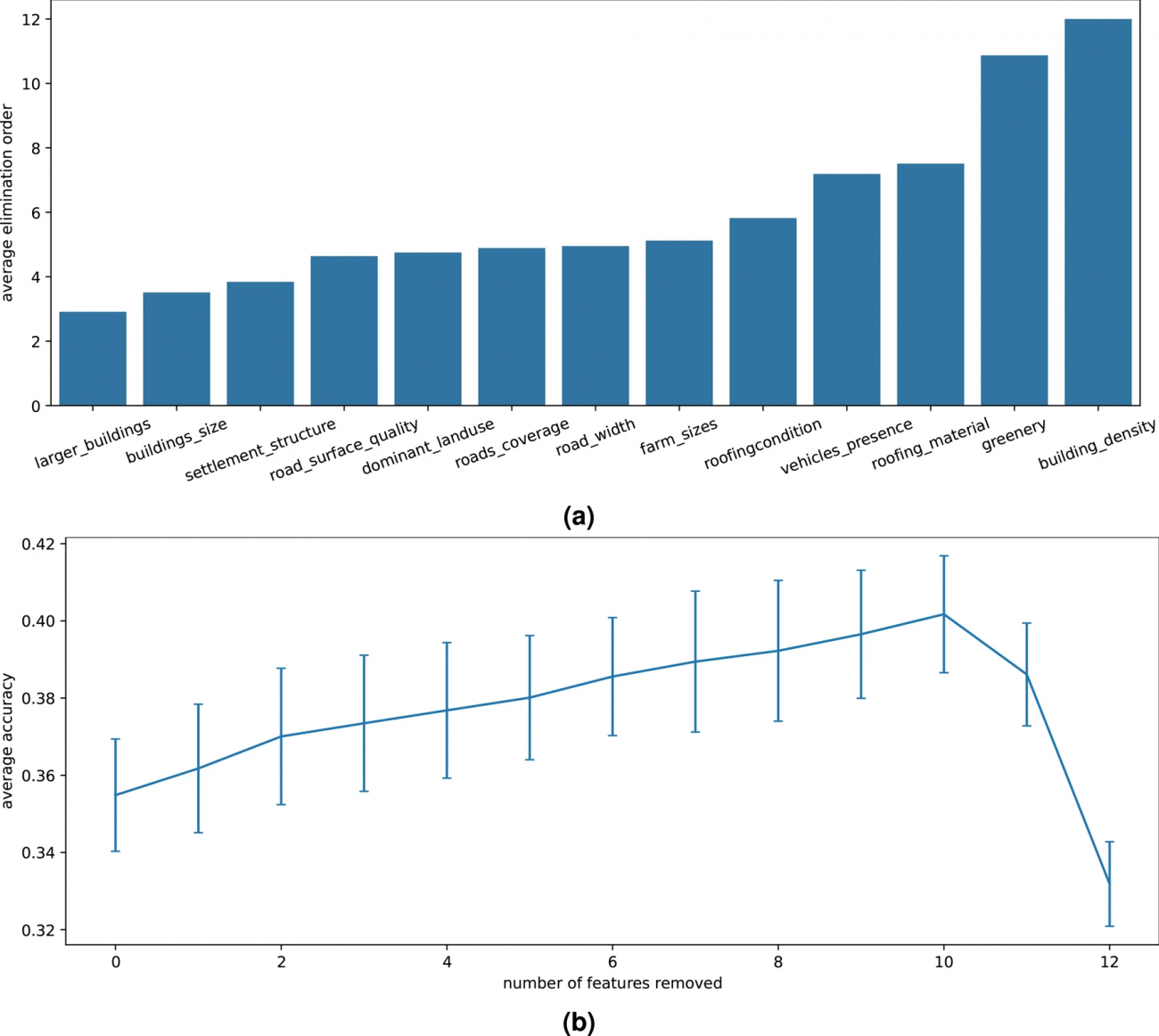
◾️専門家定義の特徴量の重要性
・重要な特徴を見極めるために、順次特徴を削除して精度の変化を確認する「バックワードエリミネーション」を行った上で、特徴の削除による精度の変化を確認したところ、最初にいくつかの特徴が削除されると精度が上がる傾向が見られた
・一方で、重要な特徴(建物密度、緑被率、道路被覆率など)が残るまで削除が進むと、急激に精度が低下した
・建物密度と緑被率は最後まで残る特徴で、富レベル推定において重要度が高いことが示さ
#貧困 #CNN #中央傾向バイアス #DHS #多項ロジスティック回帰 #ランダムフォレスト #建物密度 #緑被率 #道路被覆率
Quantitatively detecting ground surface changes of slope failure caused by heavy rain using ALOS-2/PALSAR-2 data: a case study in Japan
【どういう論文?】
・本論文は、豪雨による斜面崩壊領域の迅速かつ高精度な抽出手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
①迅速な変化抽出
・災害(特に豪雨による斜面崩壊)後の地盤変化抽出には光学データも活用されてきたが、光学データは悪天候や雲によって遮られるため、即時利用が困難であった
②SARデータ特有のノイズ(スペックルノイズ)の影響
・SARデータは全天候で利用できる利点があるものの、スペックルノイズによりデータのばらつきが大きくなり、変化検出の精度が低下する問題がある
※スペックルノイズとは、地表の細かい構造や粗さによって反射がバラバラになることに起因する画像全体の「斑点」や「ザラザラ」のことを指す
③閾値設定の地理的限界
・SARデータで地表の変化を検出する際、通常は「災害前後のバックキャッタ係数の差分」を使って変化を抽出するが、地域ごとに地形や土地の状態(森林や農地など)が異なるため、同じ閾値では正確に変化を検出できない場合がある
※バックキャッタ係数とは、地表から反射されて戻ってきた電波の強さを指す
④ピクセルベース手法の限界
・SARデータのピクセルベースでの変化検出は、解析単位であるピクセルサイズに依存し、地形の特性(例:斜面の大きさや角度)と対応が取れないため(各ピクセルが独立して変化を評価されるため)、実際には変化がない部分が変化ありと判断されたり、逆に変化がある部分が検出されなかったりする誤判定が発生しやすくなる
◾️データセット
①ALOS-2/PALSAR-2データ
・豪雨前と豪雨後の観測データを比較し、バックキャッタ係数に変化が生じた場所を検出するために使用
②DEMデータ(デジタル標高モデル)
・ALOS-2データと組み合わせることで、どの部分で斜面崩壊が起きやすいかを詳細に解析するために使用
③光学航空画像データ
・検証用データとして利用
・災害前後のDEMデータと組み合わせて、視覚的に地表の変化を確認する
④土地利用マップ
・ 例えば、森林エリアと田畑エリアでは、反射される電波の強さが異なるため、土地利用情報を使ってSARデータのノイズを抑え、より正確な崩壊検出を実現する
◾️本手法のアプローチ
①ALOS-2データの前処理とバックキャッタ係数の差分計算
・バックキャッタ係数の変化をもとに、豪雨による地表変化を抽出するため、ALOS-2データの品質を向上させ、精度の高い解析を行う準備を行う
・まず、SARデータはスペックルノイズに影響されやすいため、「Multilooking」と「Leeフィルタ」を使ってノイズを減少させる
・次に、 複数のALOS-2画像を正確に重ね合わせ、位置情報がずれないように調整する
・地理的な歪みを補正し、観測データが地形に対して正確になるように調整する

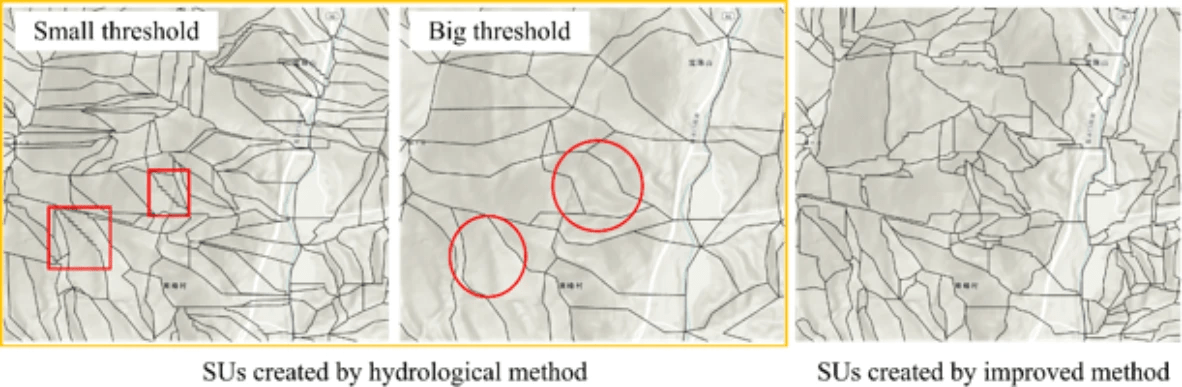
② 斜面単位の改善
・豪雨による斜面崩壊をピクセル単位で分析するのではなく、地形の特性を反映した「斜面単位(SU)」を基に分析することで、崩壊範囲をより正確に検出する
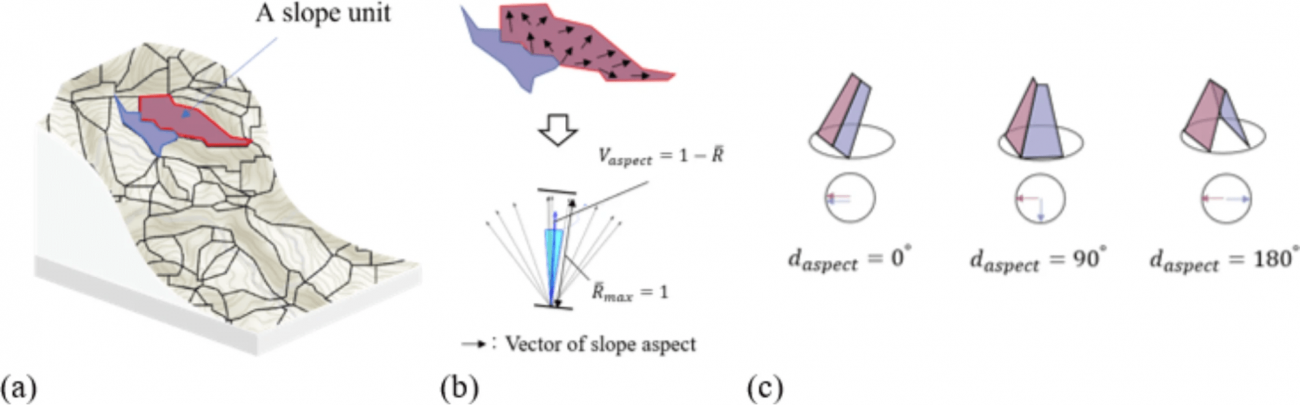
※斜面単位(SU: Slope Unit)とは・・・斜面の特性(斜面方位や角度)が均一である範囲を1つのまとまりとして定義した単位であり、従来のピクセル単位(地表を均一なグリッドで区切る方法)では対応が難しい、地形の自然な構造や特性を考慮することができる
・具体的には、各SU内で斜面方位と角度のばらつきを計算し、斜面の向きや勾配が均一である範囲をSUとして定義する
・その際に、隣接するSU同士で斜面の向きや角度に大きな違いがある場合、それは尾根や谷などの地形的な境界であることを示しており、それら情報を使って、過剰な分割を避け、自然な地形に沿ったSUを作成する
③閾値設定法
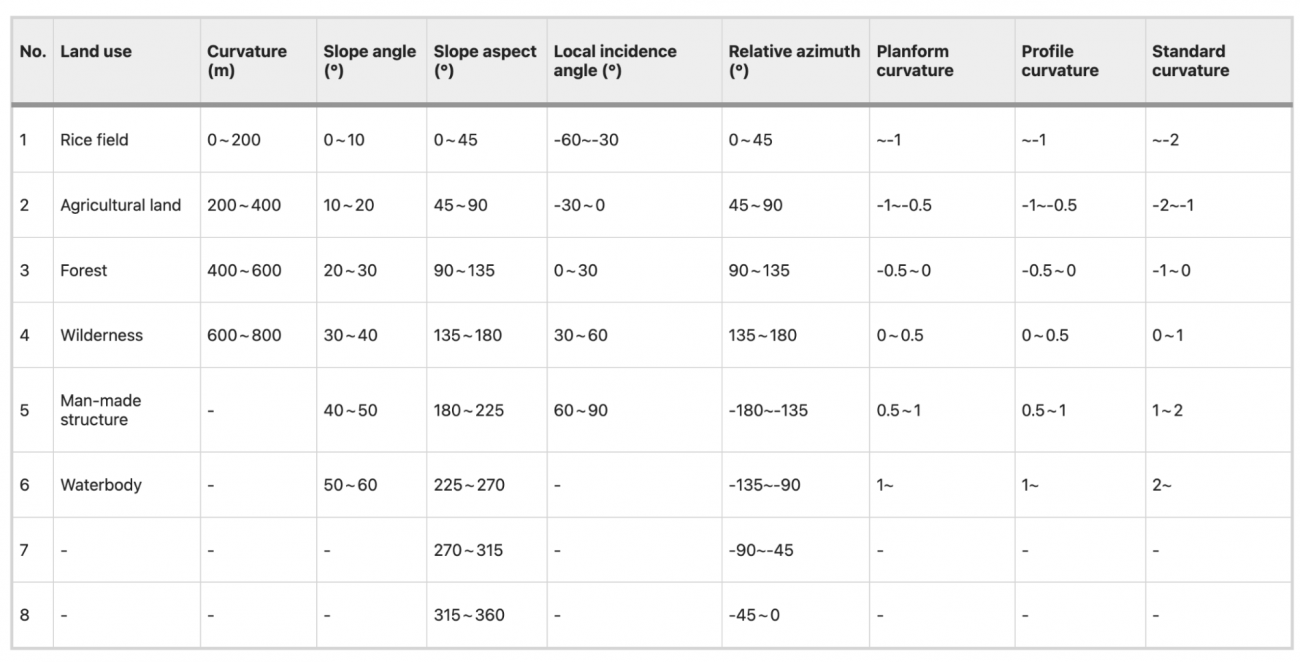
