石油タンクの検出精度をUP!?GANを使って衛星データを水増ししてみた
この記事ではDCGANというGANの基本的な手法を使って石油タンクが写ってる衛星データの画像生成にチャレンジします。
記事作成時から、Tellusからデータを検索・取得するAPIが変更になっております。該当箇所のコードについては、以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/access/traveler_api_20220310_
firstpart.html
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
よくネットやSNSとかで、「機械学習を使って人の顔やキャラクターの画像を生成してみた!」というものを見かけますよね。なんだかとても面白そう。そこで、自分も衛星データを生成してみようか、と思い挑戦してみました。
この記事ではDCGANというGANの基本的な手法を使って石油タンクが写ってる衛星データの画像生成にチャレンジします。
この記事を読むと、
– 自分でたくさんの衛星画像(あるいは他の画像でも)を生成できるようになる
– 機械学習のモデルの精度を上げるためのヒントが手に入る
かと思います。
0. 衛星データの画像を生成して教師データを水増しすることで機械学習の精度が上がる!?
衛星データの画像を生成するっていっても、そんなのやって何の役に立つんだと思うかもしれません。単純に楽しいというのはもちろんあるのですが、データサイエンティスト的な観点からも重要なようです。
機械学習をやってみよう、と思ってぶち当たる問題の一つとして、教師データ不足があります。例えば高分解な衛星データなどは高価なため、そもそも大量に入手するのが難しいということがありますよね。
そこで、限られた数の教師データから精度の良い機械学習のモデルを学習するために、教師データの水増し(手持ちの教師データに処理を加えることで、データ数を増やす)がよく行われます。基本的な水増しの処理として、画像を反転させる、ノイズをのせる、輝度変化を加えるなどがあります。
これに加え、GANによる画像生成を用いた水増しもモデルの精度をあげうることが知られています(参考文献1, 2)。なので衛星データの生成は、学習データ不足を補うことで機械学習のモデルの精度向上に寄与するかもしれないのです!
この記事では1節〜5節でGANによる画像生成を行います。6節では実際にGANによるデータの水増しで、石油タンクの有無に関する分類精度が上がるのかを調べてみます。忙しい方は5節の画像生成結果だけでもぜひご覧ください。
1. GANとはなにか
GAN(Generative Adversal Networks)とは、についてはこちらの宙畑記事「SAR画像から光学画像への変換をpix2pixで実装して、作った生成器で別のSAR画像を分析してた」に詳しく書いてあるのでぜひご覧ください。
ざっくりいうと、GANにおいては「学習データに似ている偽物の画像」を作ろうとするネットワーク(生成器: Generator)と、それを偽物の画像か本物の画像か判別するネットワーク(識別器: Discriminator)の二つを同時に学習させます。生成器はなるべく本物そっくりの画像を生成しようとし、一方識別器では、生成器が作った画像を偽物と正しく判定しようと頑張ります。この競争過程を通じ、最終的に生成器は、本物そっくりの画像を生成できるようになります。
この過程はよく偽札を作る詐欺師(生成器)とそれを見破ろうとする警察(識別器)に例えられます。詐欺師はより巧妙な偽札を作り、警察もそれを見破ろうと腕を磨きます。最終的に詐欺師は本物と見分けがつかないような偽札が作れるようになります。
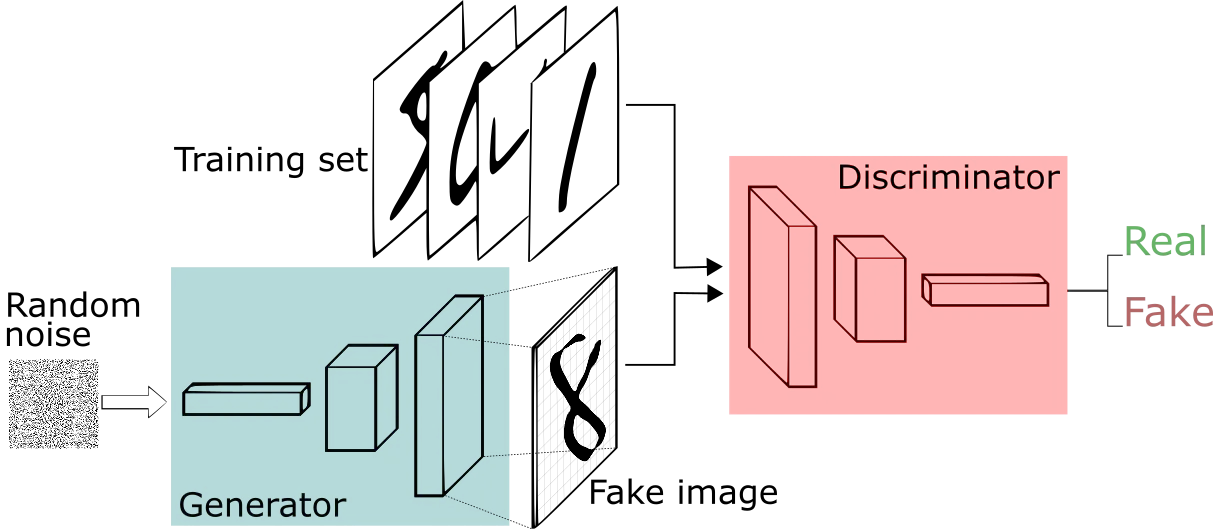
このようなGANを用いれば、ランダムなノイズから学習データに似た多様な画像を大量に生成することができます。なので、これらを用いて学習データの水増しをできる可能性があります。
2. DCGANとは?
DCGAN (Deep Convolutional GAN)とは2016年に提唱されたGANの手法の一種で、GANの中でも特に畳み込みニューラルネットワークを用いたものをいいます。提唱論文はこちらです。
生成器のネットワーク構造は以下のようになっています。識別器の構造はこれを逆にしたような形になっています。
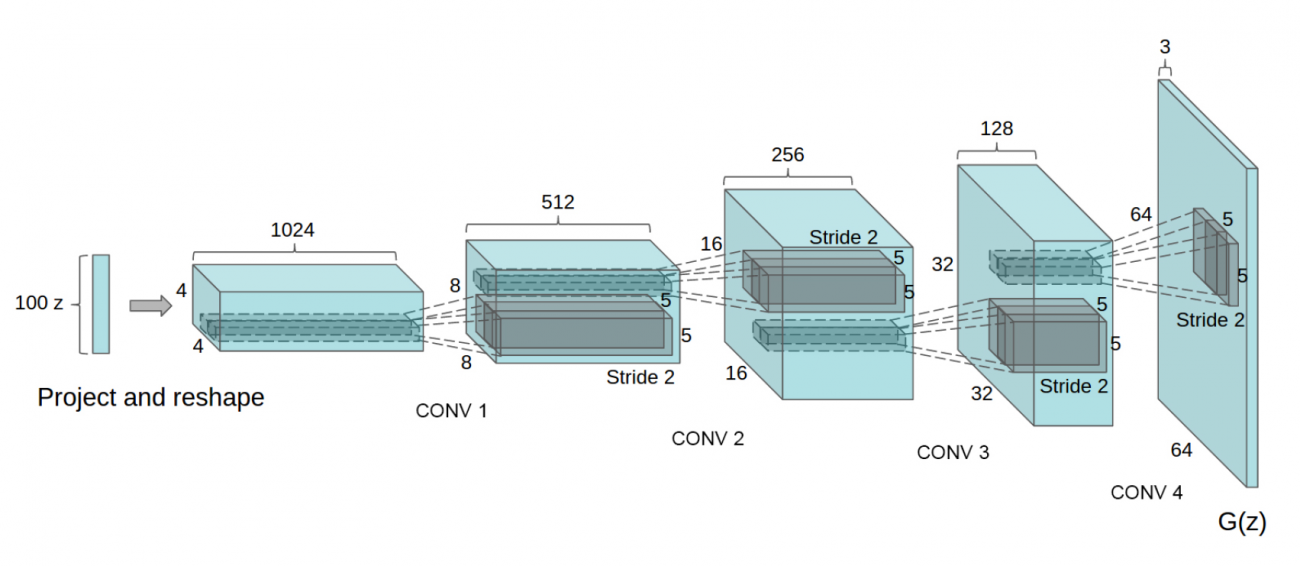
以下がDCGANを用いて生成された寝室の画像になります。本物となかなか見分けがつきませんね。

本記事ではこのDCGANを用いて衛星データの画像生成を行ってみます。
以下の全ての計算はTellusの開発環境を用いており、使用した開発環境は以下のようになります。
#######################
・環境種別(申し込みプラン): サーバ環境
・環境構築: GPUサーバ(高火力コンピューティング)
・GPU: NVIDIA Telsa V100 (32GB) ×1
・CPU: Xeon 4 Core 3.7GHz 1CPU
・メモリ: 64GB
#######################
