Kaggleランカーの9人に聞いた、2020年面白かったコンペ9選と論文9選
9名のKagglerの方にアンケートにご協力いただき、2020年に面白かったコンペと論文を教えていただきましたのでその結果を紹介します。
2020年も数多くのデータ解析コンペが開催され、興味深い論文が多く発表されました。
昨年公開した「Kaggle上位ランカーの5人に聞いた、2019年面白かったコンペ12選と論文7選」は現時点で20,000人を超える方にご覧いただき、Kaggleを始めとするデータ解析コンペへの関心が非常に高まっていると感じました。
そして本年も9名のKagglerの方にアンケートにご協力いただき、2020年に面白かったコンペと論文を教えていただきましたのでその結果を紹介します。
(1)回答いただいたKaggler9名のご紹介
まずは今回のアンケートに回答いただいたのは以下9名のKagglerの方です。
aryyyyyさま(@aryyyyy221)
カレーちゃんさま(@currypurin)
HoxoMaxwell!さま(@Maxwell_110)
nyker_gotoさま(@nyker_goto)
俺人さま(@Oregin2)
恋言さま(@regonn_haizine)
SiNpcwさま(@SiNpcw)
jsatoさま(@synapse_r)
Hiroki Yamamotoさま(@tereka114)
※Twitterアカウント、アルファベット順
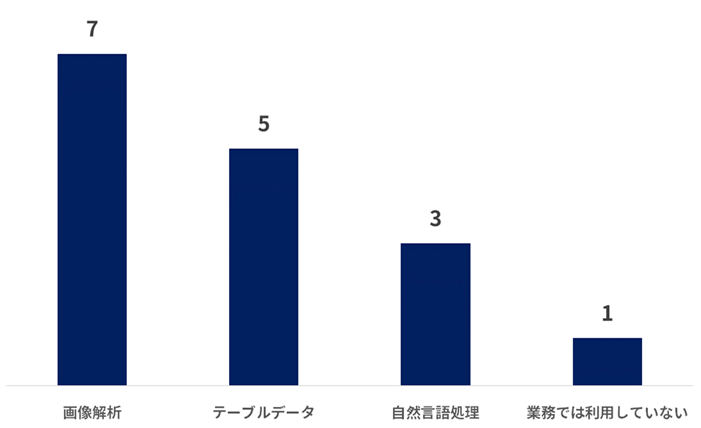
業務でのデータ解析分野
普段業務で利用しているデータ解析分野は、以下の通りです。画像解析を専門にされている方が多いようです。
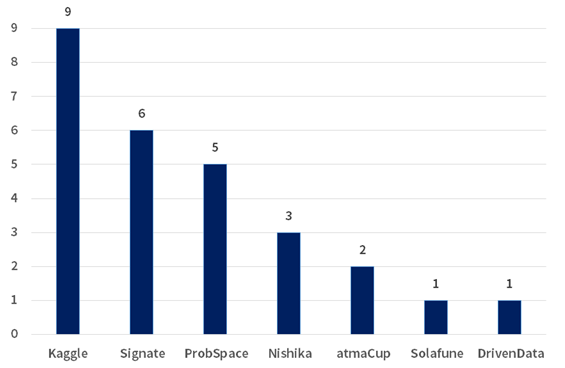
過去に参加したことがあるコンペ・コンペに参加する理由
過去に参加したことがあるコンペは以下の通りです。やはりKaggleが最も多く、次いでSIGNATEのコンペに参加されている方が多いようです。
続いて、コンペに参加している理由を伺ったところ、以下のような理由を回答いただきました。
・参加して順位を競うのが楽しいので参加しています。
・データ分析の勉強になることも参加理由の一つです。
・楽しくて実力もつくから
・深層学習系の技術にはコンペに参加でもしないと触れる機会がありませんので、時間をみつけて積極的に参加するようにしています。
・手法を研究に活用する
・技術の習得や知識の獲得のため。
・自身のスキルアップ、キャリアアップのため
・様々な課題に触れられて実際に使えるものの知見を獲得できる。
・興味はあるが使ったことがない手法などを試すことが出来るため
・他の参加者の解法を見ることで、自分がしらないこと・できていないことを確認でき、レベルアップにつなげることができるとはいえ「楽しいから」が一番大きい理由です。
・最新の解析手法などについて学ぶため
9名がコンペに参加する理由として目立ったのは「楽しいから」「知見を増やす・スキルアップのため」という理由です。
では、実際にどのようなコンペや論文を2020年は面白い、興味深いと思われたのか、回答者のお一人でもある@regonn_haizineさんに解説いただきながら、紹介します。
(2)2020年、面白かったコンペ
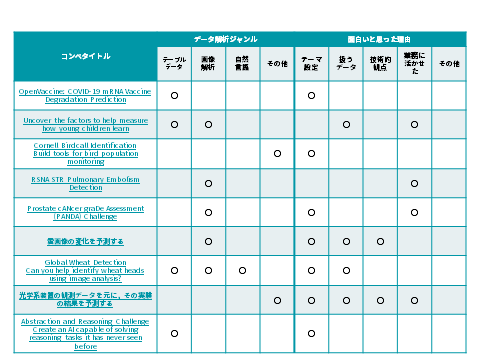
2020年、面白かったコンペとそのジャンルおよび面白い理由をまとめたものが上の表です。
データ解析のジャンル毎に見ていきたいと思います。
・テーブルデータ
・画像解析
・自然言語処理
・その他
テーブルデータ部門
OpenVaccine: COVID-19 mRNA Vaccine Degradation Prediction | Kaggle
色々な配列や構造を持つRNA分子内の塩基位置での分解率を予測するというタスクのコンペティションでした。Kaggleでコロナに関するコンペティションはこれで2回目で、社会に求められているデータに触れたり、知見を共有できるという点でも良いプラットフォームだと考えられます。
コメント(@currypurin)
COVID-19のmRNAワクチンというテーマで、ここでの上位のソリューションがワクチンの安定供給につながる可能性のある、意義深いコンペだったことが面白いと思いました。
【コンペURL】
・OpenVaccine: COVID-19 mRNA Vaccine Degradation Prediction | Kaggle
2019 Data Science Bowl | Kaggle