・SARデータのバックキャッタ係数は、観測条件や地形条件などにより異なるため、一律のしきい値では正確な変化検出が難しいことが課題な中で、豪雨後の斜面崩壊領域を迅速かつ高精度で抽出するため、特定の地形条件や観測条件に応じたしきい値を設定する
・まず、豪雨後の観測データから、地形データ(DEMデータ)や土地利用データ(MLIT提供)から取得した影響要因(土地利用状況、標高、斜面角度、斜面方位、局所入射角、相対方位角を考慮し、それぞれの条件が地表変化の抽出にどのように影響するかを解析する
・次に、豪雨後の観測データと定期観測されたALOS-2データから、バックキャッタ係数の差分データを11種類作成し、各ピクセルに対して影響条件の情報を割り当てる(本データは、異なる条件下でのバックキャッタ係数の変化を示し、各条件の影響を考慮したしきい値設定の基盤となる)
・ANOVA(分散分析)を用いて、各条件がバックキャッタ係数の変化にどの程度影響を与えるかを評価する
・各条件の分類ごとに、バックキャッタ係数の差分データの中央値や平均値を計算し、しきい値として設定する
④密度比推定法
・豪雨後に異常な変化が見られる箇所(斜面崩壊など)を検出するため、SARデータの「密度比」を計算して、通常のデータから外れた領域(アウトライヤー)を特定し、スペックルノイズなどの影響を軽減しながら、正確に異常領域を抽出する
・密度比推定に基づいて抽出されたデータを、PR(Precision-Recall)曲線を用いて評価する
【議論の内容・結果は?】
◾️斜面単位の方位と角度のばらつきの改善効果
・Vaspect (a)~(c):改良手法により、斜面の方向が均一な範囲(Vaspectのばらつきが小さいエリア)が増加し、地形特性に沿った一貫性のある単位で分割ができるようになっている
・Vslope (d)~(f):斜面角度のばらつきも減少し、均一な傾斜を持つエリアが多く生成されていて、滑らかで実際の地形に適合した斜面単位の分割が可能になっている
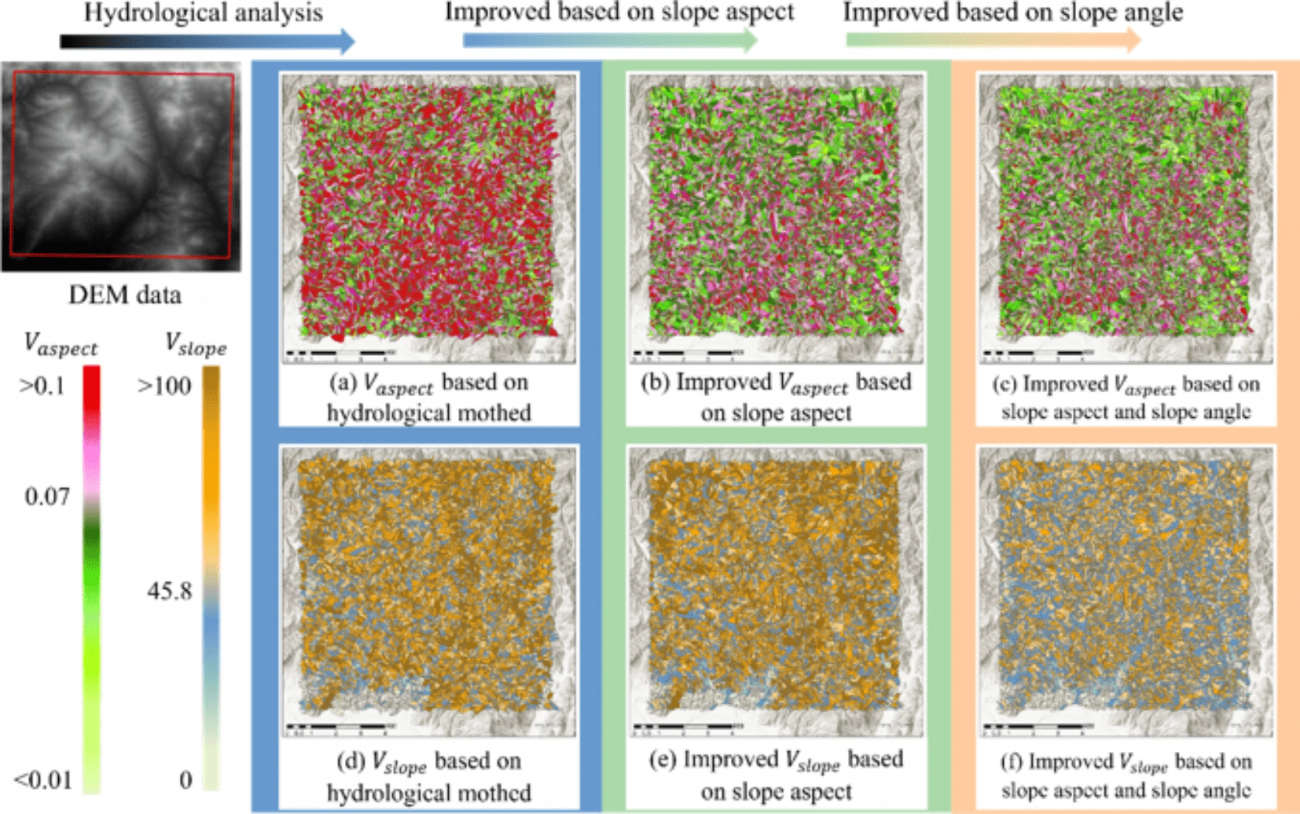
・しきい値設定による過剰分割や統合の問題を防ぎ、地形に合った正確な斜面崩壊リスク領域を抽出できている
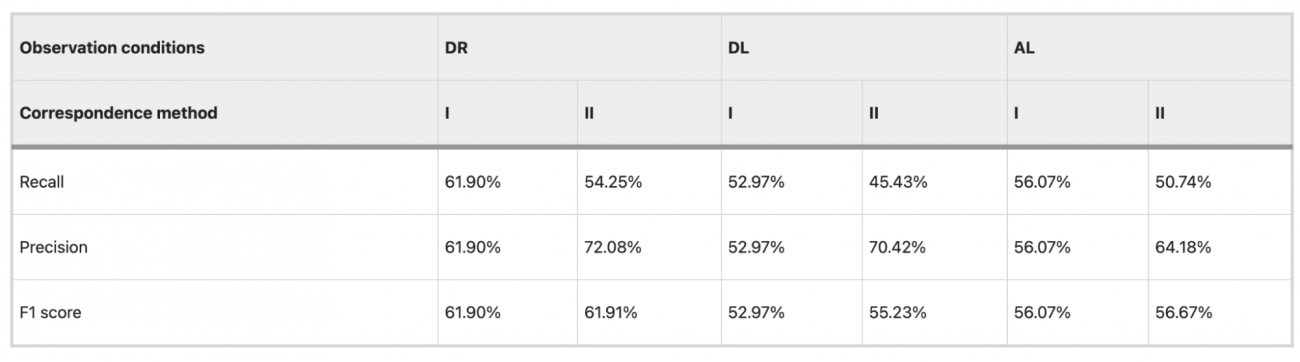
◾️Method IとMethod IIの比較
①前提
・Method I:災害前後のバックキャッタ係数の変化量に基づいて単純に変化領域を抽出する方法で、災害前後のデータの直接的な差分を使って検出する
・Method II:土地利用、標高、斜面角度、局所入射角などの影響条件を考慮した抽出方法で、災害影響を受けやすい環境要因を含めて精度を向上させる
② DR方向での比較結果
・Precision(精度):Method Iでは61.90%に対し、Method IIでは72.08%と、Method IIが約10.18%向上
・Recall(再現率):Method Iは61.90%に対し、Method IIは54.25%と、Method Iがやや上回っています。
・F1スコア: Method IとMethod IIはどちらも61.90%で同等
・Method IIは影響条件を考慮することで精度が向上し、特定の条件での誤検出が減少する傾向が見られた一方で、再現率がやや低下しており、一部の真の変化が見逃される可能性がある
・つまり、影響条件を考慮することが精度向上には寄与しているが、適用するエリアや条件により誤検出が増える可能性を示唆している
③異なる観測方向(災害前後でDLまたはAL方向のデータを使用)
・PrecisionとRecall: Method IではDL方向で52.97%、AL方向で56.07%の精度と再現率を示したが、Method IIではDL方向で45.43%、AL方向で50.74%と、約50%が誤分類される結果となった
・影響要因: DL方向での観測間隔が434日、AL方向では266日と観測間隔が長いため、土壌水分や季節変動、植生の変化が追加的に含まれてしまい、災害による変化以外も検出されてしまう傾向が見られた
・上記結果から、長い観測間隔や異なる観測方向でのデータを使用する場合、Method IIでは誤検出が増加しやすい傾向が確認でき、データの観測間隔や方向が一定である方が、Method IIの精度は安定しやすいと考えられる
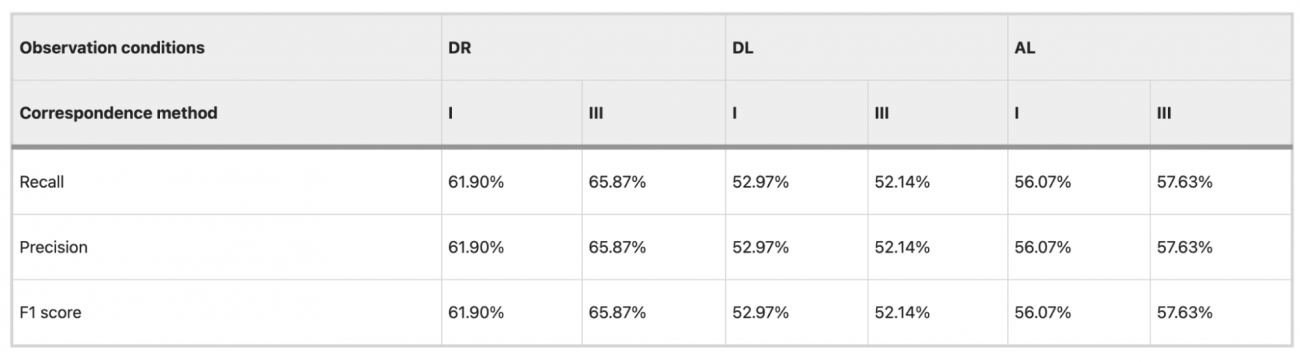
◾️Method IとMethod IIIの抽出結果
①前提
・Method I:災害前後のバックキャッタ係数の変化量に基づいて単純に変化領域を抽出する方法で、災害前後のデータの直接的な差分を使って検出する
・Method III :豪雨後の斜面崩壊や地表の急激な変化を捉えるために、通常の地表状態と災害後の異常な変化を密度比推定法で区別する
②DR方向での比較結果
・DR方向の観測条件下で、Method IIIはMethod Iに比べて精度と再現率が約4%向上し、全体的なF1スコアも向上していることが示されている
・つまり、Method IIIは特にDR条件下での斜面崩壊領域の抽出精度が優れていることがわかる