Tellus GPUの無料プランは現在審査制となっており、全ての人が使えるわけではありません。ただ本記事のコードはTellusの他の環境でも、計算時間は増えますが実行できるかと思います。
3. 用いる学習データ
今回は石油タンクが写っている衛星データの生成を試みようと思います。ご存知の方もいらっしゃるかもしれませんが、衛星データにおける石油タンクの蓋の影からは石油の残量が推定できます。それにより原油の価格変動の予測などが可能になります(参考リンク)。
今回用いるデータは、こちらからダウンロードしました。データはGoogle Earthから取得されています。ダウンロードしたデータのうち、”images_patches”というディレクトリには、512×512に切り取られた画像ファイルが入っており、今回はこれを使います。

“images_patches”は大きな画像から切り取られた画像なため、石油タンクを含むものも含まないものも混ざっています。各画像が石油タンクを含むか否かの情報は、”labels.json”というファイルに記載されています(石油タンクを含まない画像についてはlabelが”Skip”となっている)。
そこで、この情報を用いて以下のように石油タンクを含む画像をData_oil_tankというディレクトリに入れ、含まない画像をData_no_oil_tankというディレクトリに入れることにしましょう。
import os
import json
from PIL import Image
from glob import glob
#ディレクトリの作成
os.makedirs('Data_oil_tank/data/', exist_ok=True)
os.makedirs('Data_no_oil_tank/data/', exist_ok=True)
#labels.jsonの情報にしたがって石油が写っている画像と写っていない画像に分ける
json_open = open('labels.json', 'r')
json_load = json.load(json_open)
#石油タンクが写っているものはData_oil_tankにいれ、写っていないものはData_no_oil_tankにいれる
for v in json_load:
file_name = './image_patches/'+ v['file_name']
img = Image.open(file_name)
if v['label']!='Skip':
img.save("./Data_oil_tank/data/" + v['file_name'], "JPEG")
else:
img.save("./Data_no_oil_tank/data/" + v['file_name'], "JPEG")
#データサイズの確認
print("The size of Data_oil_tank is: ", len(glob("./Data_oil_tank/data/*")))
print("The size of Data_no_oil_tank is: ", len(glob("./Data_no_oil_tank/data/*")))
すると、
The size of Data_oil_tank is: 1829
The size of Data_no_oil_tank is: 8171と表示され、石油タンクを含む画像は1829枚あり、含まない画像は8171枚あることが分かります。6章をのぞいては前者のデータだけを使います。
4. コードの実装
DCGANの提唱論文で提唱されたネットワーク構造(2節参照)は、64×64などの小さめの画像を扱うのには適していますが、今回扱うような大きい画像にはあまり適していません。
そこで、今回はDCGANが256×256の画像に適用できるように修正された、こちらのコードを使わせていただこうと思います。必要に応じて以下で適宜コードの改変をしていきます。
まずは上のコードをTellusの開発環境にコピーします。
git clone https://github.com/t0nberryking/DCGAN256このコードはとても利用者に優しく、ほとんどそのまま使うことができます。ただ、念のため”gan.py”というメインファイルのうち、肝となる部分だけをここに抽出しておきます(コードを動かすだけならここは読み飛ばしても問題ないです)。以下が、識別器と生成器のネットワーク構造になります。
# 識別器の定義
# 画像か本物か偽物かを判定するためのネットワーク
def discriminator(self):
if self.D:
return self.D
self.D = Sequential()
#過学習を防ぐためにノイズを加える
self.D.add(GaussianNoise(0.2, input_shape = [256, 256, 3]))
#256x256x3 → 128x128x8
self.D.add(Conv2D(filters = 8, kernel_size = 3, padding = 'same'))
self.D.add(LeakyReLU(0.2))