子供向けの教育アプリの操作ログデータ等から、ユーザが対象のゲームを何回で成功できるかを予測するコンペティションでした。
コメント(@aryyyyy221)
初めてちゃんと参加したコンペでした。社会的な意義もあって、テーブルデータのいろはも学べたので、毎日楽しかったのを覚えています。
コメント(@regonn_haizine)
テーブルデータで複数のログデータなどを連結したりするのに苦労した印象があります。
【コンペURL】
・ 2019 Data Science Bowl | Kaggle
Abstraction and Reasoning Challenge | Kaggle
汎用AIの研究用に作られたベンチマークを題材に扱っていて、IQテストのように画像から規則性を見つけ、隠されている部分の色を当てるというコンペです。
コメント(@regonn_haizine)
最終的には、現状の機械学習のモデルよりも、アルゴリズム的に解く解法が上位になったため、現状のAI技術の限界もみえたコンペティションでした。
【コンペURL】
・ Abstraction and Reasoning Challenge | Kaggle
画像解析部門
RSNA STR Pulmonary Embolism Detection | Kaggle
胸部CT画像から肺塞栓症という病気を発症しているか、また、急性等の症状を予測するコンペティションでした。
コメント(@synapse_r)
評価指標がやや複雑。日常診療でよく出会う肺血栓塞栓症の、サイズの大きいCTデータセットだったので。
コメント(@regonn_haizine)
ここ最近Kaggleでは医療関係のコンペティションが増えてきた印象です。専門知識(ドメイン知識)を持っている人は有利ですが、それでもKaggleの強い人達は上位に入ってくるので驚かされます。
【コンペURL】
・ RSNA STR Pulmonary Embolism Detection | Kaggle
Prostate cANcer graDe Assessment (PANDA) Challenge | Kaggle
PANDAコンペと呼ばれていて、前立腺組織サンプルの画像から、前立腺がんのリスク度合いを反映したISUPという値を予測するコンペティションでした。これも医療x画像データのコンペティションで上位に日本のアカウントの人も多かったです。
コメント(@SiNpcw)
評価データが少ない点が問題ではあるが、各データセットの作り方などは事前に公開されており評価データついてしっかりと考えることが重要なコンペであったこと、汎化性能を問う追加テーマも設定されていたことから。
【コンペURL】
・ Prostate cANcer graDe Assessment (PANDA) Challenge | Kaggle
CDLE HACKATHON 2020 予測性能部門|SIGNATE"
G検定/E資格合格者(CDLEメンバー)のみが参加できるコンペティションでした。メンバー限定のため、詳細な内容が確認できませんでしたが、「雲の動きを捉えた未来の衛星画像を生成する」という生成系の珍しいコンペティションでした。
Kaggleでも生成系だと、Generative Dog Images | Kaggle という犬画像生成コンペがありました。
コメント(@Oregin2)
衛星からの画像データに加えて温度や湿度,風など気象情報も使うことで、いかに精度良く未来の衛星画像を生成するかがポイントでした。宇宙を身近に感じられる良いコンペでした。
【コンペURL】
・ CDLE HACKATHON 2020 予測性能部門|SIGNATE”
Global Wheat Detection | Kaggle
色々な小麦の画像から、穂の部分を検出するコンペティションでした。外部データの利用も認められていて、どのように精度を出していくかは実際の業務に活かせそうです。
コメント(@tereka114)
このコンペティションは学習データとは異なるドメインの評価データを用いています。実際の業務も学習データと異なるドメインのデータで精度を出すことが要求されることが多く、この中でどう精度を出していくのか、実業務に近いため、試行錯誤が面白かった。
【コンペURL】
・ Global Wheat Detection | Kaggle
自然言語処理部門
