衛星データを使って市区町村の緑地率を算出して平均寿命・自殺率との相関を調査してみた
緑地の多さが認知症や脳卒中と関係があるとの論文を見つけました。ということは、緑地率と平均寿命・自殺率とも関係があるだろうという仮説のもと、Google Earth Enginとオープンデータを使って、市区町村の緑地率と平均寿命・自殺率との相関関係を調査してみました。
はじめに
自然に囲まれると心が穏やかになる……なんとなくそんな気がするというくらいの感覚は持っていたのですが、住宅地の緑地率がうつ病・認知症予防に効果がある(https://forbesjapan.com/articles/detail/47497)といった記事や、近隣の緑地の多さと脳卒中のリスクに関係があるといった論文(https://www.ahajournals.org/doi/10.1161/str.52.suppl_1.P631)を見つけました。
どうやら住環境の周辺の緑の量は、本当に心身の健康と関係があるようです。
そこで、緑地の多さが認知症や脳卒中と関係があるのであれば、緑地率と平均寿命・自殺率とも関係があるだろうという仮説のもと、Google Earth Enginとオープンデータを使って、市区町村の緑地率と平均寿命・自殺率との相関関係を調査してみます。
相関が強ければ、さっそく移住もしくは植林の計画を立てたいところ……。それでは調査をしていきます。
扱うデータについて
緑地率の算出について
今回はSentinel-2の光学画像からNDVI(Normalized Difference Vegetation Index)と呼ばれる植物の茂り具合を示す指数を算出し、緑地率を推定します。
Sentinel-2は欧州の地球観測ミッションの人工衛星であり、Google Earth Engine等で無料で扱うことができます。
https://developers.google.com/earth-engine/datasets/catalog/COPERNICUS_S2_SR
NDVIをはじめ、様々な指数については過去の記事で紹介されていますので、是非読んでみてください。
課題に応じて変幻自在? 衛星データをブレンドして見えるモノ・コト #マンガでわかる衛星データ
平均寿命のデータについて
平均寿命の情報は日本の統計が閲覧できる政府統計のポータルサイトであるe-Stat(https://www.e-stat.go.jp/regional-statistics/ssdsview/municipality)から取得します。