self.D.add(Dropout(0.25))
self.D.add(AveragePooling2D())
#256x256x3 → 64x64x16
self.D.add(Conv2D(filters = 16, kernel_size = 3, padding = 'same'))
self.D.add(BatchNormalization(momentum = 0.7))
self.D.add(LeakyReLU(0.2))
self.D.add(Dropout(0.25))
self.D.add(AveragePooling2D())
#64x64x16 → 32x32x32
self.D.add(Conv2D(filters = 32, kernel_size = 3, padding = 'same'))
self.D.add(BatchNormalization(momentum = 0.7))
self.D.add(LeakyReLU(0.2))
self.D.add(Dropout(0.25))
self.D.add(AveragePooling2D())
#32x32x32 → 16x16x64
self.D.add(Conv2D(filters = 64, kernel_size = 3, padding = 'same'))
self.D.add(BatchNormalization(momentum = 0.7))
self.D.add(LeakyReLU(0.2))
self.D.add(Dropout(0.25))
self.D.add(AveragePooling2D())
#16x16x64 → 8x8x128
self.D.add(Conv2D(filters = 128, kernel_size = 3, padding = 'same'))
self.D.add(BatchNormalization(momentum = 0.7))
self.D.add(LeakyReLU(0.2))
self.D.add(Dropout(0.25))
self.D.add(AveragePooling2D())
#8x8x128 → 4x4x256
self.D.add(Conv2D(filters = 256, kernel_size = 3, padding = 'same'))
self.D.add(BatchNormalization(momentum = 0.7))
self.D.add(LeakyReLU(0.2))
self.D.add(Dropout(0.25))
self.D.add(AveragePooling2D())
self.D.add(Flatten())
self.D.add(Dense(128))
self.D.add(LeakyReLU(0.2))
self.D.add(Dense(1, activation = 'sigmoid'))
return self.D
# 生成器の定義
# ランダムなノイズから256×256の画像を生成する
def generator(self):
if self.G:
return self.G
self.G = Sequential()
self.G.add(Reshape(target_shape = [1, 1, 4096], input_shape = [4096]))
### 以下、Conv2DTranspose層を用いて画像を順に拡大していく ###
#1x1x4096 → 4x4x256
self.G.add(Conv2DTranspose(filters = 256, kernel_size = 4))
self.G.add(Activation('relu'))
#4x4x256 → 8x8x256
self.G.add(Conv2D(filters = 256, kernel_size = 4, padding = 'same'))
self.G.add(BatchNormalization(momentum = 0.7))
self.G.add(Activation('relu'))
self.G.add(UpSampling2D())
#8x8x256 → 16x16x128
self.G.add(Conv2D(filters = 128, kernel_size = 4, padding = 'same'))
self.G.add(BatchNormalization(momentum = 0.7))
self.G.add(Activation('relu'))
self.G.add(UpSampling2D())
#16x16x128 → 32x32x64
self.G.add(Conv2D(filters = 64, kernel_size = 3, padding = 'same'))
self.G.add(BatchNormalization(momentum = 0.7))
self.G.add(Activation('relu'))
self.G.add(UpSampling2D())
#32x32x64 → 64x64x32
self.G.add(Conv2D(filters = 32, kernel_size = 3, padding = 'same'))