自然言語処理がメインタスクのコンペティションは選出されていませんでしたが、2020年のKaggleコンペティションでは、Jigsaw Multilingual Toxic Comment Classification | Kaggle や Tweet Sentiment Extraction | Kaggle が開催されていました。
その他部門
Cornell Birdcall Identification | Kaggle
鳴き声から鳥の種類を推定するコンペティションで、弱ラベルという、音声のどのタイミングで鳴いているのかまでは情報として存在しない状態から学習していく必要があるコンペティションでした。
コメント(@Maxwell_110)
・音声認識における弱ラベル学習をテーマとしており,これまで Kaggle で開催されていた多くのコンペとは異なり,求められるタスクに対して与えられているデータのラベルが十分ではない(弱い)コンペでした.
・SED(Sound Event Detection)に準じた手法でこの点(アノーテーションが不十分であるという問題)を解決する試みが多くなされており,現実的な課題に深層学習を適用するという点で非常に興味深いコンペでした.
コメント(@regonn_haizine)
最近も鳥の鳴き声に加えてカエルの鳴き声も一緒に分類するRainforest Connection Species Audio Detection | Kaggle も開催されて、音声データに対する需要も高まっている気がします。
【コンペURL】
・ Cornell Birdcall Identification | Kaggle
#5 atmaCup
atmaCupというatma株式会社が開催しているコンペティションです。5回目の開催で、4回目までは1日程度の短期間で実際の会場に集まりオフラインでコンペティションを行う形式でしたが、今回からはコロナの影響もありオンラインでの開催でした。
コメント(@nyker_goto)
波形データに関する知見が一同に介す場になったことです。このコンペでのタスクは「波形に対応する0-1のラベルをいかに予測するか」であり、主な論点は「一次元波形をどのように処理すれば効果的に予測ができるのか」でした。
コンペ終了後、多数の方々に解法を共有いただいたのですが、私が事前検証で用いていた1D-CNNを使う方がいる一方で、波形から特徴量を作成して勾配ブースティングにかける方法で上位に食い込む方や、Denoising Auto-Encoder / WaveNet を使う手法などなど、多種多様な解法があり、参加者さんのアイディアと引き出しの多さに圧倒されました。NDAの関係で全員にお見せできないのですが、波形データの分析・モデリングに関してこれだけの知見が集まっている場は他に知りませんし、非常に貴重な場になったと感じています。
主催として、atmaCup史上初のオンライン開催でどのぐらい人が集まるのだろうかおっかなびっくりでスタートした回であったので、多数参加コミットしていただいて、知見共有を活発にしていただけたことは大変嬉しく思っています。
【コンペURL】
・ #5 atmaCup
(3)2020年、面白かった論文
続いて、2020年面白かった論文についてご紹介していきます。こちらもデータ解析ジャンルと、面白いと思った理由でまとめると下表のようになります。
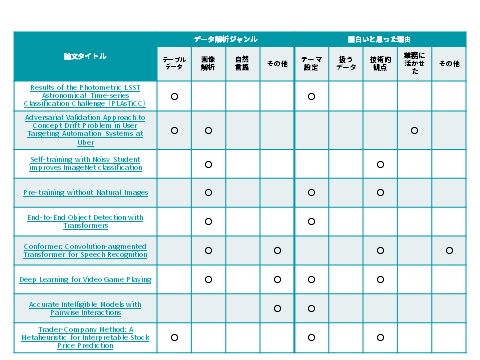
個別の論文について、データ解析のジャンル毎に見ていきたいと思います。
・テーブルデータ
・画像解析
・自然言語処理
・その他
テーブルデータ部門
Results of the Photometric LSST Astronomical Time-series Classification Challenge (PLAsTiCC)
この論文は、Kaggleで2018年に行われたコンペティション(PLAsTiCC Astronomical Classification | Kaggler)の上位解法の論文です。
コメント(@currypurin)
特定のタスクについて、上位の解法が、現在の天文学の最先端を大きく凌駕する(… represent a major improvement over the current state-of-the-art within astronomy.)と書かれてていて、Kaggleのデータサイエンティストの凄さが分かり、面白いと思いました。
コメント(@regonn_haizine)
Kaggleのコンペティションで開催することで、世界中のデータサイエンティスト達が競い合い、専門家を唸らせるような結果を出したりもするのもコンペティションサイトの面白い仕組みですね。