③異なる観測方向(災害前後でDLまたはAL方向のデータを使用)
・異なる観測条件(DLやAL方向)では、Method IIIはMethod Iに比べて精度がわずかに低下した
・観測条件の違いにより密度比推定の精度が変動することが確認され、特に観測間隔が長くなると他の環境要因が影響して誤検出が増える傾向が示唆されている
#PALSAR-2 #DEM #ALOS-2 #ANOVA #密度比推定法 #スペックルノイズ #災害 #バックキャッタ係数 #豪雨
Space-Based Mapping of Pre- and Post-Hurricane Mangrove Canopy Heights Using Machine Learning with Multi-Sensor Observations
【どういう論文?】
・本論文は、ハリケーン後のマングローブ樹冠高をマルチセンサーで推定する手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
①カバレッジと迅速な影響評価の限界
・先行研究で最も精度の高いとされる空中LiDARは、局地的な小規模エリアでの観測に限定され、広範囲での即時的な損失評価が難しい
・特にハリケーンなどの突発的な自然災害後には、即時のデータ取得が難しく、タイムリーな影響評価が困難である
②単一データタイプの限界
・樹冠高(CH)の推定には、光学データやSARデータの単一データタイプを用いる研究が一般的であったが、各データは得意な観測条件が異なり、正確な樹冠高予測をするには限界があった
・例えば、光学データは葉の茂った状態の特徴を捉えやすく、SARデータは木の幹や枝に反応するため、樹冠の状況に応じて適切なデータが変わるという課題がある
③時系列情報の活用不足
・多くの研究では、SARバックキャスター(レーダー信号の反射データ)の時間平均や中央値を使うことが一般的だが、その結果としてデータが「平均化」されてしまい、細かな時間変動が見えにくくなっている(例えば、潮の満ち引きによる影響など、マングローブの変化に影響する重要な要因が反映されにくい)
・特に浸水しやすいマングローブエリアでは、水位変動が大きな要因となるため、単一のバックキャスター画像だけでは偏りが生じる可能性がある
④転移学習の応用不足
・空間転移学習(異なる地理的エリアへのモデル適用)は行われていたが、時間転移学習(異なる時間のデータへのモデル適用)は少なく、災害後の迅速な影響評価には不十分であった
・特に、マングローブ構造が災害後に著しく変化するため、異なる時期へのモデル適用には困難が伴う
◾️研究地域とハリケーンの影響
①対象地域
・南フロリダのエバーグレーズ国立公園沿岸部
・米国内で最大のマングローブ保護区(約1296 km²)で、さまざまな種類のマングローブが生育している
②ハリケーン・イルマ
・2017年に南フロリダを襲ったハリケーンで、沿岸部のマングローブに特に被害をもたらした
◾️データセット
①G-LiHT LiDAR
・NASAが提供する空中LiDARデータで、樹冠高モデル(CHM,基準データ)として使用する
・ハリケーン前(2017年3月)と後(2017年12月)の樹冠高データを収集し、(元々のG-LiHT LiDARの)1m解像度データを、Landsatの30 mグリッドにリサンプリングして、SARや光学データと合わせて使いやすくしている
②Vegetation Cover and Mangrove Classes
・エバーグレーズ国立公園内のマングローブをL3(一般分類)とL4(種別分類)に区分し、異なる高さや種別のマングローブ分布を詳細に分類した
・種ごとの成長特性や高さの違いをモデルで反映し、より精緻な樹冠高予測を実現する
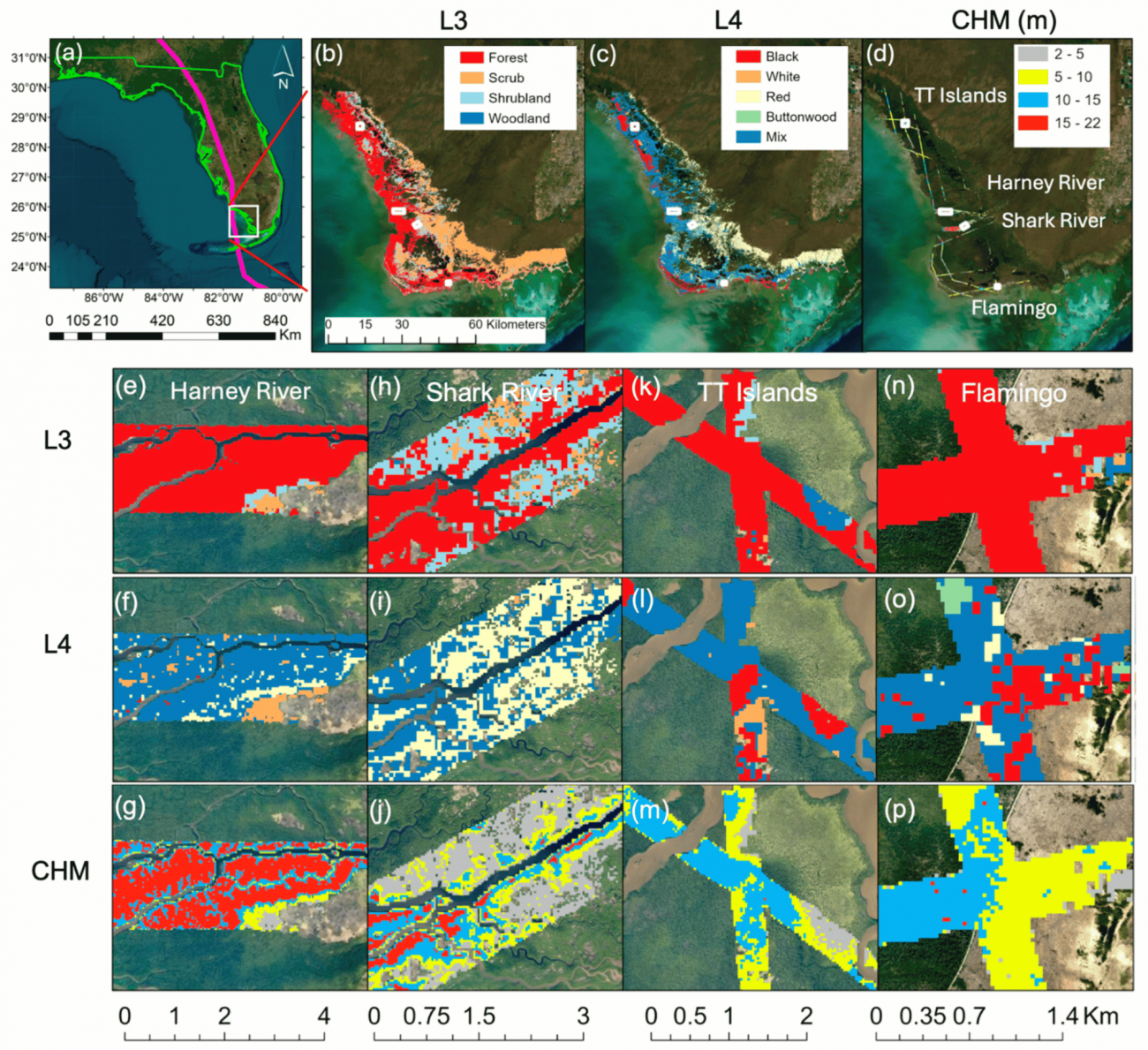
③Sentinel-1 SAR Data
・レーダー反射(VV・VH偏波)を利用し、ハリケーン前後で時系列の反射値データを収集
・潮汐変動や水位の影響を考慮し、SAR時系列の反射値変動も含めたデータを準備する
④Multispectral Optical Data
・RGBや赤外線などのバンドデータと、NDVIなどの植生指標を含む変数を使用する
・雲の影響が除去され、マングローブ樹冠の状態が可視化されている
◾️アプローチ
①データ準備
・まず、研究対象地域全体のピクセルを含む元データセット「DS0」を構築する
・本データセットには、「特徴変数」と「ラベル変数」の2種類が含まれる
・特徴変数とは、SAR(レーダー反射)、光学データ(Landsat)、およびマングローブの分類マップによるデータになる
・ラベル変数とは、G-LiHT LiDARから得られた樹冠高(CH)データであり、実際の高さを示す基準データとして使われる
②DS0のフィルタリング
・光学データにおける雲被りや欠損部分を除外し、有効なデータのピクセルのみを抽出する
・上記により、ハリケーン前後の期間別にフィルタリングされた「DS1_pre(ハリケーン前)」と「DS1_post(ハリケーン後)」のデータセットを作成することができる