self.G.add(BatchNormalization(momentum = 0.7))
self.G.add(Activation('relu'))
self.G.add(UpSampling2D())
#64x64x32 → 128x128x16
self.G.add(Conv2D(filters = 16, kernel_size = 3, padding = 'same'))
self.G.add(BatchNormalization(momentum = 0.7))
self.G.add(Activation('relu'))
self.G.add(UpSampling2D())
#128x128x16 → 256x256x8
self.G.add(Conv2D(filters = 8, kernel_size = 3, padding = 'same'))
self.G.add(Activation('relu'))
self.G.add(UpSampling2D())
self.G.add(Conv2D(filters = 3, kernel_size = 3, padding = 'same'))
self.G.add(Activation('sigmoid'))
return self.G
さて、以下で今回の問題に合わせ、メインコード(gan.py)に対していくつかの修正を行います。
まず、今回用意したデータを読み込むため、コード序盤のデータ読み込み部分を以下のように書き換えます。
Images = []
images_path = glob("./Data_oil_tank/data/*") # 画像のパスリストを取得
for path in images_path: # 画像のパスリストから一枚ずつ読み込む
temp1 = Image.open(path)
# 画像を(512, 512)から(256, 256)へリサイズ
temp1_res = temp1.resize((256, 256), Image.BICUBIC)
temp = np.array(temp1_res.convert('RGB'), dtype='float32')
Images.append(temp / 255) # ピクセル値が0〜1になるよう正規化
# 反転させた画像を含める (基本的な水増し処理)
Images.append(np.flip(Images[-1], 0))
Images.append(np.flip(Images[-1], 1))
次に、生成された一枚一枚の画像を保存するためディレクトリを以下のように作ります。
mkdir Generated_images生成された個々の画像を保存するために、eval2という関数に以下のように数行追加します。eval2は、1000ステップごとに呼び出され、生成画像を保存するための関数です。
def eval2(self, num = 0):
# 学習しているGANにより48枚の画像を生成
im2 = self.generator.predict(noise(48))
r1 = np.concatenate(im2[:8], axis = 1)
r2 = np.concatenate(im2[8:16], axis = 1)
r3 = np.concatenate(im2[16:24], axis = 1)
r4 = np.concatenate(im2[24:32], axis = 1)
r5 = np.concatenate(im2[32:40], axis = 1)
r6 = np.concatenate(im2[40:48], axis = 1)
c1 = np.concatenate([r1, r2, r3, r4, r5, r6], axis = 0)
x = Image.fromarray(np.uint8(c1*255))
# 48枚の画像をつなぎ合わせた一枚の画像を保存
x.save("Results/i"+str(num)+".png")
###########################
######## 以下を追加 ########
###########################
# 48枚の個々の画像を保存。
for i in range(48):
im_gen = Image.fromarray(np.uint8(im2[i]*255))
im_gen.save("Generated_images/gen_"+str(num)+ str(i) + ".png")
これで準備ができたので、gan.pyを以下のように実行します。
python3 gan.pyすると、ネットワーク構造の要約が表示されたのちに、以下のように学習が始まります。
We're off! See you in a while!
D Real: 1.043933629989624, D Fake: 0.9545743465423584, G All: 0.5472399592399597
D Real: 0.47732219099998474, D Fake: 0.9632525444030762, G All: 0.4688695967197418