【論文URL】
・ Results of the Photometric LSST Astronomical Time-series Classification Challenge (PLAsTiCC)
Adversarial Validation Approach to Concept Drift Problem in User Targeting Automation Systems at Uber
Adversarial Validationという手法で、トレーニングデータとテストデータがどれだけ似ているかを判断して、未知のデータに対してモデルの再学習が必要であるかなどを判断する基準に使えるようです。
Kaggleの場合だと、トレーニングデータとテストデータの分布などがなるべく一緒になるように、テストデータに似ているトレーニングデータを選んで学習することでテストデータの予測精度を向上させる手法があります。
コメント(@synapse_r)
kaggleのcvの切り方にも活用できる
Trader-Company Method: A Metaheuristic for Interpretable Stock Price Prediction
コメント(@regonn_haizine)
投資手法についての論文です。個人的に機械学習を用いたトレードに興味があり、挑戦していますが現状ロジックベースになってしまい、機械学習を用いて運用し、利益を出していくには色々と困難な部分があります。
そんななか、日本でもトップクラスの企業である、Preferred Networks社と野村アセットマネジメント株式会社が組んで論文を出していて、ロジックベースのものを機械学習のアンサンブルのように運用すると成績が良くなるという手法です。日本語の概要記事もあるので、理解しやすかったです。
【論文URL】
・https://tech.preferred.jp/ja/blog/trader-company/
・ Trader-Company Method: A Metaheuristic for Interpretable Stock Price Prediction
画像解析部門
Self-training with Noisy Student improves ImageNet classification
Kaggle等のコンペティションでもよく見かける、Pseudo Labelingという手法を拡張した手法です。Pseudo Labelingというのは、画像分類などでテストデータの予測結果を再びトレーニングデータに持っていき再度学習をして精度を高める手法です。
この論文では、予測した結果に対してノイズを加えることで、トレーニングデータとテストデータが同じものにならないように工夫をしたり、繰り返しの際にどれだけ精度が向上しているかを定量的に調べている内容です。
コメント(@aryyyyy221)
Kagglerがやりそうな手法だなと思ったので。コンペでも簡単に応用出来そう。あとは論文最後の方にあるAblation Studies参考になりました。
【論文URL】
・ Self-training with Noisy Student improves ImageNet classification
Pre-training without Natural Images
ラベル付きのデータセットであるImageNet等のデータセットでは実際の写真を使うために、データセットの数には限界ができてしまいます。
この論文ではパラメータを変更することができるフラクタル構造を何種類か用いて分類タスク用のデータを生成することで、自動で大量のデータセットを生成でき、事前学習をできるようにしたようです。他の既存のデータセットでの事前学習したモデルと比較した際にも、一部のデータセットやタスクで上回る精度が出ているようです。
コメント(@SiNpcw)
ラベル付きデータを大量に自動生成できる点やImageNetに至らないが近い性能を発揮するモデルの生成ができた点など。
【論文URL】
・ Pre-training without Natural Images
End-to-End Object Detection with Transformers
自然言語処理で利用されるTransformerを物体検出に関する論文です。
コメント(@tereka114)