・更に、樹冠高2m以上のピクセルに限定し、さらにハリケーン前後のデータを共通する位置(ピクセル)で合わせ、「DS2(共通データセット)」を作成する
③ランダムフォレストモデルの訓練
・ランダムフォレストは、他のモデル(多変量線形回帰、ディシジョンツリー、SVMなど)と比較して高精度を示したため利用する
④空間的転移学習(Spatial Transfer Learning)
・SARデータ、光学データ、それらの組み合わせたデータセットの3つのパターンを用いて、ハリケーン前後のデータでそれぞれ予測精度を比較する
・更に、高さ(2–5 m、5–10 m、10–15 m、15–20 m)に分け、各クラスごとにモデルの予測精度を評価する
・上記結果から最も精度の高かった特徴セットを使用し、全ピクセルでのモデル訓練と予測を行う
・LiDAR基準データと比較して、ハリケーン後の樹冠高変化の正確性を検証する
⑤時間的転移学習(Temporal Transfer Learning)
・④と同様に行う
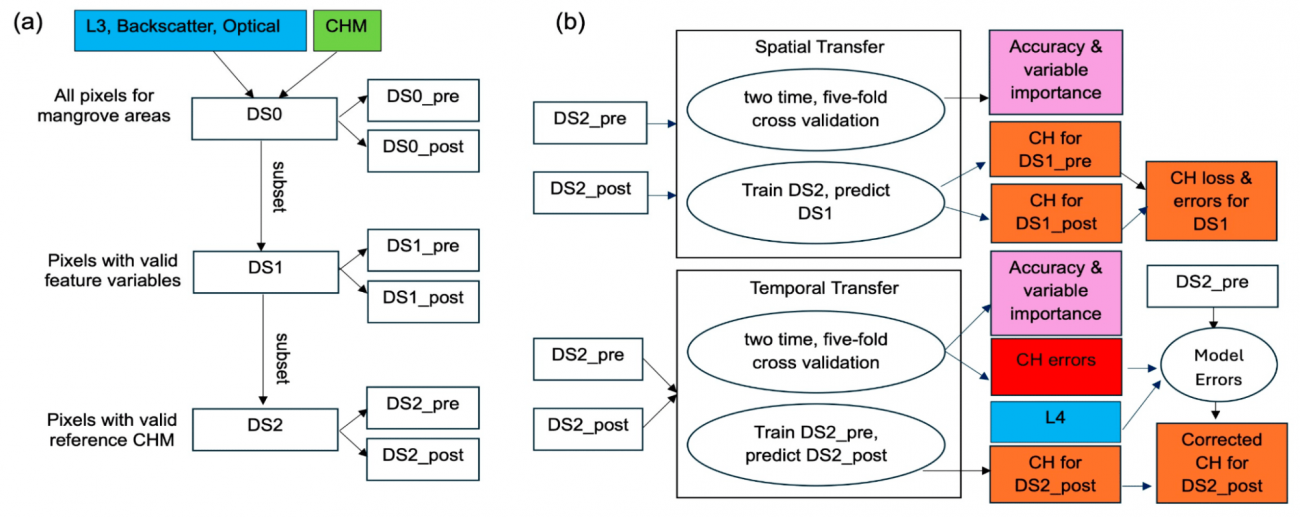
【議論の内容・結果は?】
◾️ハリケーンによる樹冠高の変化
・図aのボックスプロットは各種のハリケーン前後におけるCH分布を示しているが、、中央値(赤線)や四分位範囲(ボックス)からもCHの低下が視覚的に確認でき、特に、「Black Mangrove」や「Red Mangrove」のような種別でCHの低下が顕著である
・つまり、「Black Mangrove」や「Red Mangrove」などの高さが高い種は風や潮による影響を強く受けやすいため樹冠高の減少が顕著であり、「Buttonwood」のように元々の高さが低い種は相対的に影響が小さかったことが示されている
・図bでは、ハリケーン後、高CH損失のピクセルではSARのバックキャスター(反射値)が増加し、光学指標が減少する傾向を確認できる
・つまり、SARは樹冠内部や幹・枝の構造に影響を受けやすく、葉が失われた後も構造の変化を反映する一方、光学データは葉の存在が反射や指標に大きく影響を与えるため、災害後の葉が少ない状態では精度が低下しやすいという特徴が示唆されている
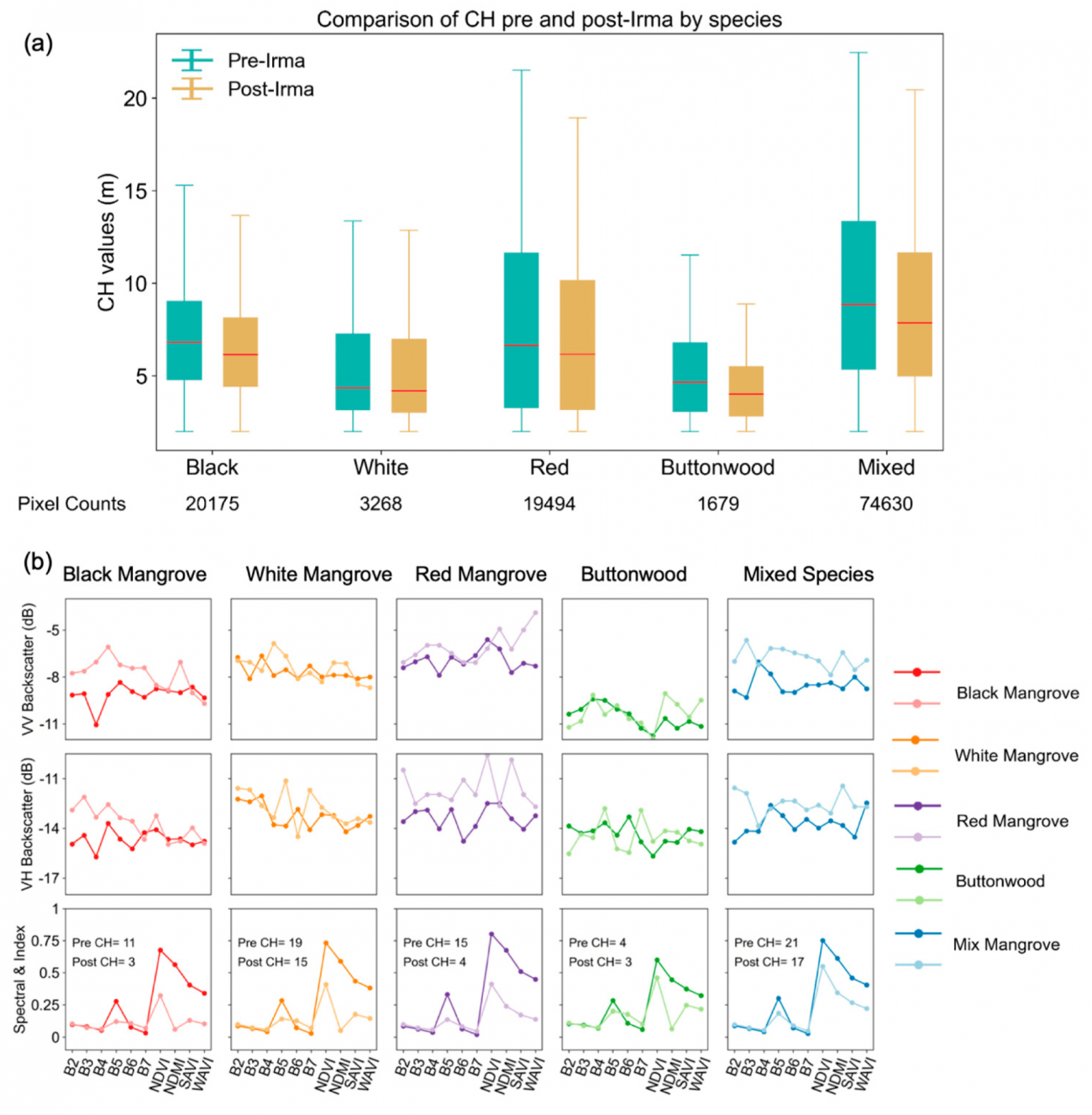
◾️空間的転移学習の結果
①樹冠高予測と実測値の散布図
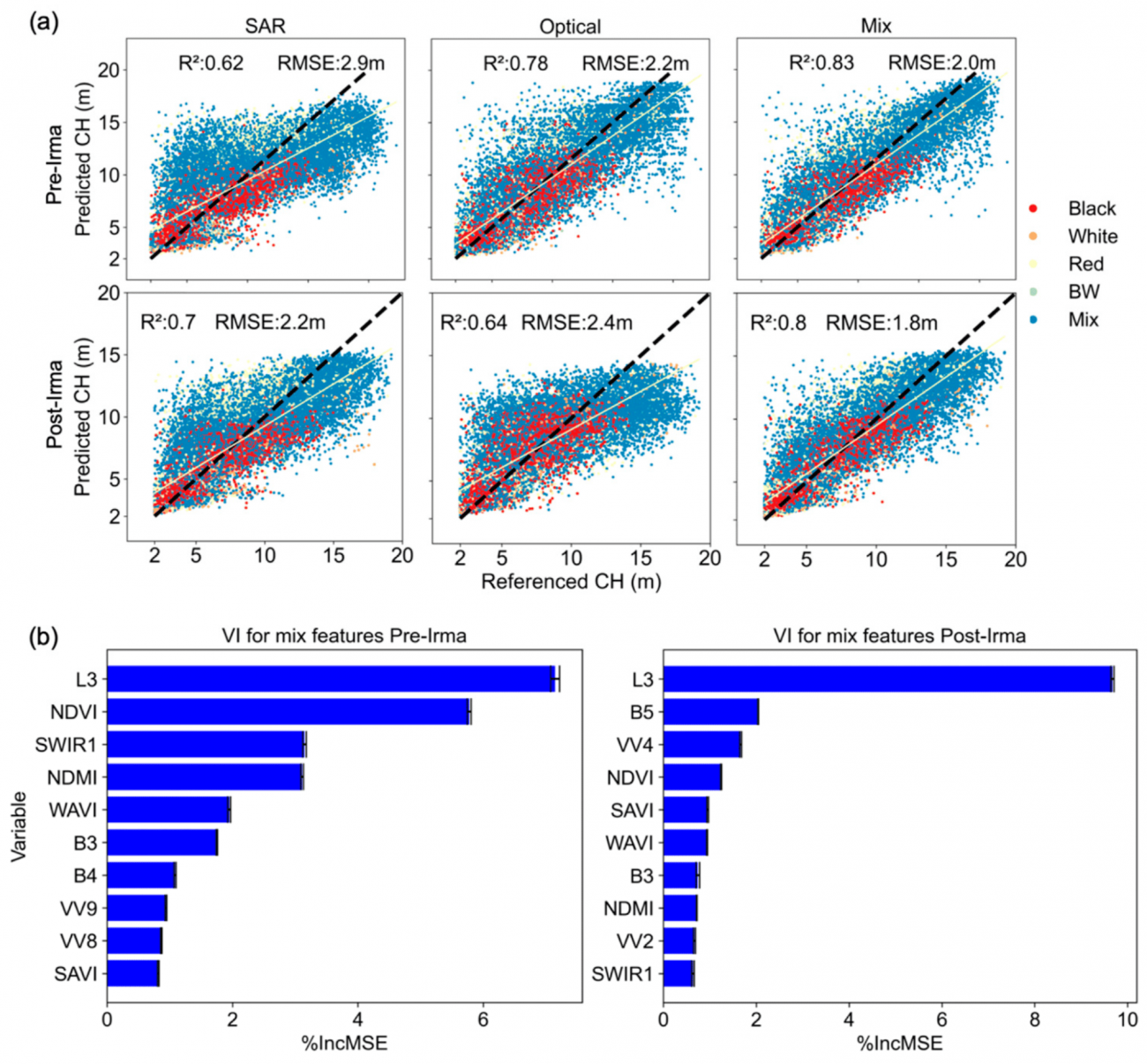
・以下の図aによると、混合データに関しては、ハリケーン前後でRMSEがそれぞれ1.9mと1.8mと低く、R²が0.8で高い相関性を持っている
・上記に対して、SARデータ単体のRMSEはハリケーン前後で2.9mと2.2m、光学データ単体では2.2mと2.4mと、混合データに比べて精度が劣る
・つまり、混合データの方が、単一のセンサー(SARまたは光学データ)のみを使う場合に比べて一貫して高い精度で樹冠高を予測できることである
②重要変数のランキング
・図bは樹冠高予測モデルにおける各変数の重要度を示したグラフとなっていて、モデルに含まれる変数のうち、予測精度に対する影響が大きい変数が上位にランクされているが、L3分類(植生のタイプに基づく大まかな分類)が最も高い重要度を持っていることがわかるのと同時に、NDVI(Normalized Difference Vegetation Index)とSARのVV(垂直-垂直)バックキャスターも高い重要度を示していることがわかった
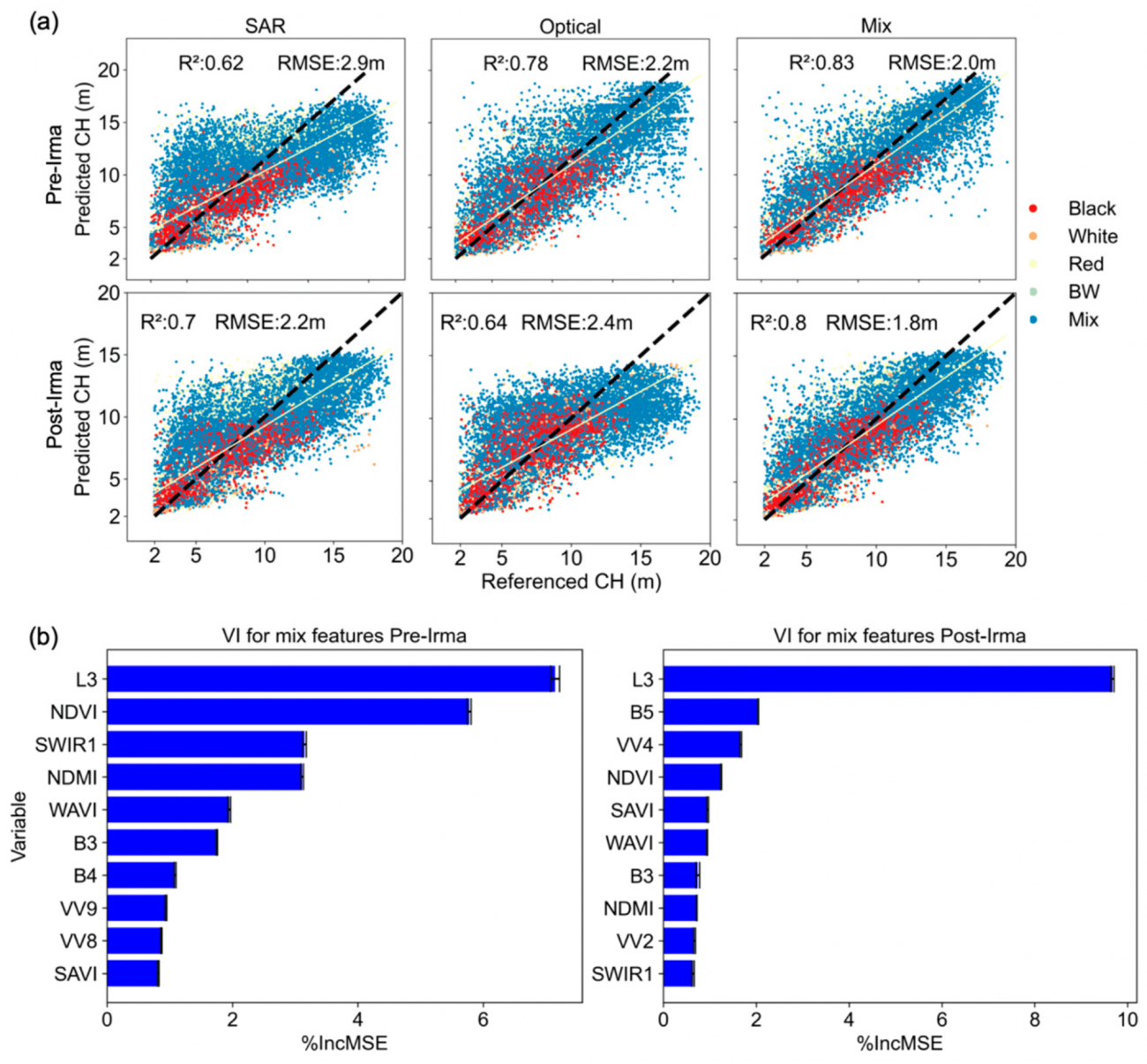
③樹冠高クラスごとの予測精度
・樹冠高クラス別で見ると、2–5 mクラスのRMSEは混合データで1.6m、SARと光学データ単体で2.0mとなっている
・15–20 mクラスでは混合データのRMSEが3.1m、SARが3.9m、光学データは5.0mと、樹冠高が増すにつれ混合データの優位性がより顕著になる
・このため、空間転移学習で異なる樹冠高の予測には混合データが適していると考えられる
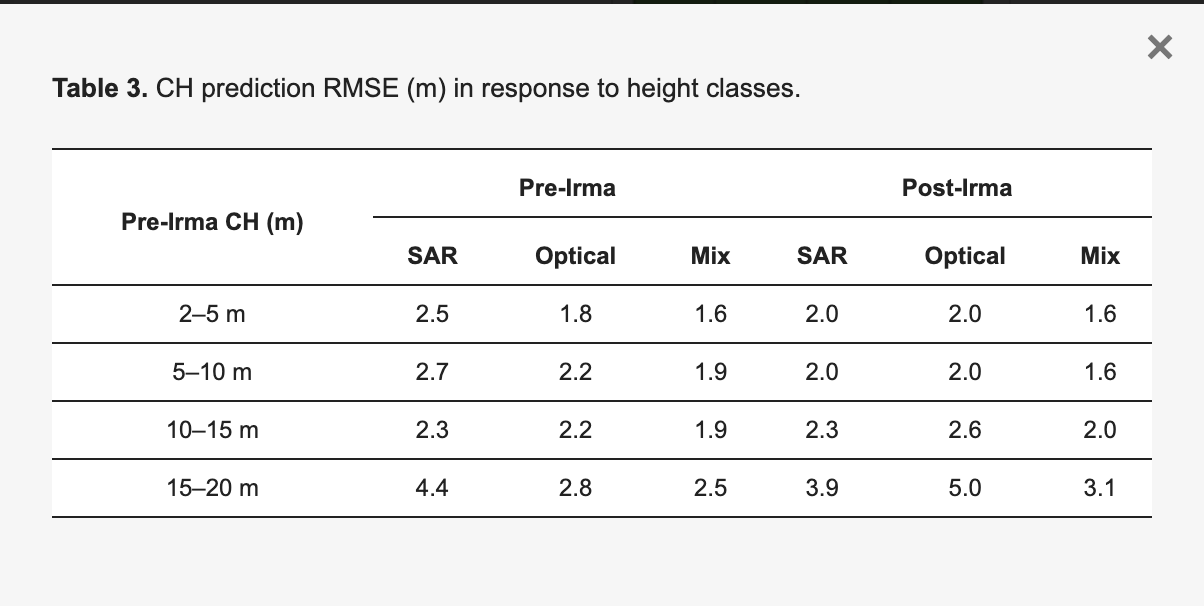
◾️時間的転移学習の結果
①樹冠高予測と実測値の散布図
・時間転移学習でのSARデータのRMSEは、高木(10 m以上)で2.9mと高い精度を示しており、光学データや混合データよりも優れている
・上記により、災害後の早期評価においてSARが有効であることが示されている
・短木に対しては、SARは高さを過大評価する傾向があり、光学データの方が精度が高いことが確認できた
②重要変数のランキング
・図8bの重要変数ランキングによると、L3分類(植生のタイプ)がCH予測において最も重要な変数として評価された
・また、SARデータのVV変数がVH変数よりも一貫して重要度が高いことがわかった
・VV成分が樹木構造の変化に対して特に敏感であり、樹冠高(CH)予測に寄与していることを示している
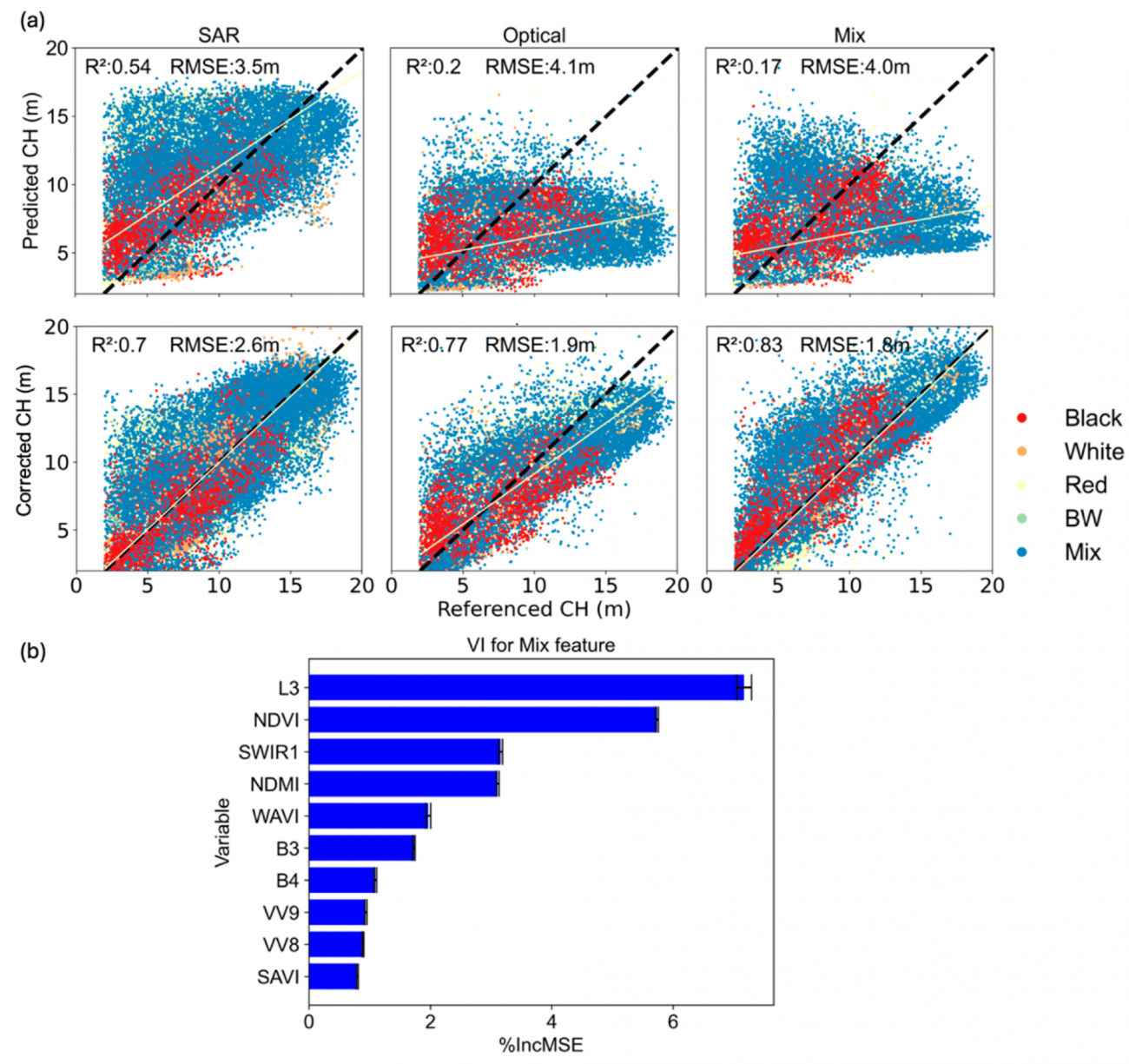