D Real: 0.478287935256958, D Fake: 0.8590899705886841, G All: 0.4938095211982727
D Real: 0.6463823318481445, D Fake: 0.7325788736343384, G All: 0.4973256587982178
D Real: 0.5505478382110596, D Fake: 0.6448032855987549, G All: 0.4532738924026489
D Real: 0.678729772567749, D Fake: 0.5293006300926208, G All: 0.5831642150878906
....
デフォルトの設定では500000ステップ学習を進めたのちに計算が終了します。今回はGPUを用いて計算を行いましたが、それでも体感で半日以上かかりました。CPUで計算を行う場合はステップ数を減らした方がいいかもしれません。
5. 生成画像の表示
それでは学習したGANのモデルによって生成された画像を見てみましょう。
1000stepごとに、eval2という関数によって48枚の生成画像を連結した1枚の画像が保存されています。これを以下のように時系列順にgifファイルにします。
from glob import glob
from PIL import Image
# step数が1000の1倍, 5倍,...,500倍の時の画像を順に表示。
path_list = ["./data/i" + str(i) + ".png" for i in [1, 5, 10, 15, 20, 30, 40, 50, 75, 100, 200, 300, 400, 500]]
images = list(map(lambda file : Image.open(file) , path_list))
images[0].save('out.gif', save_all=True, append_images=images[1:], optimize=False, duration=800)
生成されたgifファイルは以下のようになりました。本物と見紛うほど美しい画像というわけではないですが、学習が進むにつれたしかに石油タンクのようなものが生成されているのが分かりますね (全体的に黄色っぽいのっぺりした画像が1枚目)。
6. 生成画像による水増しの画像分類精度への影響
…本章は少々マニアックかもしれないので気になる方だけ読んでいただければと思います笑
さて、無事石油タンクらしきものが写った衛星データを生成することができました。そもそもなぜこんなことをしたかったのでしょう…?それはもちろん見ていて楽しいというのはあるのですが、生成画像によって少ない教師データを補いたかったからでした。
では「衛星画像に石油タンクが写っているか否か」という分類問題の精度が、GANによるデータの水増しによって向上するかを調べてみましょう。
まずはデータの整形をします。
元データ(Data_oil_tank: 1829枚、Data_no_oil: 8171枚)を以下のように学習用、検証用、評価用に分けます。oilは石油タンクを含む画像でno_oilは含まない画像です。さらに、GA Nで生成された石油タンクを含む画像を学習用データに加えます。
・Data
┣ train (7771枚)
┃ ┣ oil (1829-400=1429枚+生成画像2000枚)
┃ ┗ no_oil (200枚)
┃
┣ validation (検証用)
┃ ┣ oil (200枚)
┃ ┗ no_oil (200枚)
┃
┗ test (評価用)
┣ oil (200枚)
┗ no_oil (200枚)
これらのデータの整形は以下のコードで実行できます。
import os
import random
import shutil
from glob import glob
# 検証用、評価用画像の枚数
N = 200
random.seed(0)
# ディレクトリの作成
os.makedirs('Data/training/oil/', exist_ok=True)
os.makedirs('Data/training/no_oil/', exist_ok=True)
os.makedirs('Data/validation/oil/', exist_ok=True)
os.makedirs('Data/validation/no_oil/', exist_ok=True)
os.makedirs('Data/test/oil/', exist_ok=True)
os.makedirs('Data/test/no_oil/', exist_ok=True)
# データを学習用、検証用、評価用に分けていく
files = glob("./Data_oil_tank/data/*")
val_files = random.sample(files, N)
for path in val_files:
shutil.copy(path, 'Data/validation/oil/')