画像処理=CNNとして認知されている中、自然言語処理で利用されるTransformerが利用されたのが画期的。この論文は物体検出だが、膨大なデータさえあれば、画像認識でも高精度を上げるようになった
コメント(@regonn_haizine)
Transformerはコメントにもある通り、自然言語処理で利用されていましたが、他の分野でも応用される機会が多くなり、Kaggleのコンペでも上位解法で見かける機会が多くなりました。
【論文URL】
・ End-to-End Object Detection with Transformers
自然言語処理部門
アンケートでは該当なしでしたが、2020年は以下のTransformerを使った GPT-3 という OpenAI が開発している「文章生成言語モデル」が話題になりました。
Language Models are Few-Shot Learners
学習するパラメータが巨大なため、一般の個人や企業では学習できないようなモデルのため、APIとして公開され、自然言語を理解できる驚くべきアプリケーションが色々と作成されました。
【論文URL】
・ Language Models are Few-Shot Learners
その他部門
Conformer: Convolution-augmented Transformer for Speech Recognition
コメント(@Maxwell_110)
・現在、多くの分野で Transformer 系のモデルが応用されはじめていますが,画像認識の分野でもこれまで主流であった CNN 系のモデルにとって変わるかどうかは注目されていると思います。とはいえ、Transformer 系のモデルが大域的なコンテキストとその関係性を抽出するのが得意な一方で、CNN 系のモデルは局所特徴量や周波数的特徴を抽出するのが得意であり、お互いに長所・短所があると思います。この論文はその両者の良いところをうまく利用しようという試み(Muliti-Head Self Attention Module と CNN Module を Feed Foward Module で挟んだ macaron-like な Conformer encoder の提案)がなされている点で興味深いものでした。
・また、Conformer が検証しているタスクは ASR(Automatic Speech Recognition)ですが、入力特徴量はスペクトログラム,ある意味,画像データに近いものですので,音声認識の分野に限らず、通常の画像分野のタスクにも応用できるような技術要素を示唆していると思います。
・さらに、DCASE2020 Challenge の task4 において、Conformer base のモデルが大きな差をつけて 1 位を獲得しており、コンペでもその有効性が示唆されていることから、手法の汎用性があるのではないかとかなり期待しています。
【論文URL】
・Conformer: Convolution-augmented Transformer for Speech Recognition
【参考】
・Solution Blog (LINE Engineering)
・DCASE2020 task4
・Leaderborad (Result)
コメント(@regonn_haizine)
こちらの論文では、Transformerを音声認識でも利用できるようにしています。
Deep Learning for Video Game Playing
DQNというモデルをベースに最初はAtariという平面上を動くゲームからマインクラフトのような3Dで動けるゲームへの発展の歴史がわかります。特に深層強化学習ですと色々なモデルが登場しているので、その流れを追うにも良い論文でした。
コメント(@Oregin2)
ゲームへの深層強化学習の発展がまとめられていて面白かった。 年代別の手法がアプローチごとに色分けされてまとめられた図が良かった。
【論文URL】
・ Deep Learning for Video Game Playing
Accurate Intelligible Models with Pairwise Interactions
コメント(@nyker_goto)
去年はモデルの解釈性に興味を持っていろいろ調べていて、最近良く使う interpret の ExplainableModel の元になった論文、という文脈で読んだものです。ですので、この論文単体というよりは解釈性一般についていくつか読んでいて、その一つというのが正しいでしょうか。