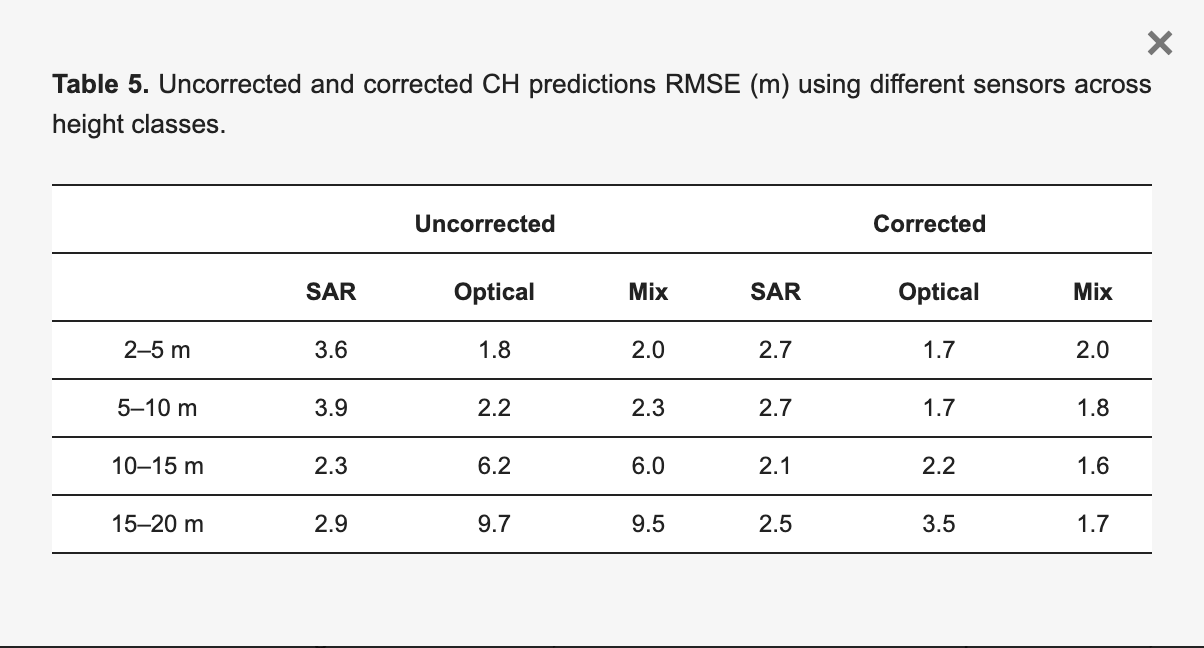
③樹冠高クラスごとの予測精度
・未修正の場合(予測モデルが直接的に出力した予測値をそのまま使用した場合)は、15–20 mのクラスでSARは2.9m、光学データは9.7mと大きな差が見られた
・一方で、修正後(予測誤差を補正するためのモデルを適用した結果)はSARで2.5m、光学で3.5mに改善された
・また、混合データでは修正後のRMSEが1.7mと最も低くなっている
・上記により、時間転移学習では、データを修正することで、特に高木に対して精度が向上し、時間経過による樹冠高の変化を反映した予測が可能になることがわかる
#マングローブ #ハリケーン #G-LiHT-LiDAR #ランダムフォレスト #空間的転移学習 #NDVI #高木 #光学 #短木 #SAR #樹冠高
Enhancing spatial resolution of satellite soil moisture data through stacking ensemble learning techniques
【どういう論文?】
・本論文は、スタッキングアンサンブル学習を用いて衛星土壌水分データの空間解像度を高める手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
①空間解像度の不足
・衛星による土壌水分観測は地球規模の大規模モニタリングに役立つ一方、従来のマイクロ波センサーでは解像度が粗く、9〜50km程度の空間解像度に留る
・例えば、Soil Moisture Active Passive (SMAP)のL4製品(データセット)は9kmの解像度だが、農業や水管理などの現場では、1km以下の詳細な情報が求められる
②ダウンスケーリング技術の課題
・土壌水分データの解像度を上げるため、さまざまなダウンスケーリング手法が提案されてきたが、各手法には限界がある
③解釈可能性の欠如
・機械学習モデルのブラックボックス性により、予測の背後にある変数の影響やモデルの判断基準が不透明になるという課題がある
④単一モデルの限界とアンサンブル学習の必要性
・単一の機械学習モデルでは、特定の環境やデータ特性に依存し、異なる条件下での精度や安定性が低下することがある
◾️データセット
①地上測定データ
・乾燥地、半乾燥地、農地の各地形で5cm深度の水分量を測定したもの
・ 2020年9月20日から10月26日まで毎日測定し、朝と午後の2回のセッションを実施した
②SMAP放射計土壌水分データ
・SMAP L4製品は3時間ごとに更新される9km解像度の土壌水分データであり、大域的な土壌水分の動態を把握するための主要なデータセットである
・これをダウンスケーリングすることで、1km解像度での詳細な地域土壌水分分布の予測を可能にする
③AMSR2土壌水分データ
・ JAXAがGCOM-W1衛星に搭載して提供する10 km解像度のAMSR2/GCOM-W1 surface soil moistureデータ
・SMAPと同様に粗い解像度ですが、SMAPとは異なるマイクロ波データと処理方法を利用しており、異なるデータソースとして予測の精度向上に寄与する
④MODIS製品
・: MODIS(Terra・Aqua衛星搭載)のNDVI(植生指数、250m解像度)とLST(地表面温度、1 km解像度)データを活用する
・これにより、植生や気温の影響を考慮したダウンスケーリングが可能となる
⑤降水データ
・降水量は土壌水分に直接影響を与えるため、日々の変動を反映する重要な要素である
・降水データを加えることで、気象条件が土壌水分に与える即時的な影響をダウンスケーリングモデルに反映させ、予測精度を上げる
⑥地形データ
・地形データ(標高、傾斜、方位)は土壌水分の空間分布に大きな影響を与えるため、地形特性をダウンスケーリングモデルに組み込むことで、地形効果を反映した予測が可能となる
⑦土壌特性データ
・ 土壌の物理的な性質や水保持能力は、土壌水分の蓄積や移動に大きく影響する
◾️手法
①データ準備
・各データセットを1 km解像度にリサンプリングし、土壌水分ダウンスケーリングでの空間的な一貫性を確保する
・欠損値処理やスケーリング(MinMaxScalerでの標準化)を行う
②モデル学習
・10種類の機械学習モデル(Random Forest、XGBoost、Gradient Boosting、SVM、K-Nearest Neighbors、Multi-Layer Perceptronなど)を用いて、土壌水分と環境変数との関係を学習する
③モデル選択
・RMSE(誤差の平均平方根)、ubRMSE(バイアスのないRMSE)、R2(決定係数)などの指標でモデルのパフォーマンスを評価・ランク付けする
・選ばれた上位モデル(通常6つ)を最適化し、次のアンサンブル学習に使用する
④ハイパーパラメータチューニング
・ベイズ最適化を活用して、各モデルのハイパーパラメータを調整し、最適なモデルパフォーマンスを引き出す
⑤スタッキングアンサンブル学習