e-Statでは、平均寿命に限らず、各省庁が公表するさまざまな統計データがまとまっています。
今回は以下のページから取得できる、市区町村別の平均余命(0歳)を扱います。
https://www.e-stat.go.jp/regional-statistics/ssdsview/prefectures
自殺率のデータについて
自殺率のデータは、厚生労働省のサイトで公開されているデータ(https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000197204_00007.html)を利用します。
Sentinel-2のデータから緑地率を求める流れ
本記事では以下の流れに沿って緑地率を推定します。
① 2021年5月~9月のSentinel-2の光学画像のリスト(ImageCollection)を取得します。この時、被雲率が70%以上の画像は取り除きます。光学画像の取得時期はこちらの論文を参考にしています。
② それぞれの画像に対して、雲と判定されたピクセルをマスク処理します。マスク処理とは特定の部分を抽出し、それ以外の部分を表示しないようにする処理のことをいいます。
③ マスク処理した画像の各ピクセルの中央値を持った画像を作成します。
④ 赤と近赤外の波長の画像を用いてNDVI画像を作成します。
⑤ 市区町村のgeometryで画像をクリップします。
⑥ 画像に含まれる全ピクセル数を数えます。
⑦ 事前に設定したNDVI閾値以上の値を持つピクセル数を数えます。
⑧ ⑥と⑦の結果から緑地率を算出します。
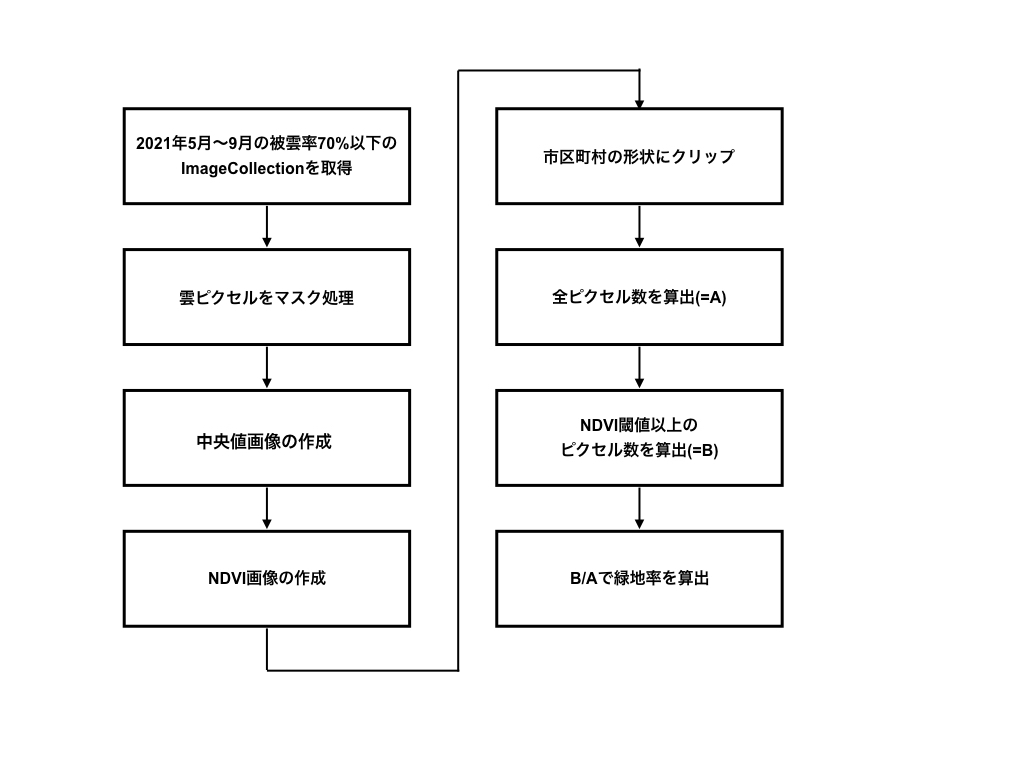
緑地率を算出するための閾値を決める
緑地率は、市区町村ごとの全てのピクセル数に対する緑地のピクセル数で算出します。
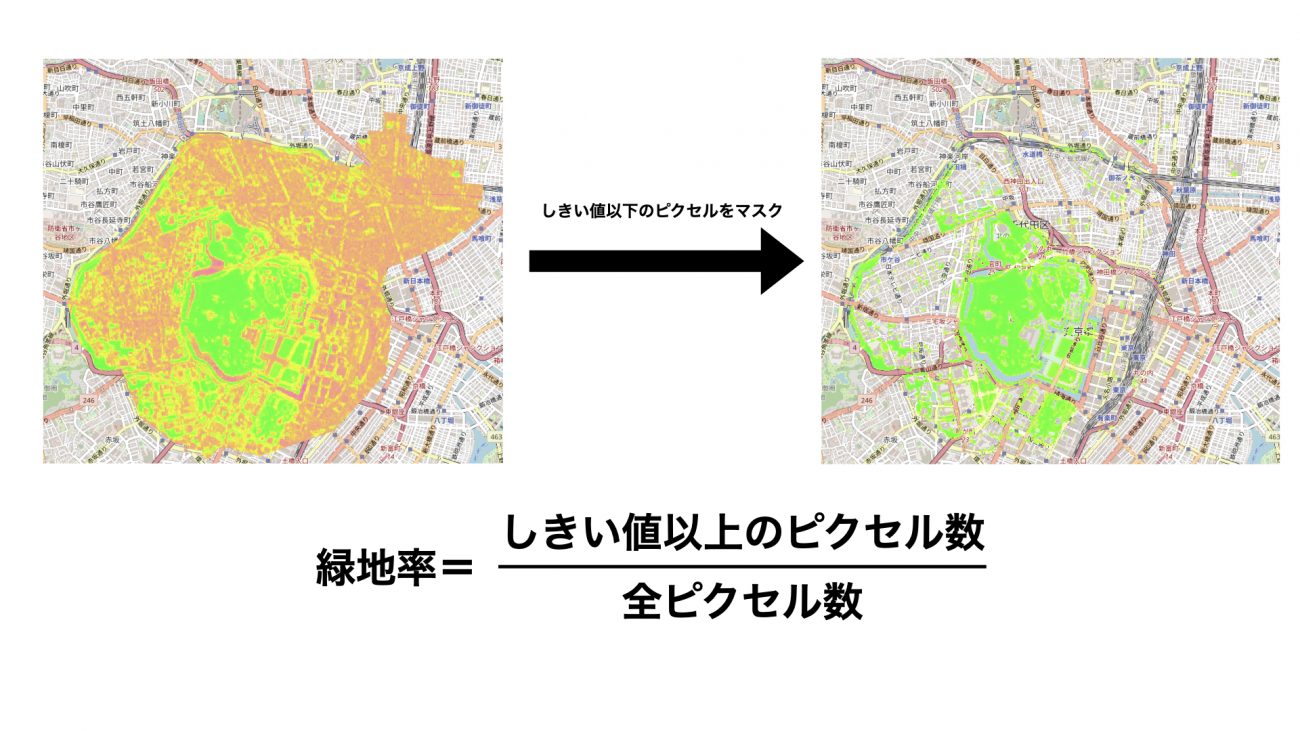
あるピクセルが緑地かどうかの判定は、NDVIの値が閾値以上かで行います。NDVIを用いた緑地率の算出を行っている文献によれば、「1ピクセル内に緑地・非緑地が混在するような空間分解能が粗い衛星画像を用いて様々な地域を評価する場合、最適な閾値は一つに決まらない」とあります。
これは、都市部では1ピクセル内に緑地と非緑地が混在するケースが多く、そのような緑地を検出するには低い閾値が望ましいものの、郊外にある公園などのまとまった緑地周辺の混在ピクセルを過大評価しないためにはある程度高い閾値が適切となるためです。