機械学習モデルの解釈性が重要であることはご承知のとおりだと思います。僕の経験でも、仕事などで機械学習モデルを作成する際には、その予測能力だけでなくなぜその予測につながっているか・特にどの変数が大事なのかといった説明性を要求される場がとても多いです。素朴な線形モデルの重みや、勾配ブースティングの importance、LIME、SHAP と様々なフレームワークがありますが、その中でも個人的に GAM (Generalized Additive Model) が好きで、表題の論文は、その発展形である GA2M (Generalized Additive Models plus Interactions) を提案したものです。
【参考】
・https://www.slideshare.net/DeepLearningLab/glm-gam
・https://christophm.github.io/interpretable-ml-book/
一般に、解釈性は予測性能とトレードオフであると言われています。例えば線形モデルが勾配ブースティングに勝てることはほぼありません。
GA2MではGAMに交互作用項をつけることで、解釈性をたもったまま性能向上させることが可能であると、論文中では主張されています。
流石にカリカリにチューンした勾配ブースティングには勝てる場合は少ないとは思いますが、モデルから得られる情報はとても多いので、場合によってはこちらを使う方が良い場面も多々あるな、と感じました。(実際案件でも使ったことがあります。)
コメント(@regonn_haizine)
「説明可能AI」(Explainable AI)は、より公平でバイアス等が生じないようにするための「責任あるAI」 (Responsible AI) の実現のためにも注目されている領域です。
【論文URL】
・ Accurate Intelligible Models with Pairwise Interactions
(4)今後のデータ解析コンペや技術への期待と目標
最後にKagglerの皆様に今後のコンペや技術への期待や目標をお伺いしました。
今後どのようなコンペがあると面白いと思いますか?
興味のあるデータの種類や、新しい評価軸などの観点でのコメントをいただきました。
●データの種類
・医療系データ(やってほしい)
・画像とセンサや音など複数のデータを組み合わせたコンペ。
・衛星画像データや、天体観測データを用いたコンペ
●コンペの種類
・評価は難しいが自動生成系のコンペティションがあると面白い。2019年の Kaggle コンペにはあったけど、2020年には無かったはずなので、2021年には復活してもらえると、技術の進歩を見ることができそう。
●評価方法の多様化
・推論の実行時間に制限のあるテーブルデータのコンペがあると面白いと思います。
・Kaggle に限ってのお話となりますが,現在の Kaggle では「Kernel コンペ」という形で,推論時間の制約を元にしたモデルの軽量性を間接的に評価するコンペがあります.こういった形に限らず,モデルの学習時や推論時の環境負荷やモバイル機器への応用などをより野心的に評価するようなコンペが試験的にでも多く行われてくると面白いと思います.
・ランキング + アイディアの面白さで決まるコンペなどあると面白いかなと思いました。例えば上位入賞者がソリューションを公開し、他のユーザーの投票と順位を加味して最終順位が決定する、など。
●求められるスキル
・より複雑なタスク、知識だけではなく知恵を絞らないと勝てないような設計のコンペ
・動画の解析系、現行進んでいるNFLのコンペはやることが多く、純粋なモデリング技術以外も必要となっている。
今後どのような技術が生まれると面白いと思いますか?
新しい技術への質問には、技術的なブレイクスルーを期待する声や、計算コストに関する技術、また、世の中で起きている課題を解決する技術という視点でのコメントがありました。
●技術的なブレイクスルー
・シンプルに画像でbreak through来て欲しい
・Transfomerのように各分野の分析をブレイクスルーする技術
・TransformerでもCNNでもない画像処理の技術が出てこれば相当画期的だと思います。直接的にはやくにたたないけど、人間が面白いと思う技術
・単語を数個言うだけで大体の文章を作ってくれる生成モデルがほしい。
●計算コストに関するアプローチ
・Transformer 系のモデルが自然言語以外の分野でも応用され始めていますが,より計算コストが低いモデルが,これまで以上に発表されてくることを楽しみにしています.