files = list(set(files) - set(val_files))
test_files = random.sample(files, N)
for path in test_files:
shutil.copy(path, 'Data/test/oil/')
files = list(set(files) - set(test_files))
for path in files:
shutil.copy(path, 'Data/training/oil/')
##############
files = glob("./Data_no_oil_tank/data/*")
val_files = random.sample(files, N)
for path in val_files:
shutil.copy(path, 'Data/validation/no_oil/')
files = list(set(files) - set(val_files))
test_files = random.sample(files, N)
for path in test_files:
shutil.copy(path, 'Data/test/no_oil/')
files = list(set(files) - set(test_files))
for path in files:
shutil.copy(path, 'Data/training/no_oil/')
# 生成画像を学習データに含める場合、Trueとする
do_add_gen = True
if do_add_gen:
files = []
for i in range(101,501):
for j in range(0, 48):
files.append("Generated_images/gen_" + str(i) + "_" + str(j) + ".png")
# 10万ステップ以降の生成画像からランダムに2000枚選んで学習データに加える
gen_files = random.sample(files, 2000)
for path in gen_files:
shutil.copy(path, 'Data/training/oil/')
あとは、こちらの記事を参考に画像分類のモデルを実装します。以前に雲分類を行った宙畑の記事があるので、そちらもぜひご覧ください。以下がその実装になります。
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
image_size = (180, 180)
batch_size = 32
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
"Data/training",
seed=1337,
image_size=image_size,
batch_size=batch_size,
)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
"Data/validation",
seed=1337,
image_size=image_size,
batch_size=batch_size,
)
# データ拡張
data_augmentation = keras.Sequential(
[
layers.experimental.preprocessing.RandomFlip("horizontal"),
layers.experimental.preprocessing.RandomRotation(0.1),
]
)
train_ds = train_ds.prefetch(buffer_size=32)
val_ds = val_ds.prefetch(buffer_size=32)
def make_model(input_shape, num_classes):
inputs = keras.Input(shape=input_shape)
# Image augmentation block
x = data_augmentation(inputs)
# Entry block
x = layers.experimental.preprocessing.Rescaling(1.0 / 255)(x)
x = layers.Conv2D(32, 3, strides=2, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.Conv2D(64, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
previous_block_activation = x # Set aside residual
for size in [128, 256, 512, 728]:
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
# Project residual
residual = layers.Conv2D(size, 1, strides=2, padding="same")(