・スタッキングアンサンブル学習では、基礎モデルの出力をメタモデル(上位モデル)に統合し、土壌水分の最終予測を行う
・各モデルの出力を統合し、異なるモデルが持つ予測の強みを引き出すことで、個々のモデル単体よりも高い精度と安定性を実現する
⑥精度評価とSHAP解析
・R2、RMSE、ubRMSE、バイアス(予測誤差の偏り)などの指標を用いて、予測の精度と信頼性を検証する
・SHAP(Shapley Additive Explanations)解析により、各モデルや特徴量の影響を定量化し、モデルの解釈性を高める
・SHAPはゲーム理論に基づいており、特に「Shapley値」という概念を応用しており、Shapley値は、各特徴がモデルの予測にどのように貢献しているかを公平に分配するための手法となっている
【議論の内容・結果は?】
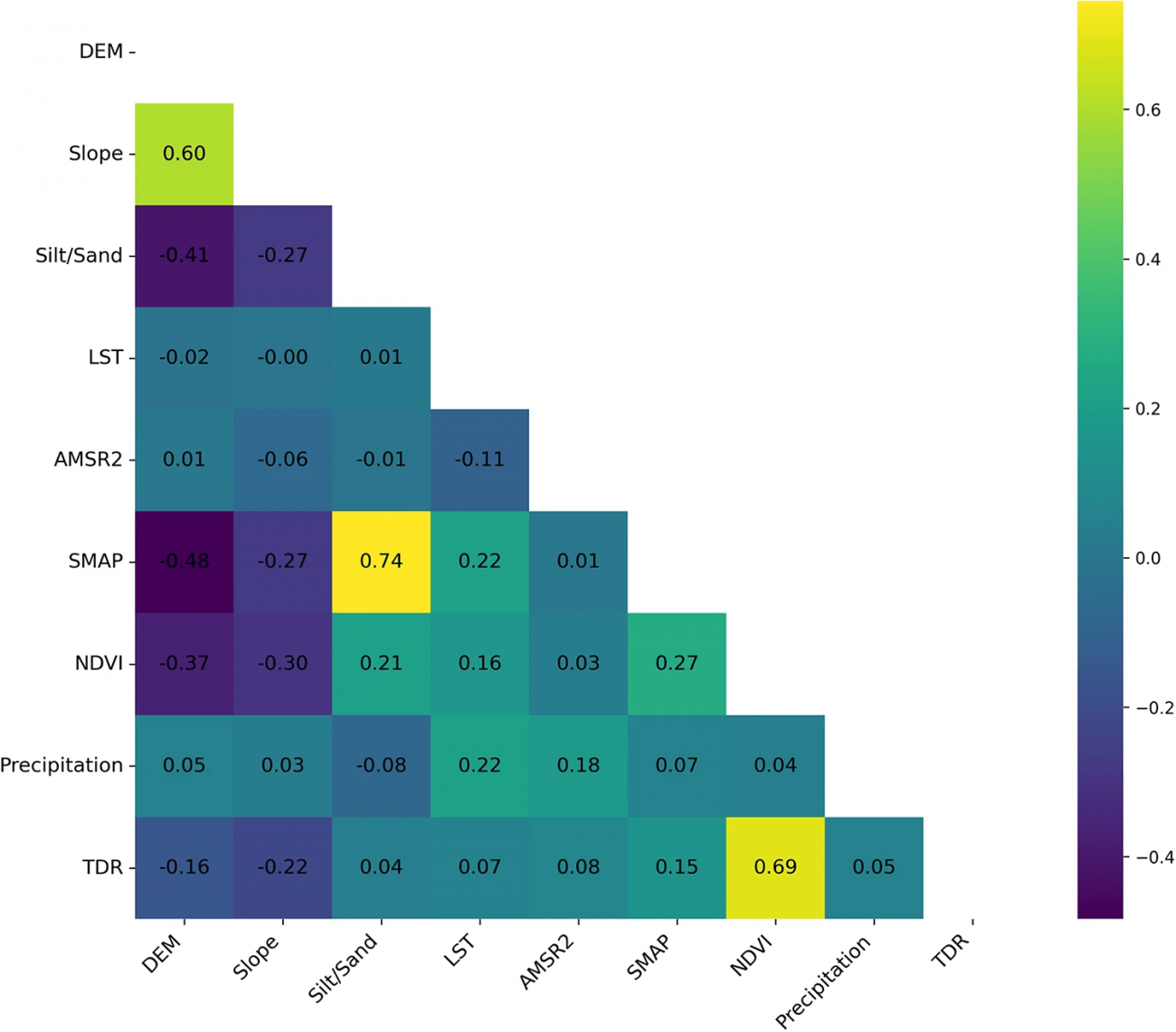
①特徴量間の相関関係
・SMAP土壌水分データと土の粘土比(r=0.74)、降水量と地表温度(r=0.69)は強い正の相関を持っていて、粘土含有量の高い地域では水分保持力が強く、温暖な環境では降水が増える傾向があることがわかった
・ 標高と土壌水分はr=0.60の相関があり、地形の勾配が土壌水分の分布に影響を与える可能性がある
・NDVI(植生指数)と標高および粘土比は負の相関(それぞれr=-0.37とr=-0.30)を示し、植生密度が高い場所は低地や細かい土壌に多いことが分かった
②モデル評価と選定
・ RMSE、ubRMSE、R2の3つの指標でモデルを評価し、各指標に重みを割り当てた(RMSEとubRMSEが25%、R2が50%)
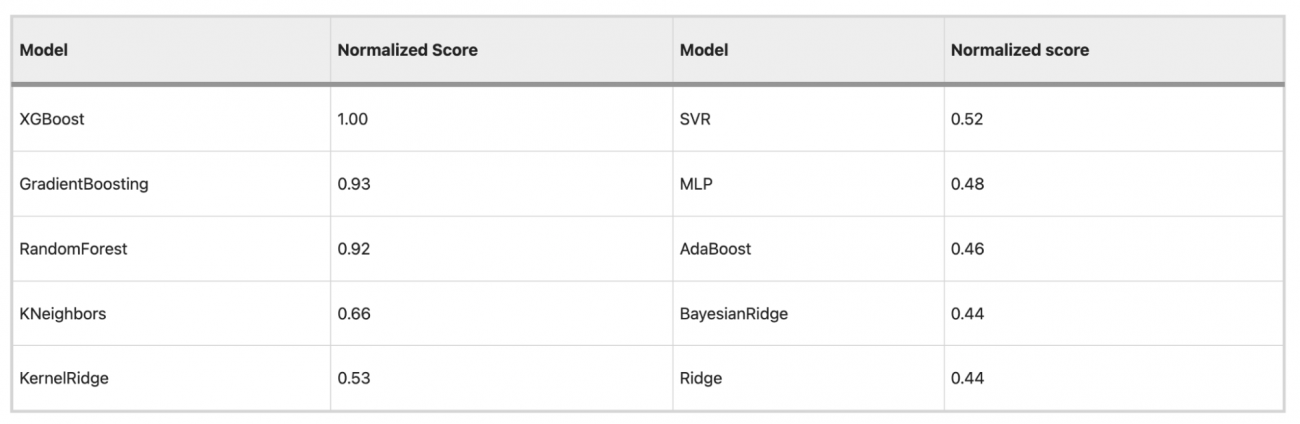
・XGBoostがトップパフォーマンスを示し、勾配ブースティングとランダムフォレストがこれに次ぐ結果となった
・上記3つは非線形な関係性を捉える力が強く、複雑なデータに適している
・K近傍法やカーネルリッジも候補として残ったが、伝統的な線形モデル(RidgeやBayesian Ridge)はやや低い性能を示した
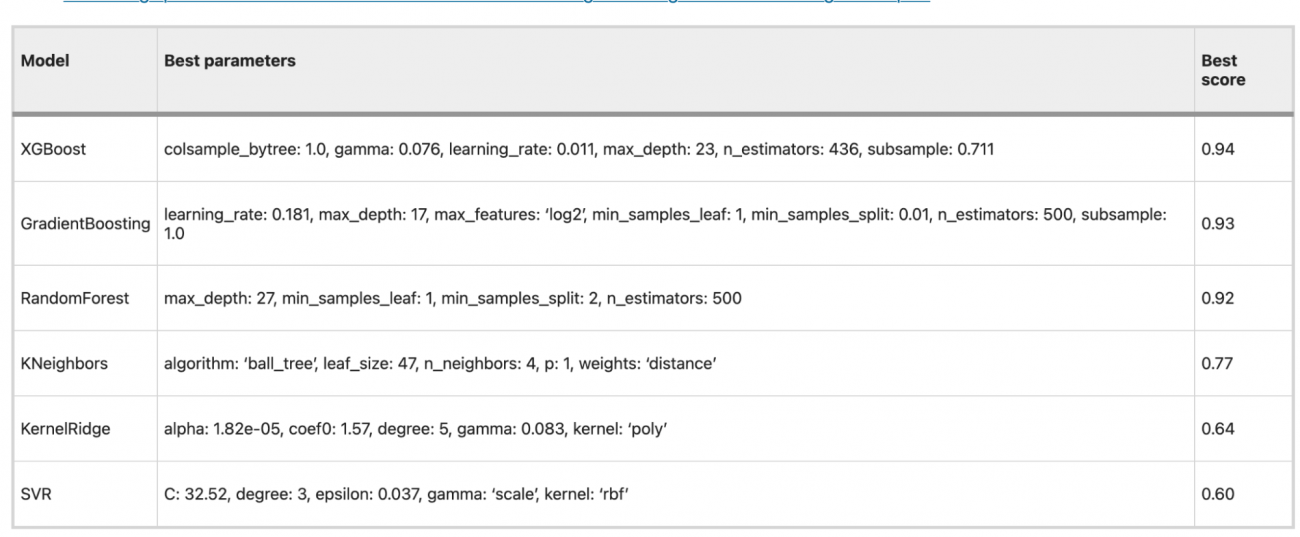
③ハイパーパラメータの最適化
・BayesSearchCVを使用して各モデルのハイパーパラメータを調整し、精度の向上を図った
・XGBoost、勾配ブースティング、ランダムフォレストが特に高い精度(それぞれ0.94、0.93、0.92のスコア)を記録した
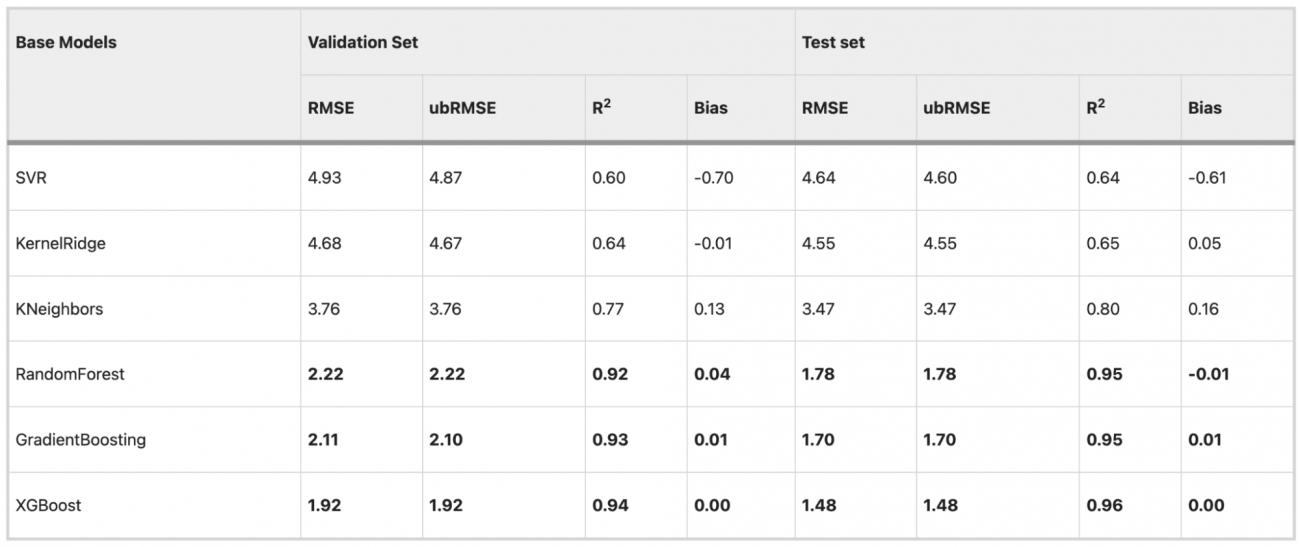
④ベースモデルの性能評価
・サポートベクター回帰、カーネルリッジ、K-最近傍法、ランダムフォレスト、勾配ブースティング、およびXGBoostの6つの機械学習モデルが、衛星の土壌水分データのダウンスケーリングにおいて優れた性能を発揮するベースモデルとして選出された
・その中でも、XGBoostは、最も低いRMSEとubRMSE値、および最高のR²スコアを示し、優れた予測精度と一貫性を示した
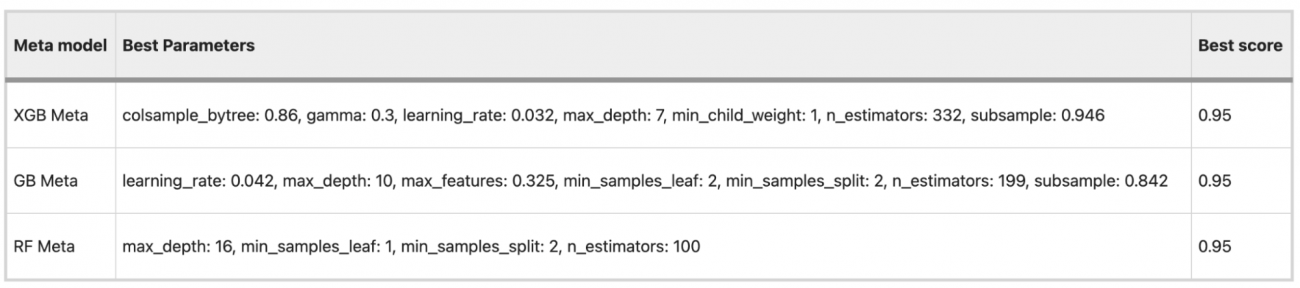
⑤アンサンブル学習(スタッキング)
・ベイズ最適化を用いて調整された各メタモデルの最適なハイパーパラメータは以下の通りである
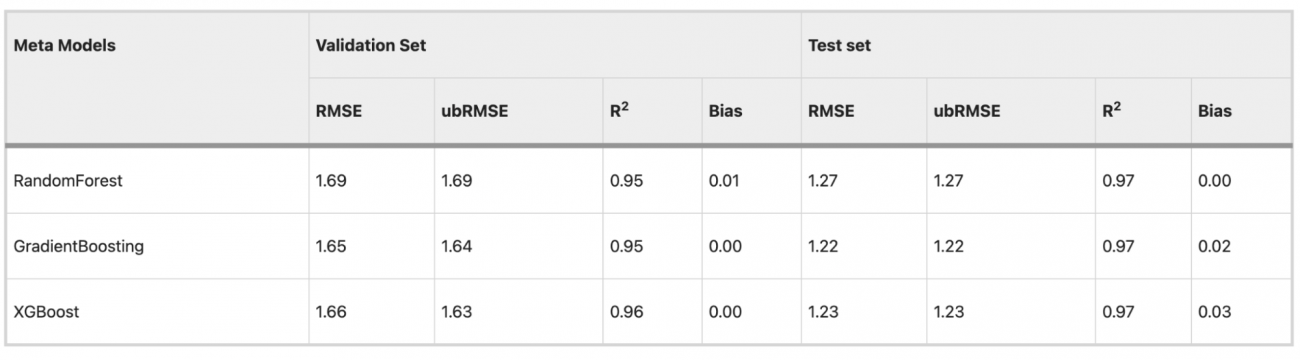
・ランダムフィレストメタは、テストセットでRMSE 1.27、R² 0.97、バイアス 0.01 を達成した
・勾配ブースティングメタは、テストセットでRMSE 1.22、R² 0.97、バイアスは0.00であった
・XGBoostメタは、テストセットでRMSE 1.23、R² 0.97、バイアス0.00だった
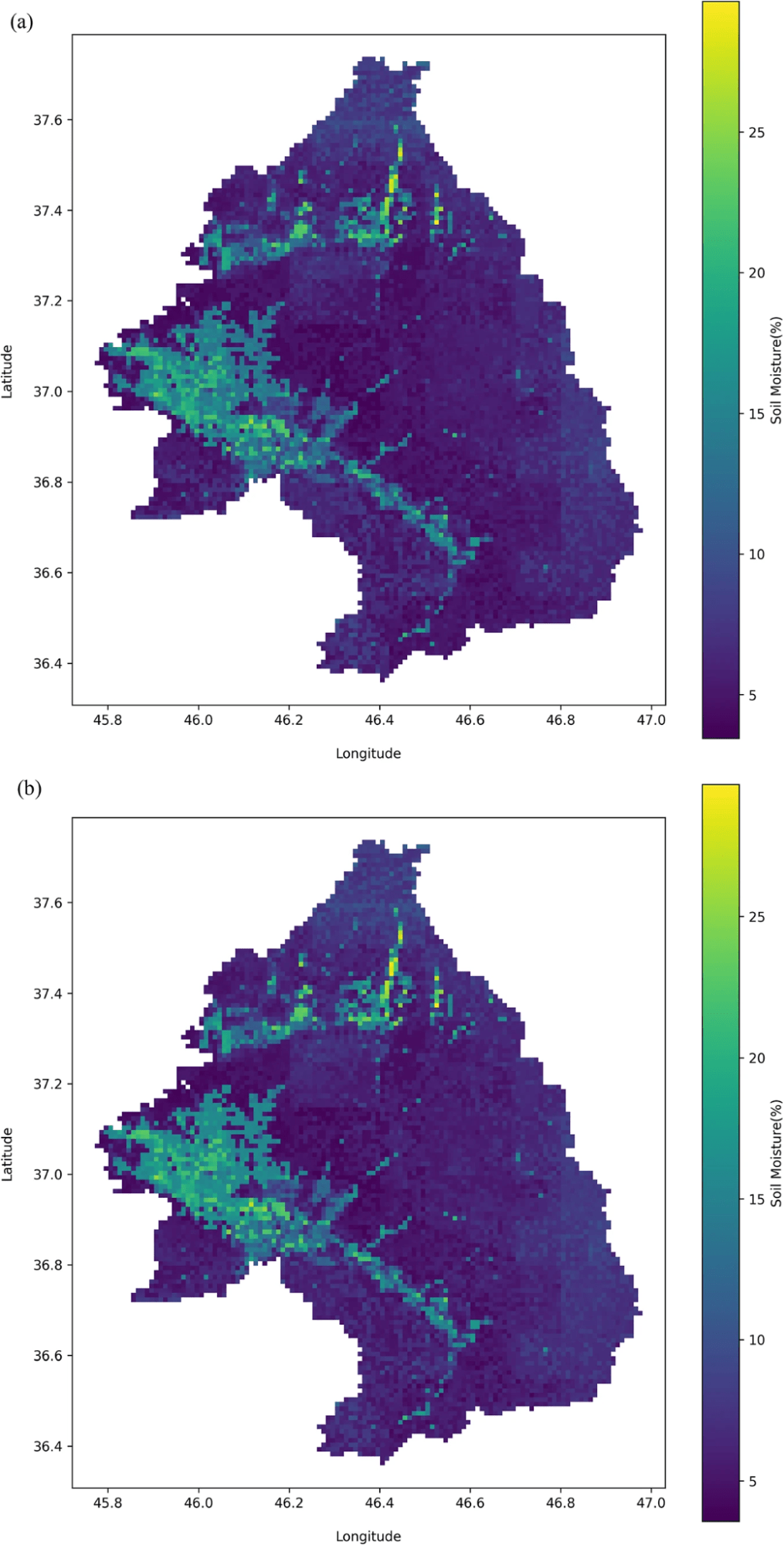
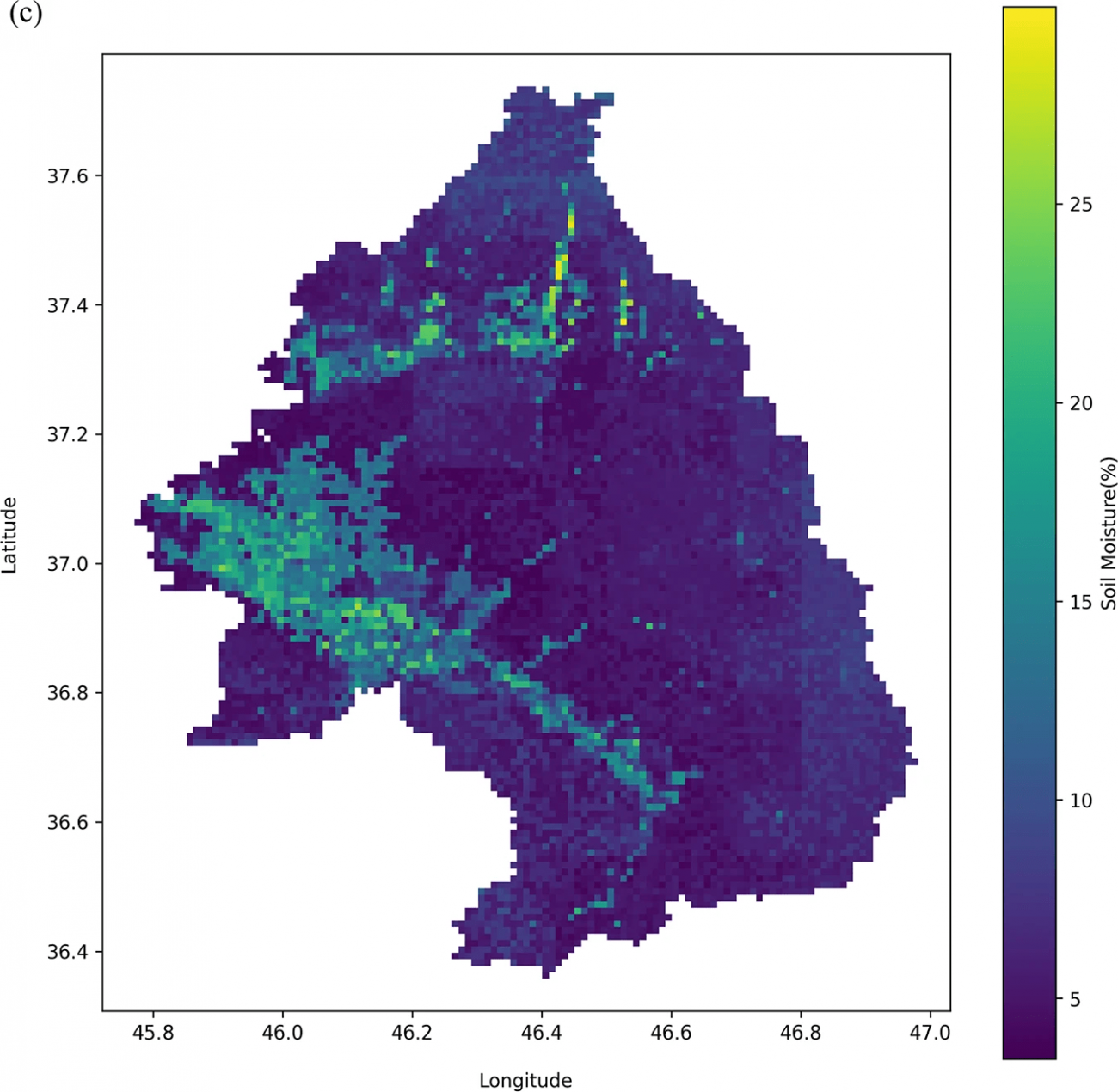
・各メタモデル(勾配ブースティング、ランダムフォレスト、XGBoost)によって生成された1 km解像度の土壌水分マップは以下の通りだが、地域の細かな土壌水分の変動を捉えられているのと、各モデルで水分分布のパターンが類似しており、アンサンブルの一貫性が確認できる
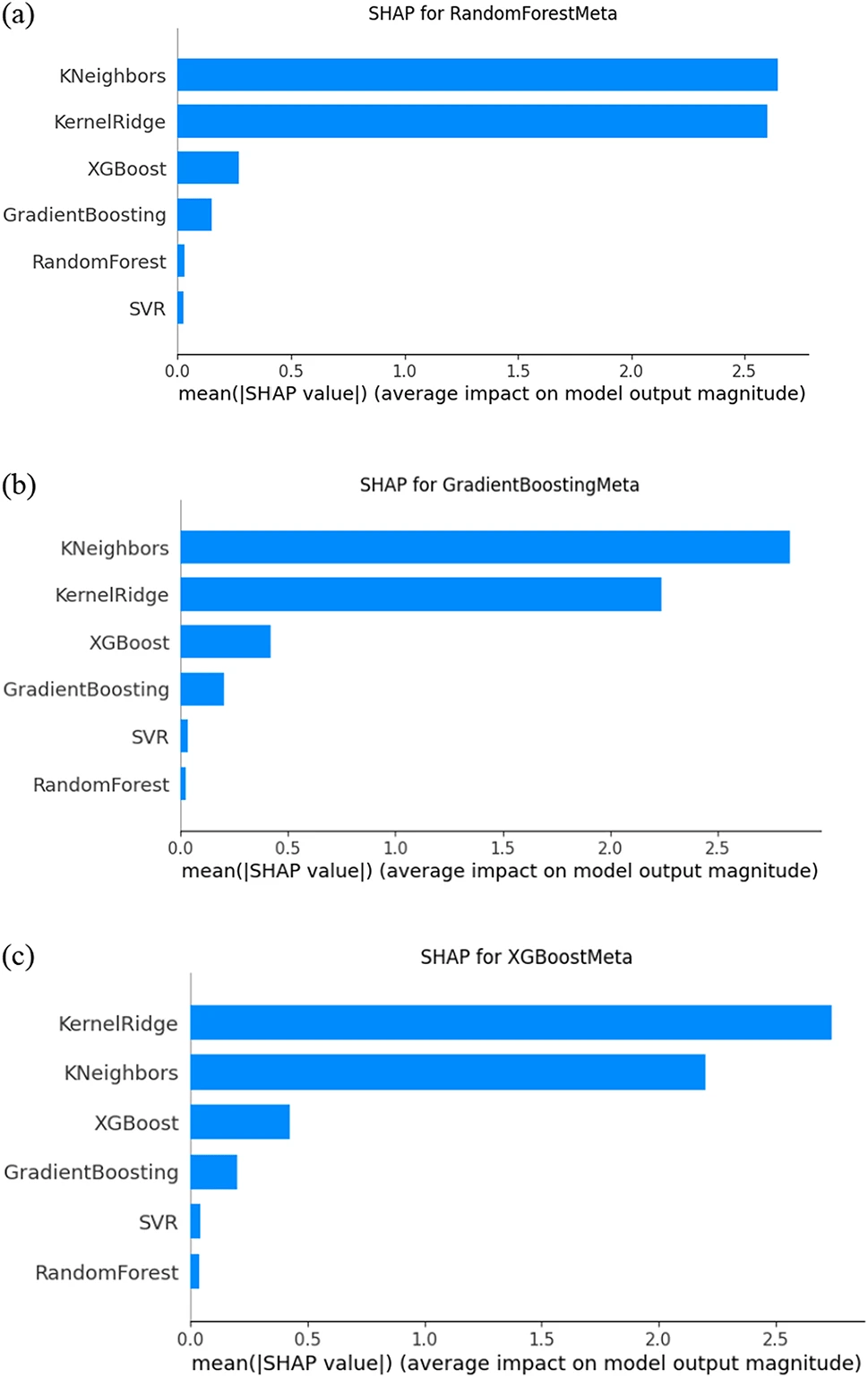
⑥メタモデルにおける予測影響の解釈とSHAP値の分析
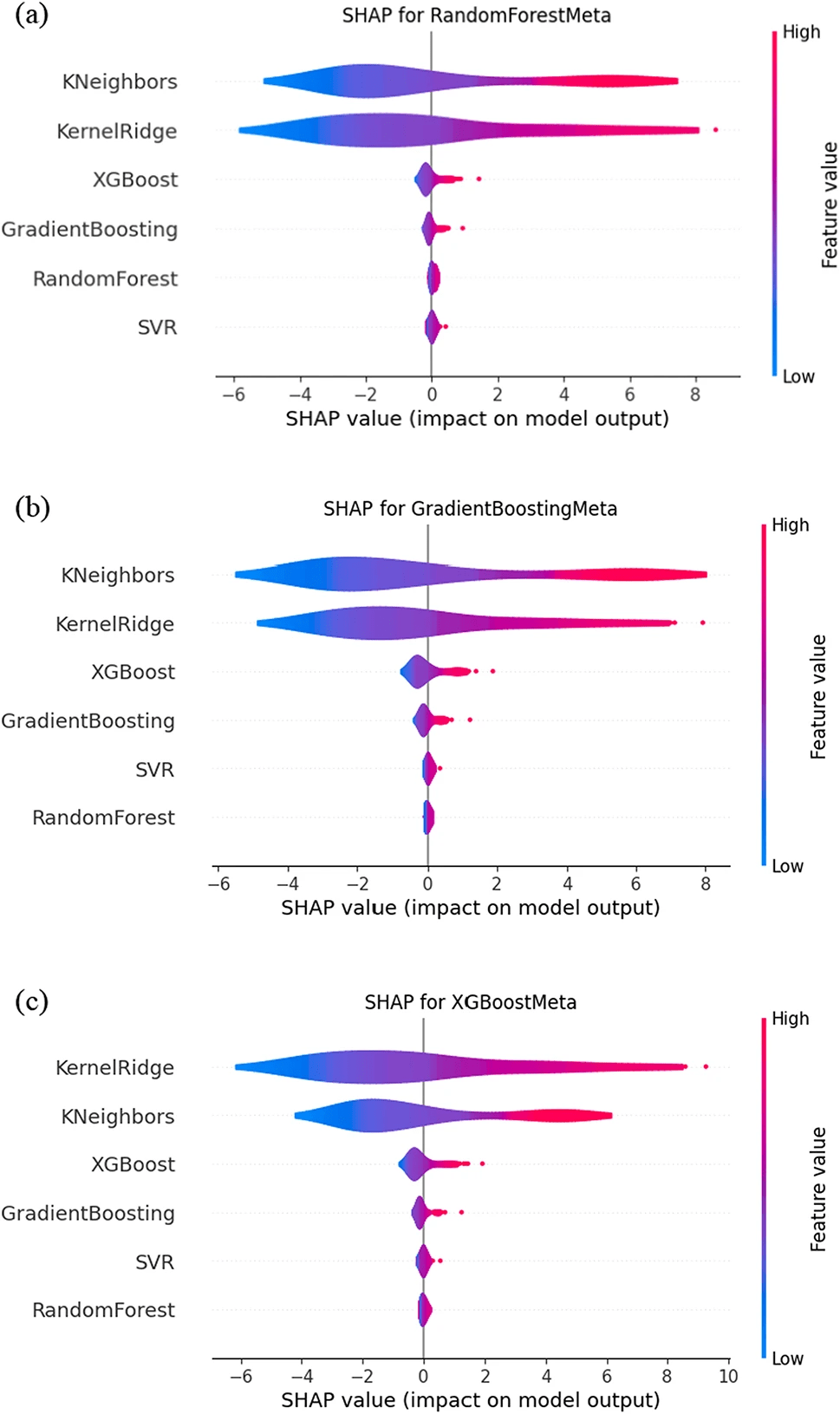
・結果から、K近傍法とカーネルリッジモデルが、特にランダムフォレストメタ、勾配ブースティングメタ、およびXGBoostメタの3つのメタモデルに対して大きな影響を与えていることが分かった
・以下の図は、各ベースモデルのSHAP値の分布をバイオリンプロットで表示し、SHAP値のばらつきを示している
・バイオリンプロットでは、カーネルリッジは広範囲にわたるSHAP値を持ち、予測への影響が大きいことがわかる一方、ランダムフォレストのSHAP値は比較的狭い範囲に分布しており、予測に対する影響が限定的であることを示している