・画像や自然言語のデータの学習にはGPUが必要だったり、時間がたくさんかかったりするので、GPUが使いやすくなり高速化するとまたできることが増えて面白くなると思っています。
●現在起きている世の中の規模の課題を解決する技術
・地球規模で温暖化の要因を制御する技術
・衛星画像のデータだけでなく、地上のセンサーデータが増えてきて、人口が減っていく中での都市の効率化へ向けた技術
2021年の目標を教えてください
Kaggleでのさらなる飛躍や、そこで得た知見の適用、もっと別の分野への興味を広げている方もいらっしゃいました。
●Kaggleやその他コンペでの挑戦
・Kaggle GrandMasterになるために金メダルをとりたいです。
・今年こそ、GMになりたいです。
・kaggleを通して勉強するのが自分に合っていると感じるので、なるべくたくさんのコンペに出ていきたいと思っています。皆さん対戦よろしくお願いします。
・医療画像や衛星画像における深層学習コンペに参加していきたいと思っています.特に衛星画像系のコンペはなかなか Kaggle では開催されませんので,今後は SIGNATE なども含めて参加するプラットフォームを広げていけたらと思っています.
●コンペなどで得た技術の適用
・専門分野の勉強と機械学習が適用できる領域の模索
・kaggleなどの参加を通じての技術獲得や得た技術の案件適用など。
・強化学習をロボットに生かす技術
●新しい分野への挑戦
・知らないことを知れるように、いろんなことにチャレンジしたいです。最近は人間の振る舞い・思考に興味があるので、デザインや、考え方について学んでいきたいです。あと、日本語をもっとよみ・かけるようになりたいです!
・量子コンピュータやxR技術も新しい技術・機器が2020年に主にハードウェア側で出てきているので、2021年はソフトウェア側の需要が高まると思い、そこらへんの技術も触っていきたい。
(5)Kagglerの皆様に聞いた衛星データ使ってやってみたいこと
最後に、本記事を掲載している「宙畑(そらばたけ)」が宇宙ビジネスメディアということで、「衛星データ」についてもお伺いしました。地球規模での課題解決やより衛星データを使いやすくするという視点でコメントをいただきました。
・衛星データを扱うコンペに参加してみたいです。
・既に多くの関連論文や開発などがあると思いますが,時点間での経済活動の量(人々の交通量や工場の稼動量など)の変化の分析に興味があります.また,自然環境の変化や経済活動の変化量との相関などにも強い興味をもっています.コロナ禍前後におけるこういった変化を分析するのも良いテーマかもしれないですね.
・交通輸送網効率化など都市計画・解析
・衛星データから温暖化ガス発生状況を把握して、その結果から電力のベストミックスをコントロールする技術。具体的には発電の種類の割合変化に応じた環境負荷の増減を報酬とする強化学習の仕組み。
・交通状態の把握、コロナ環境下で大きく変わっていそうな内容の一つ
・あまり衛星データに詳しくないのですが、人が簡単にはいけないジャングルや極地での動物の活動状況などを定量的に評価できたりすると、新しい発見があって面白そうだなと思いました。
・より衛星データを使いやすくするための、衛星データの機械学習での高解像度化や、最近よく聞く小型衛星のデータをまとめてデータ生成。
(6)2020年に開催された衛星データコンペ
衛星データに関するコンペは2020年に5つ開催されています。
SIGNATE
日本のコンペティションサイトのSIGNATEでは、オススメのコンペティションであった、CDLEメンバー限定のコンペティションや、Tellus Satellite Challengeの4回目が開催されました。Tellus Satellite Challenge(今回は海岸線予測)の上位入賞チーム解法は記事にまとめられています。
【コンペURL】
・CDLE HACKATHON 2020 予測性能部門|SIGNATE
・The 4th Tellus Satellite Challenge:海岸線の抽出
【参考】
・The 4th Tellus Satellite Challenge実施!~入賞者たちの手法を解説~ | 宙畑
SpaceNet 6, 7
SpaceNetという地理空間アプリケーションのマッピング(建物や道路の検出等)のためのオープンソースの人工知能応用研究をサポートしている非営利団体が主催のコンペティションです。2020年では6回目と7回目が行われました。
6回目では雲が発生して光学データとSARデータを組み合わせて建物形状検出であったり、7回目は時系列での建物の形状を衛星画像から読み取るタスクでコンペティションが行われました。
【サイトURL】
・ SpaceNet 6, 7
Solafune