previous_block_activation
)
x = layers.add([x, residual]) # Add back residual
previous_block_activation = x # Set aside next residual
x = layers.SeparableConv2D(1024, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.GlobalAveragePooling2D()(x)
if num_classes == 2:
activation = "sigmoid"
units = 1
else:
activation = "softmax"
units = num_classes
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(units, activation=activation)(x)
return keras.Model(inputs, outputs)
model = make_model(input_shape=image_size + (3,), num_classes=2)
epochs = 200
callbacks = [
keras.callbacks.ModelCheckpoint("save_at_{epoch}.h5"),
]
model.compile(
optimizer=keras.optimizers.Adam(1e-3),
loss="binary_crossentropy",
metrics=["accuracy"],
)
history = model.fit(
train_ds, epochs=epochs, callbacks=callbacks, validation_data=val_ds,
)
上のコードを実行すると計算が走り出し、200エポック経過した時点で計算が終了します。比較のために、生成画像を含まない元の学習用データのみを用いても、同様の計算を行いました。
モデルの損失関数(モデルによる予測と正解データとのずれ具合)と分類精度が、学習が進むにつれどのように変化したかをプロットすると、以下のようになりました。実線はGANによる生成画像で水増しを行った場合、波線はそのような水増しを行わなかった場合です。また、青色、オレンジ色はそれぞれ学習用データ、検証用データに対するものです。
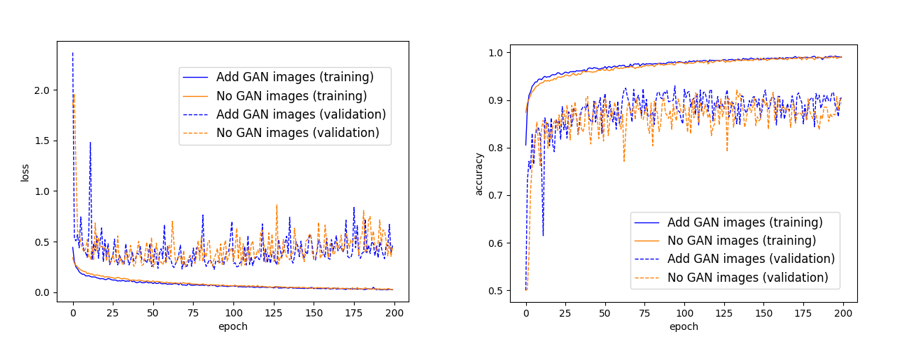
左図を見てまず気づくのが、いずれのモデルも、75エポックあたりから過学習を起こしていることが分かります。つまり、このあたりから学習用データに対する損失関数は下がる一方で、検証用データに対する損失関数は上昇し始めます。これ以上学習を進めても、学習用データに適合しすぎたモデルになってしまい、新しいデータへの汎用性が見込めません。なので、計算は75エポックくらいで止めるのが良さそうです(“Early stopping”と呼ばれる過学習を防ぐための手法)。
右図をみますと、学習用データと検証用データともに、GANによる生成画像で水増しをしたモデルの方が分類精度がわずかに高いのが分かります。
次に今回の学習に関与していないテストデータに対する評価を行ってみます。上の事情から75エポックで保存したモデルを使います。
image_size= (180, 180)
batch_size = 32
# 75エポックで保存されたモデルを用いる
model = load_model('./save_at_75.h5')
test_ds = tf.keras.preprocessing.image_dataset_from_directory(
"Data/test",
seed=1337,
image_size=image_size,
batch_size=batch_size,
)
test_loss, test_acc = model.evaluate(test_ds)
print('test loss:', test_loss)
print('test acc:', test_acc)
結果、生成画像を含めたモデルでは、テスト画像に対する分類精度は0.9375、生成画像を含めていないモデルでは0.9125となりました。なので、テストデータに対する評価に関しても、やはり生成画像を含めて学習したモデルの方が精度がいいことが分かります。
今回用いたDCGANは基本的なモデルであり、最近だとBigGANやVQ-VAE-2などのより高級なモデルも提唱されています。これらの最先端のモデルを用いればもっと鮮明な画像が生成でき、水増しの効果も高まるかもしれません。
7. まとめ
この記事では、DCGANを用いて石油タンクの写った衛星画像を生成してみました。また、このような生成画像による水増しを行うことで、石油タンクの有無に関する分類精度が向上することがわかりました。
データ分析的な観点だけでなく、単純にあなたの地元周辺の衛星データを用いてGANを学習することで、自分の地元の場所っぽい、でも現実には存在しない衛星データなどを作ってみても面白いかもしれませんね!
・参考文献