・つまり、カーネルリッジのように広範囲に影響を与えるモデルは、特定の条件下での予測精度向上に貢献しており、ランダムフォレストのように影響が限定的なモデルは、安定した基礎予測を提供していると考えられる
#土壌水分 #SMAP #AMSR2 #MODIS #Terra #Aqua #NDVI #降水データ #地形データ #ベースモデル #サポートベクター回帰 #アンサンブル学習 #スタッキング #ベイズ最適化 #メタモデル #K-最近傍法 #カーネルリッジ #ランダムフォレストメタ #勾配ブースティングメタ #XGBoostメタ #SHAP値 #ランダムフォレスト
Deep-Learning for Change Detection Using Multi-Modal Fusion of Remote Sensing Images: A Review
【どういう論文?】
本論文は、異なる解像度・センサーからのデータを統合し、ディープラーニングを用いてリモートセンシング画像の変化検出精度を向上させる手法をレビューする
【内容】
◾️マルチモーダルデータセット
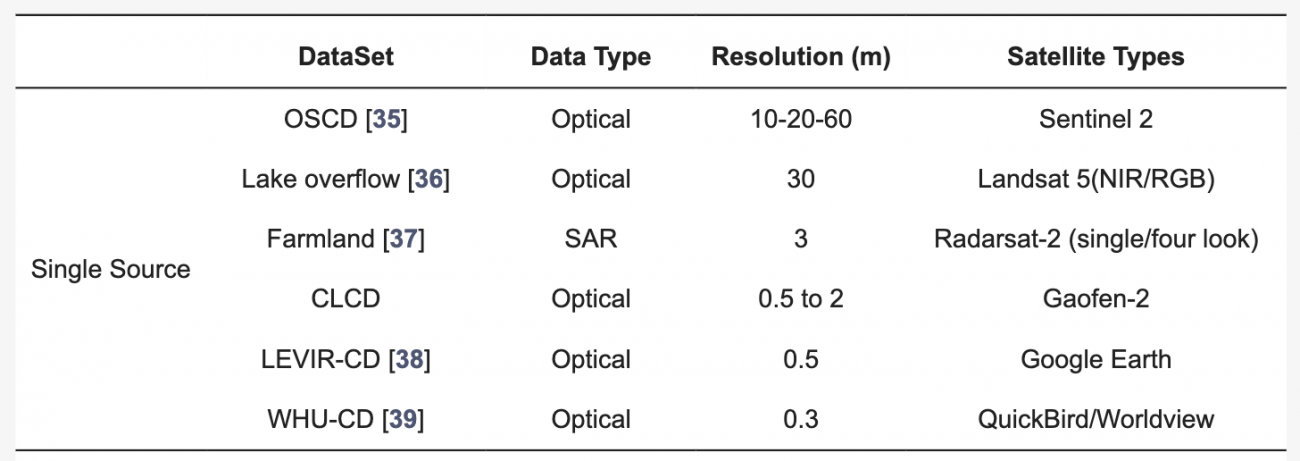
①シングルソースデータ
・シングルソースデータは、特定の種類のセンサー(主に光学センサー)から取得されたデータを指す
・シングルソースデータは、環境条件(例:天候や雲の影響)に左右されやすく、特定の地理的エリアに限られるため、広域のパターンを分析するには不十分なことが多い
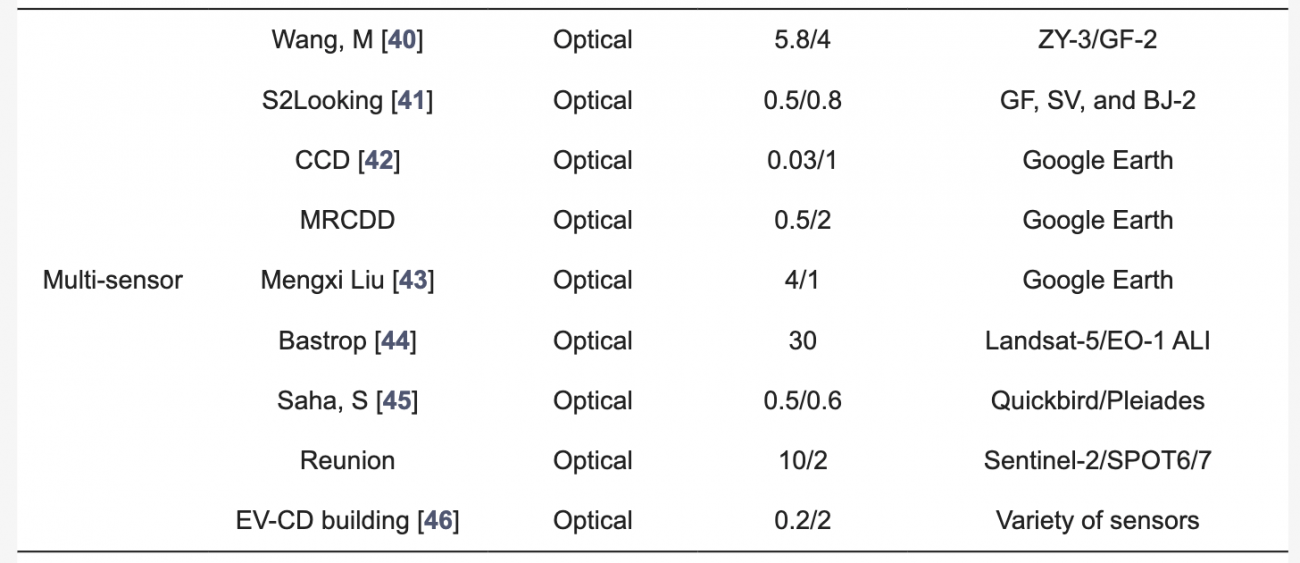
②マルチセンサーデータ
・マルチセンサーデータは、同じモダリティ内で複数のセンサーから収集されるが、各センサーには解像度やスペクトル範囲など独自の特性がある
・画素サイズやスペクトル特性の違いから、リサンプリングや高度な補間が必要になることがあり、潜在的なバイアスや不正確さを引き起こす可能性がある
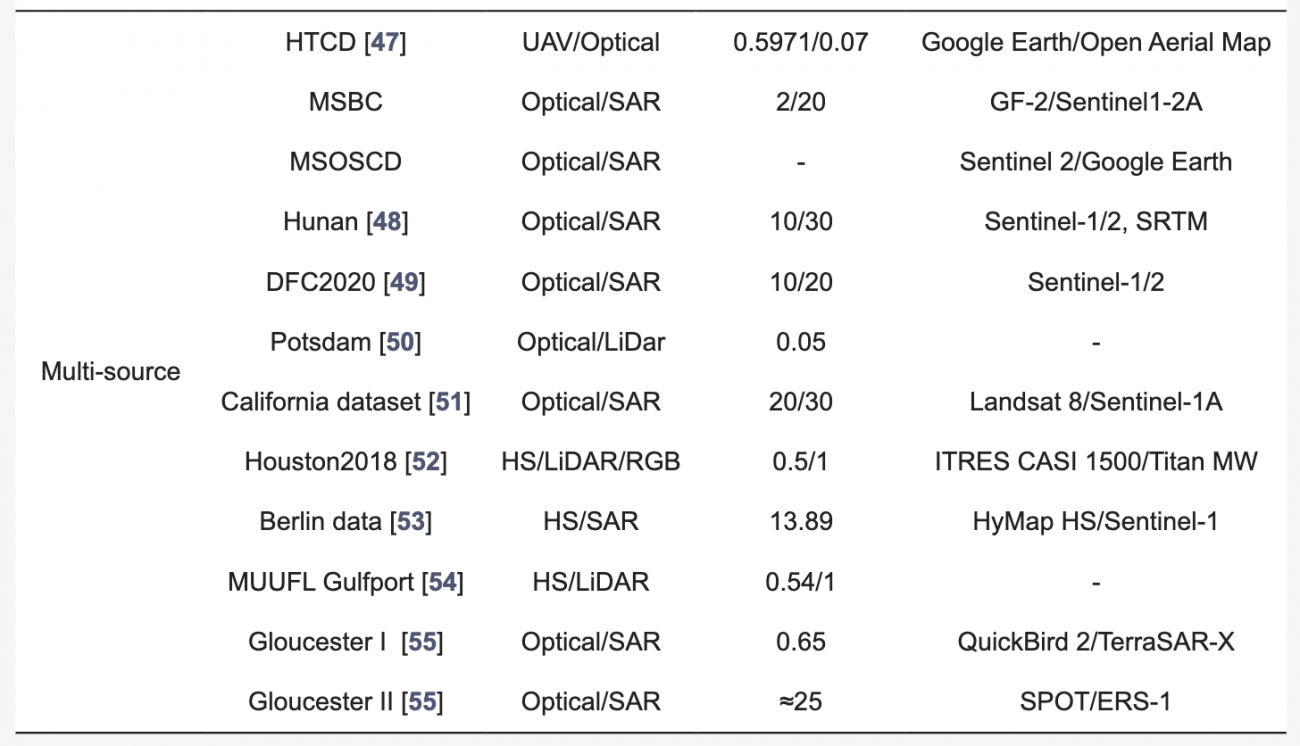
③マルチソースデータ
・マルチソースデータは、異なる種類のセンサー(例:光学とSAR、LiDARなど)からの情報を組み合わせるデータを指す
・センサーごとの異なる特性(例:SARの表面粗さ感度と光学スペクトル情報)により、データの整合が難しく、ノイズや解釈の不一致が発生するリスクがあることに加え、地域や時間によってデータの利用可能性と質が異なるため、バイアスが生じる可能性もある
◾️特徴融合(フュージョン)戦略
①早期融合
・入力層で各モダリティの特徴を統合し、統一された入力表現をDLモデルに渡す
・エンコーダ–デコーダモデルに多く見られ、CNNを使ったシングルストリーム(単一経路)アーキテクチャで、全体的なコンテクストを捉えるのが得意だが、微細な変化やノイズへの対応には弱点がある
②後期融合
・各モダリティの特徴を個別に処理し、最終的な出力層で結果を統合する手法である
・Siameseネットワークアーキテクチャ(双方向の特徴抽出機構)で用いられ、各入力画像から特徴を独立して抽出し、最後に加算や連結、または注意メカニズムで統合して変化マップを生成する
・各データソースの特性を十分に活かしながら個別に処理できるため、特に異質なデータ(例:光学データとSARデータなど)に適している
③多段階融合
・浅い層と深い層の特徴を段階的に融合することで、全体と詳細の両方の変化を把握する手法となる
・SiameseネットワークやダブルストリームUNetアーキテクチャに採用され、Skip Connection(スキップ接続)によって異なるスケールの特徴を組み合わせることで、複雑な特徴を効果的に捉えることが可能である
◾️単一センサーを用いたリモートセンシング変化検出
①CNNアプローチ
・近年、CNN(Convolutional Neural Networks)はリモートセンシング画像の変化検出において高い性能を示している
・特に二重ストリーム構造(Siameseネットワーク)が主流で、同じ構造で2つの画像を同時に処理することで、差異を効果的に抽出する
・代表例として、DSMS-FCNやFDCNNがあり、これらはマルチスケールの特徴抽出や変化ベクトル解析を活用して精度の高い変化マップを生成する
・また、Siamese UNet構造ではスキップ接続や改良型の畳み込みモジュールを用いることで、細かな空間的特徴も捉えることが可能となる
②RNNアプローチ
・RNN(特にLSTM)は、複数の時系列データを扱う変化検出に適している
・LSTMはデータの時間的変化を捉える能力があり、複数の期間にわたる変化を効果的に識別する
・UNetとLSTMの組み合わせにより、空間的特徴と時間的変化を同時に解析し、より正確な変化パターンを抽出する手法が採用されている
④トランスフォーマーアプローチ
・画像全体の関係性を捉えることができるため、複雑な時間的依存関係の把握に適している
・例えば、ChangeFormerやSCanFormerは、トランスフォーマーのエンコーダーを活用して、異なる時間の画像間の相互作用を解析し、変化マップを生成する