衛星データ専用のコンペティションサイトが2020年に始まりました。1回目は空港の利用者数予測で、現在は2回目の夜間光での土地価格予測コンペティションが開催中です。Solafuneの公式DiscordCommunityもコンペティションの知見が共有されているので、参考になります。
【サイトURL】
・ Solafune
Kaggle
2020年にはKaggleでメダル対象となる衛星データ(リモートセンサーデータ)コンペティションは開催されませんでした。2019年11月には雲のコンペティション Understanding Clouds from Satellite Images | Kaggle が開催されていたので、そろそろ出てくるかなと期待しています。
(7)2020年、面白かった衛星データ解析に関する論文
2020年に公開された衛星データを実際に触っていて気になっている部分を解決してくれそうな論文を紹介していきます。
・
A Remote Sensing Image Dataset for Cloud Removal
衛星画像を探していると、光学画像で雲が邪魔で欲しいデータが足りない場合も多く、この論文では雲除去をするためのニューラルネットワークモデルを訓練するためのデータセットを提供してくれています。
・
Cross-Sensor Adversarial Domain Adaptation of Landsat-8 and Proba-V images for Cloud Detection
同じ場所でのデータを探している場合に、別の衛星のデータを使う場合もあると思いますがこの論文では Landsat-8 と Proba-V 画像の統計的差異を低減する変換を提案していて、汎用的に使える他、コスト関数に専用の項目を含ませることで、雲検出等の特定のリモートセンシングアプリケーションでの性能を向上させることが可能になるみたいです。
・
Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network
低解像度でのリモートセンシング画像で車のような小さめの物体検出は難しいですが、エッジの強化と解像度強化のGANを用いることで、検出精度が向上しているようです。
・
Quantization in Relative Gradient Angle Domain For Building Polygon Estimation
SpaceNetでの結果などを見てもらうとわかりやすいですが、セグメンテーションタスクで建物を予測した際には、1px毎に予測が行われているため直線ではなくグニャグニャな線で覆われています。この論文では構造物のドメイン知識を加えることで、建物をポリゴン的に直線で予測することが可能になるみたいです。
・
Vision Transformers for Remote Sensing Image Classification
何度も出てきているTransformerについても衛星データ関連でも出てくるようになりました。
この論文は2021年のものですが、Vision Transformer(ViT)を使って衛星画像のクラス分類をして、既存タスクの精度を向上できていることが書いてあります。
(8)まとめ
本記事では、Kaggler9名の方にご協力いただき、2020年の面白かった機械学習コンペや論文について、ご紹介をしました。
コンペについては、Kaggleではコロナ関連のコンペティションも含めて医療分野のコンペティションが増えてきた傾向があります。また、Kaggleでは強化学習向けのコンペティションもはじまり、今までのテーブルデータとは違ったタスクでのデータ分析技術が求められるようになってきたように感じます。
全体を通しても、画像タスクの注目度やTransformerに関する応用が目立っているように思います。また、Kaggleでも始まった強化学習系もありましたね。特に画像系は衛星画像のようなリモートセンシング技術とも相性が良いので、衛星データ関連のモデルにも今後影響してくると思います。
さらに、「衛星データ」についても、2020年に実施されたコンペの概要や面白かった論文についてご紹介し、Kagglerの皆様から「衛星データ」への期待もお伺いしました。「衛星データ」が持つ特徴を活かし、マクロな課題への解決に期待する声が多く見られました。
近年、数多くの人工衛星が打ち上げられ、それに合わせて撮影される衛星データも爆発的に増えて来ています。これまでは人の目や手作業で判読していた衛星データですが、その量が増えるため、機械学習を使った衛星データの解析はさらに広がる分野と考えられ、非常に注目が集まっています。
例えば、こちらのサイトでは毎月、地球観測データ×機械学習のトピックがまとめられています。
本メディア「宙畑」でも、機械学習×衛星データの事例や論文解説を行っています。
ご興味を持っていただけた方はぜひご覧いただければと思います。