・トランスフォーマーの導入により、時間的依存関係や複雑な特徴抽出が可能になり、従来のCNNよりも優れた変化検出が実現されつつある
⑤ハイブリッドアプローチ(CNNとトランスフォーマーの組み合わせ)
・最近では、CNNとトランスフォーマーを組み合わせたハイブリッドモデルが変化検出において人気を集めている
・CNNは画像内の詳細を特定し、トランスフォーマーはその詳細がシーン全体でどのように関連するかを解析する
・TransUNetCDやWNetは、このようなローカルおよびグローバル特徴の両方を効果的に検出するために、CNNとトランスフォーマーの特性を組み合わせており、精度の高い変化検出が可能となっている
◾️異なる解像度の光学データやSARデータを用いた変化検出
①マルチスケール変化検出(光学–光学)
[CNNアプローチ]
・Unetモデル:異なる解像度からの情報を統合することで、広範囲での変化と局所的な変化の両方を検出する
・SUNet:異なるエッジ情報やライン情報を抽出することで、細部まで精確に把握する
[GANアプローチ]
・スーパーレゾリューション(SR):低解像度の画像を高解像度に変換することで、元々ぼんやりとしか見えなかった部分がクリアになり、細部の変化も見逃さずに検出する
②マルチモーダル変化検出(光学–SAR)
[CNNアプローチ]
・M-UNet:光学データとSARデータの両方を取り込み、それぞれの特徴をマルチスケールで取得する
・Siameseアーキテクチャ:SARで地形の硬さや形状を、光学で色や構造をキャプチャし、両方を組み合わせて変化を検出する
[トランスフォーマーアプローチ]
・CM-Net::トランスフォーマーを使って、SARと光学データ間の関係性を深く捉え、複合的な変化を検出する
[GANアプローチ]
・CycleGAN:SAR画像を光学データのように変換し、光学画像での変化検出の手法を適用できるようにする
・EO-GAN:SARデータのエッジ情報を基に光学画像を再構築し、両方のデータ間での差異を減らし、統一的に変化を検出する
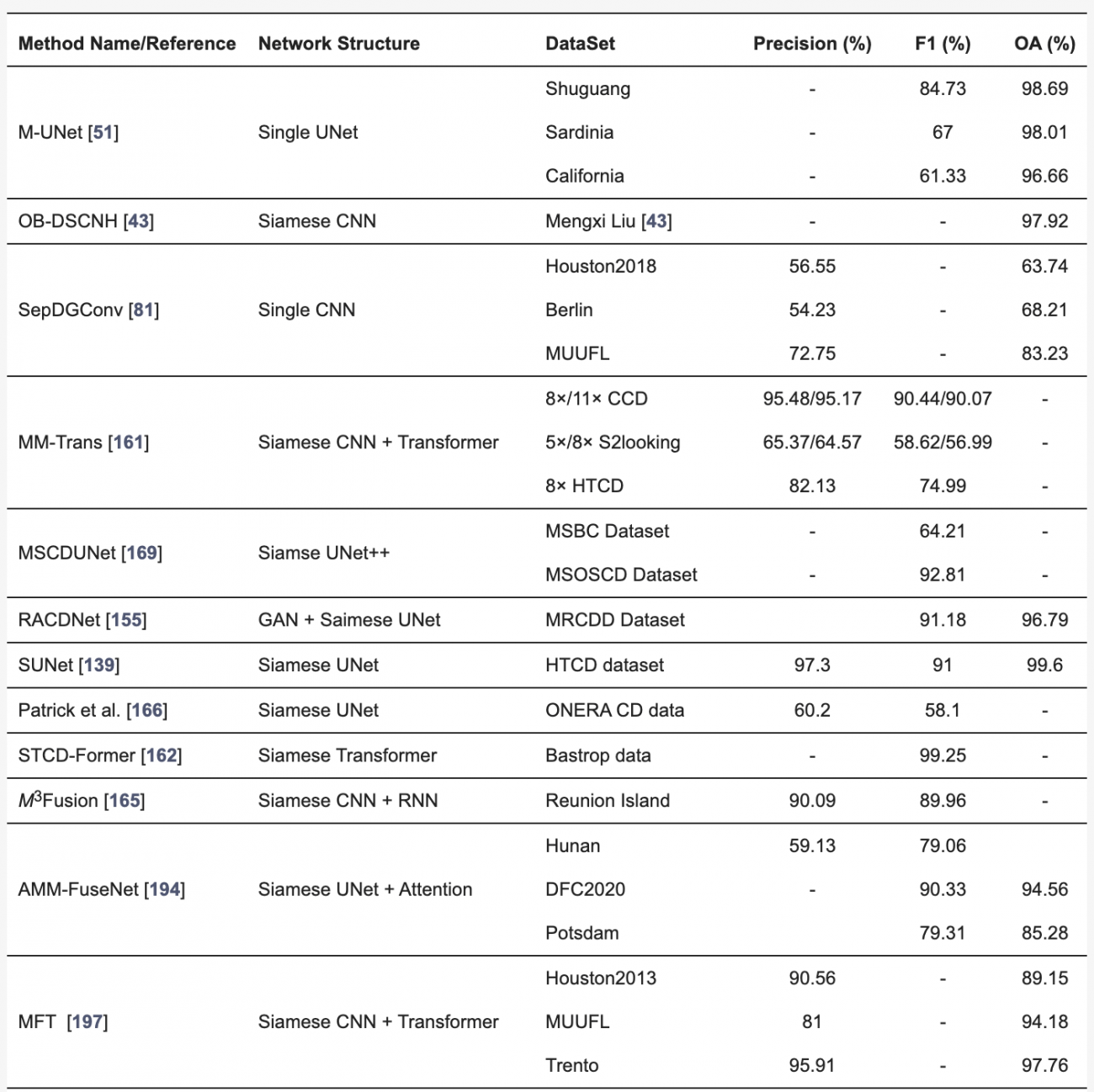
◾️単一センサーを用いたリモートセンシング変化検出手法の定量評価
・一般的に、CNNの一種であるSiameseアーキテクチャが多く用いられ、高精度(90%以上)を達成する例が多く見られる
・しかし、UNetのような単純なモデルでは、長距離依存関係を捉えられないため、複雑なデータセットで精度が低下することが報告されている
・本問題に対処するため、階層的アテンションやチャネル・空間アテンションなど、複数の注意メカニズムが導入され、特定の変化部分にフォーカスすることで精度が向上してきた
・さらに、Siameseネットワークは物体の特徴を保持しやすいものの、変化情報の活用が不十分であることが課題であった
・上記問題に対処するため、複数のエンコーダを使用して物体の特徴と変化の特徴を同時に抽出するアプローチが提案され、99%の精度が達成された
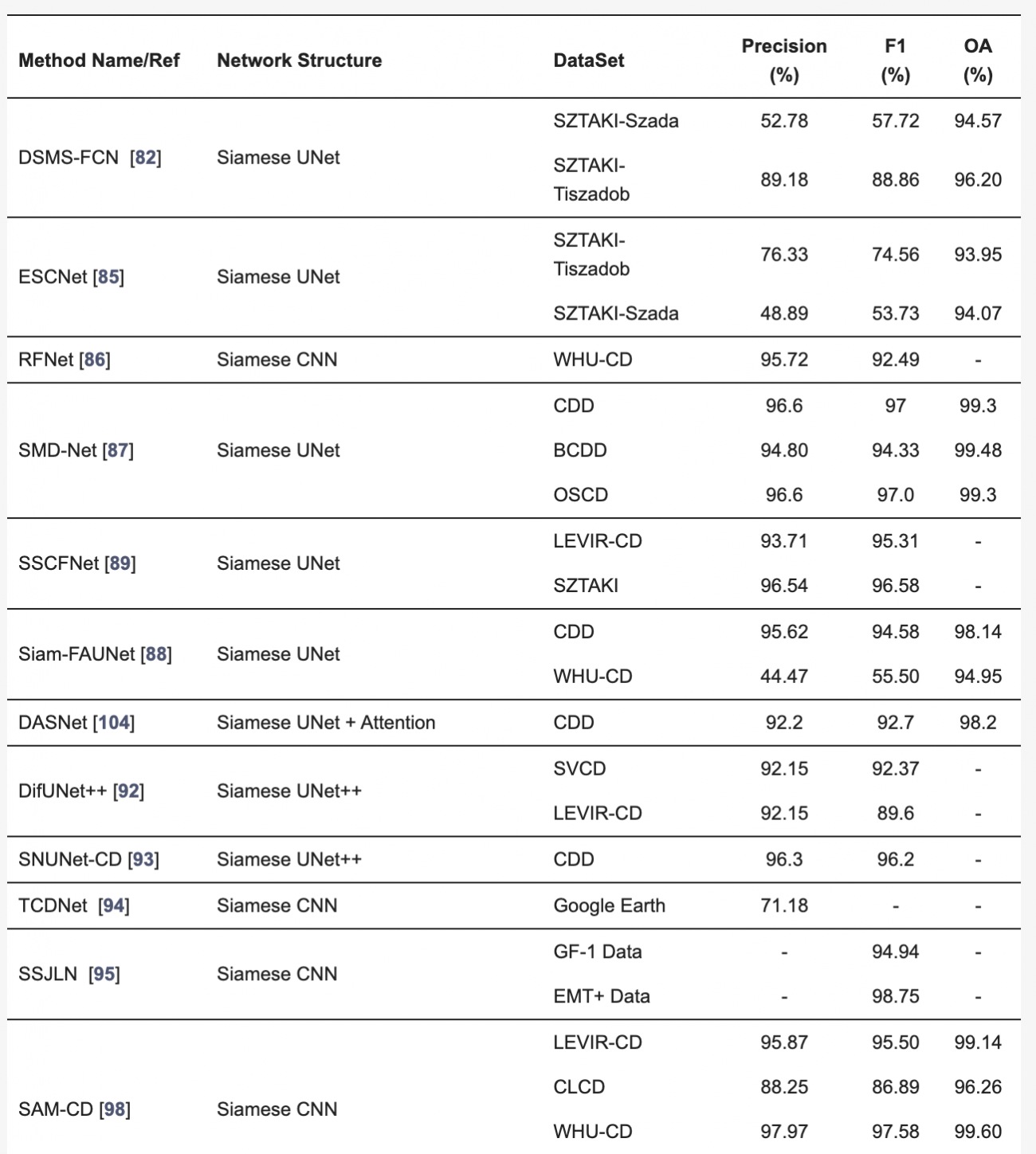
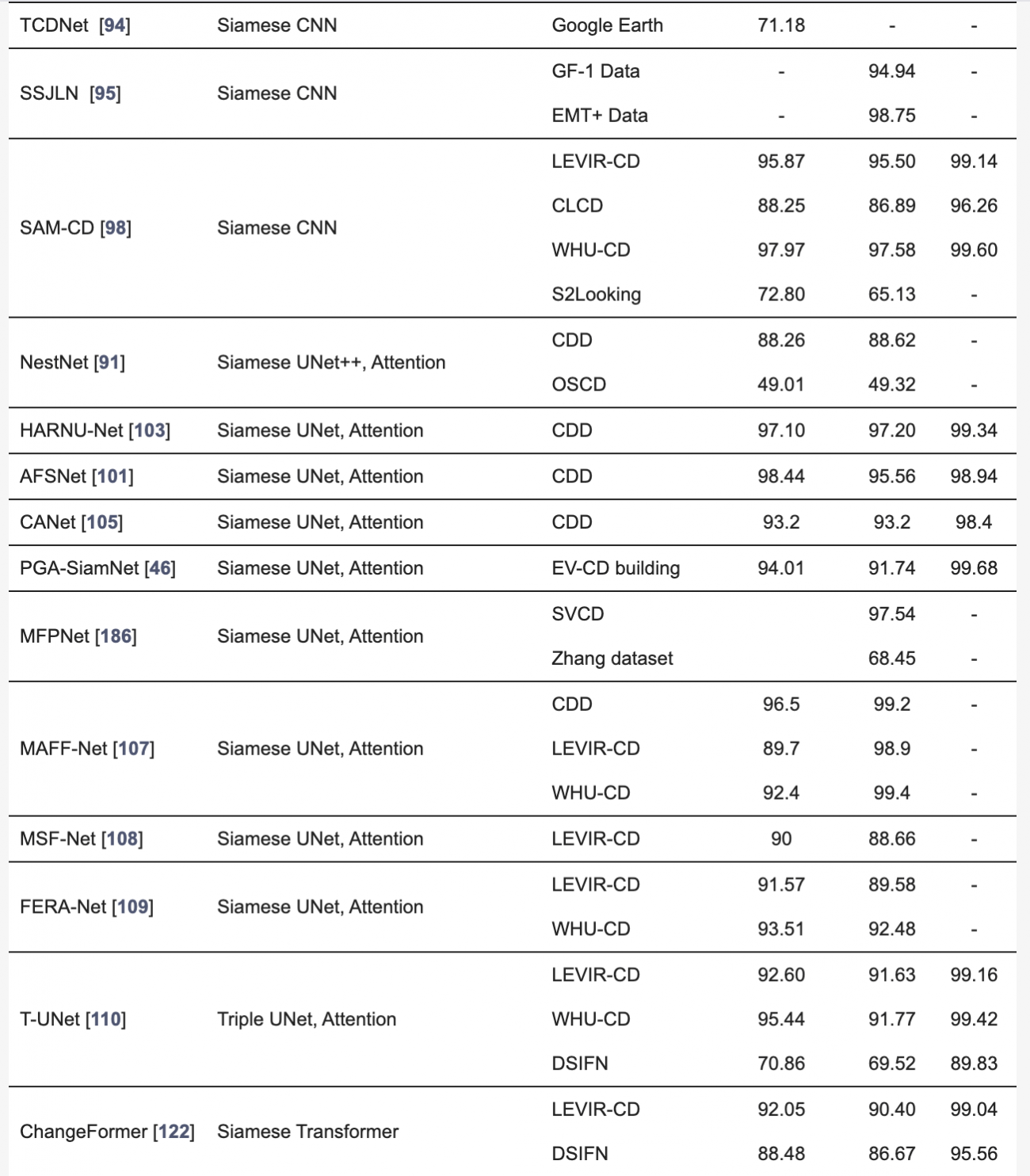
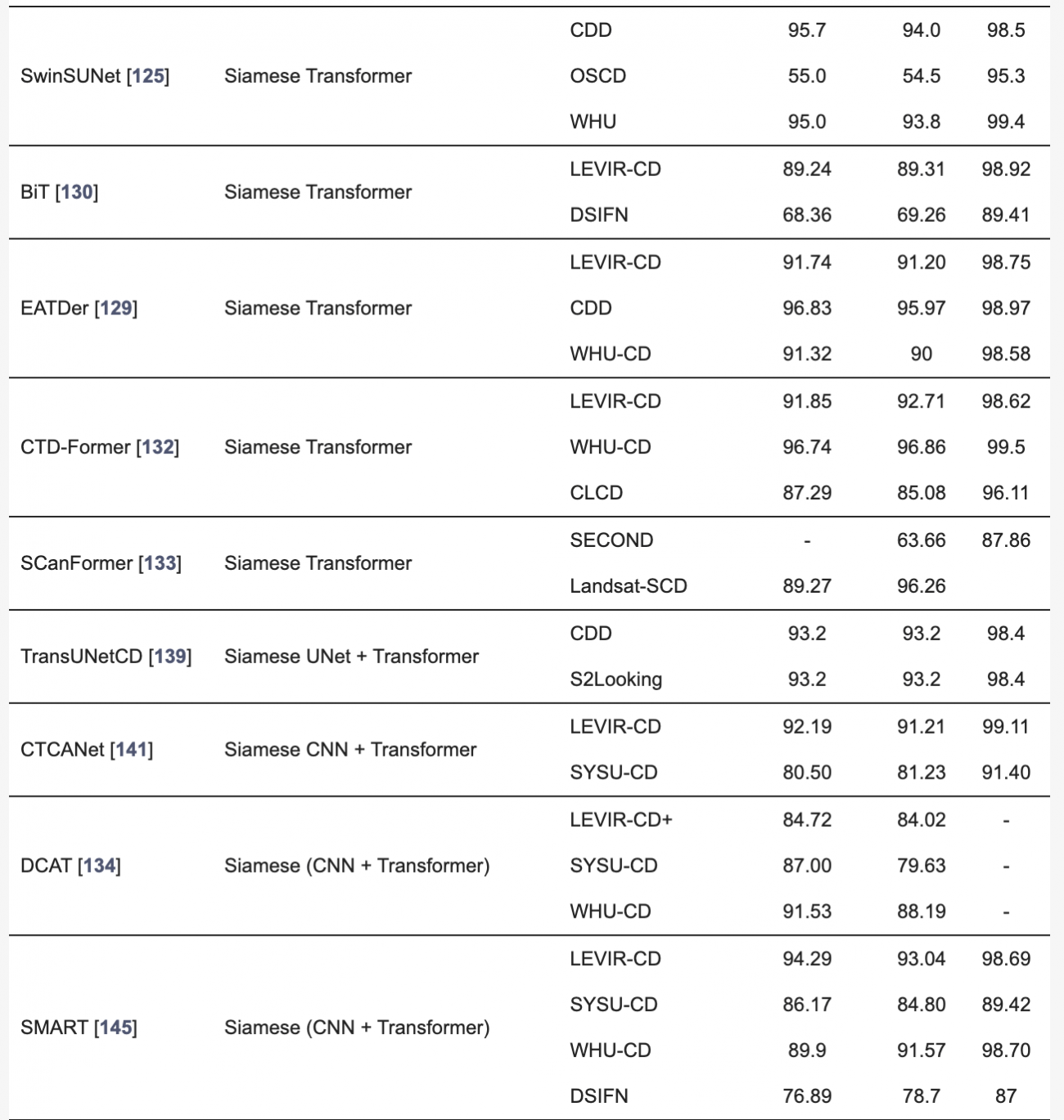
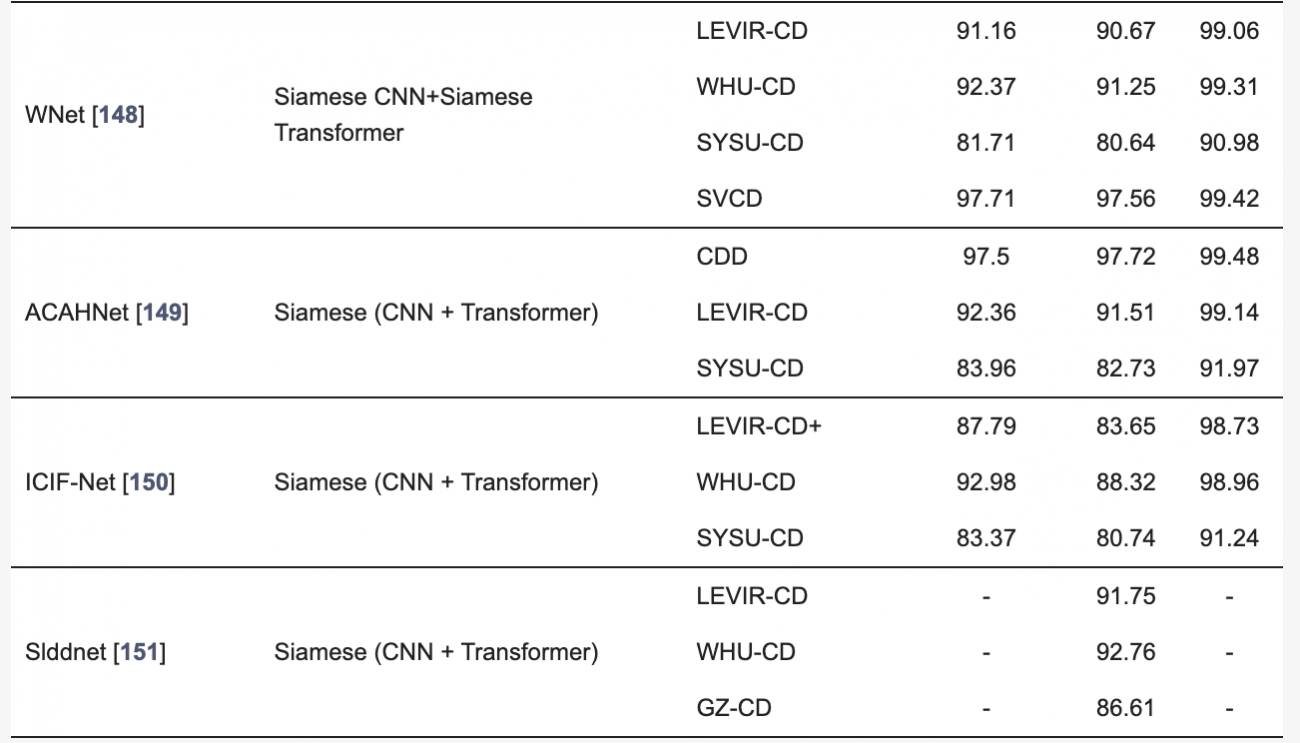
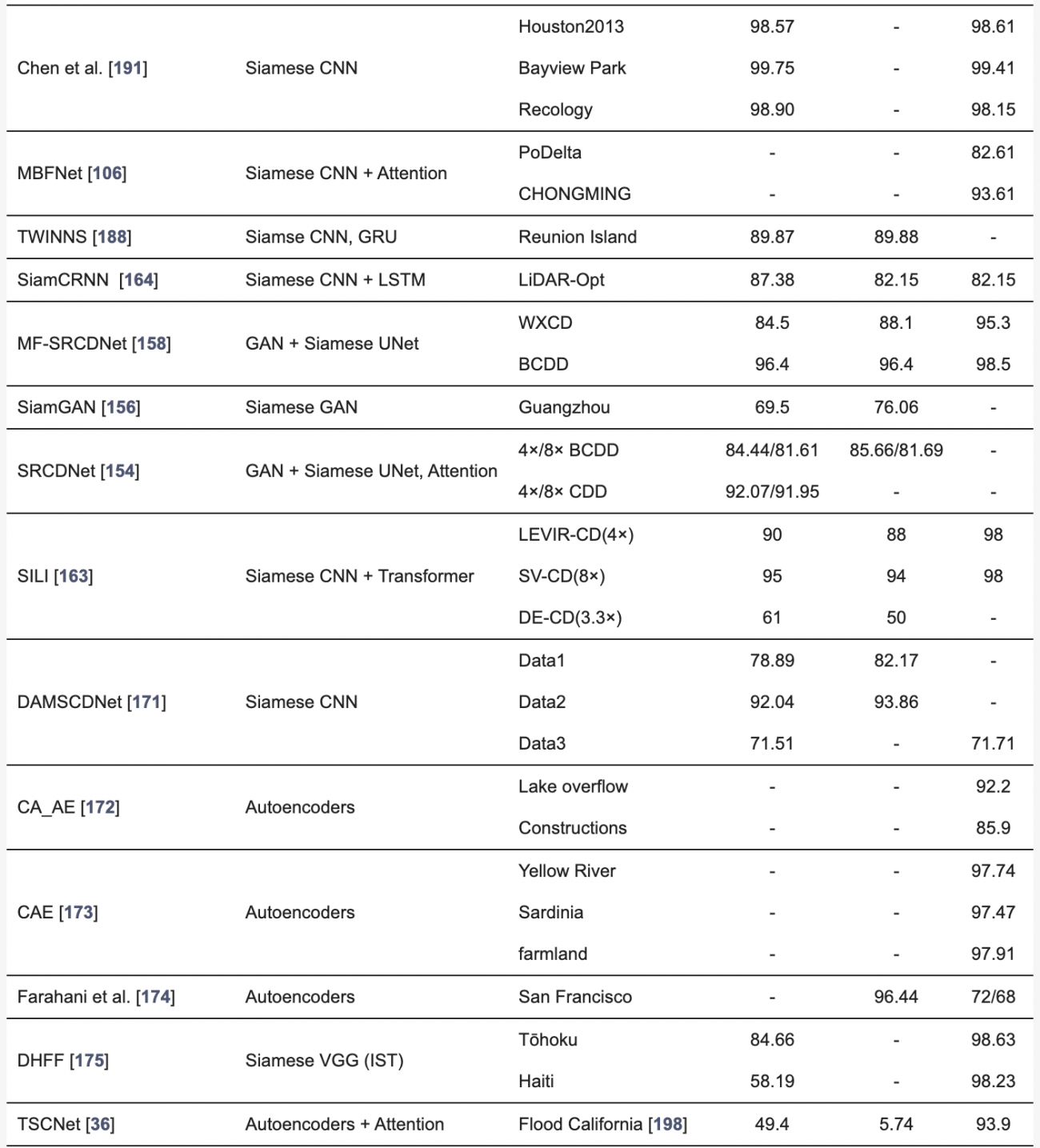
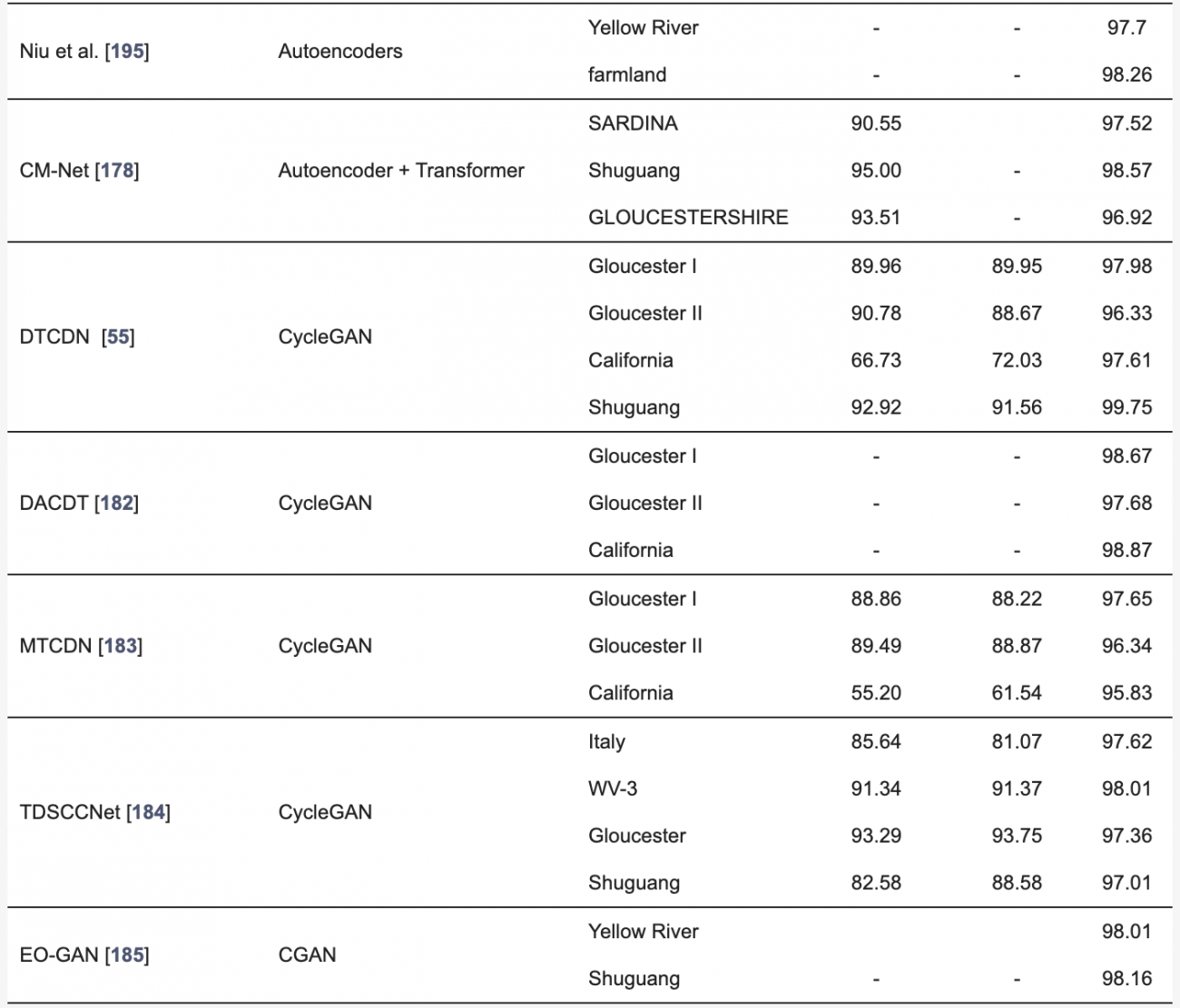
◾️異なる解像度の光学データやSARデータを用いた変化検出の定量的評価
・本検出手法では、解像度の異なるデータをアップサンプリングや補間で整合させることが一般的だが、情報の損失やアライメントのずれが生じやすい
・ディープラーニングによる超解像技術(DL-SR)は、低解像度データを高解像度に変換し、セマンティック情報を補完することで、変化検出の精度を向上させた
・しかし、パッチベースの処理が限界となるため、複雑なシーンの処理には課題が残っている
#RNN #トランスフォーマー #ChangeFormer #SCanFormer #TransUNetCD #WNet #M-UNet #CM-Net #CycleGAN #EO-GAN #CNN #UNet #Siamese #光学データ #SARデータ
以上、2024年10月に公開された論文をピックアップして紹介しました。
皆様の業務や趣味を考えた時に、ピンとくる衛星データ利活用に関する話題はありましたか?
最後に、#MonthlySatDataNews #衛星論文のタグをつけてTwitterに投稿された全ての論文をご紹介します。
Satellite data for environmental justice: a scoping review of the literature in the United States
来月以降も「#MonthlySatDataNews」を続けていきますので、お楽しみに!