ただし、本記事では簡単のため一つの閾値を定めて緑地率の算出を行います。さらに詳細な解析が行いたい場合は参考文献を参照して閾値変更をしてみてください。
今回は埼玉県の市区町村の緑地率について、衛星データを用いて算出した値と行政から公開されている値を比較して、誤差が最も小さくなるNDVI閾値の値を求めます。
事前の調査で閾値が0.30~0.50程度の時に概ね妥当な緑地率が算出できると予想できたため、本記事では閾値を0.30~0.50まで0.01刻みで変化させて、誤差の評価を行います。
埼玉県の市区町村の緑地率は埼玉県のホームページで公開されており、本記事では下記資料を参考にしました。
https://www.pref.saitama.lg.jp/documents/180232/0301.pdf
まずはライブラリをインポートします。
import numpy as np
import pandas as pd
import warnings
import json
warnings.filterwarnings('ignore')
# reminder that if you are installing libraries in a Google Colab instance you will be prompted to restart your kernal
try:
import geopandas as gpd
except ModuleNotFoundError:
if 'google.colab' in str(get_ipython()):
print("package not found, installing w/ pip in Google Colab...")
!pip install geopandas
else:
print("package not found, installing w/ conda...")
!conda install mamba -c conda-forge -y
import geopandas as gpd次に、GEEの認証とモジュールのインポートを行います。GEE認証を実行すると認証に必要なURLが表示されるので、URLへアクセスしてGoogleアカウントを指定し、表示された認証コードをGoogle Colabのボックスへコピペしてください。
try:
ee.Initialize()
except Exception as e:
ee.Authenticate()
ee.Initialize()2021年5月から9月のSentinel-2の光学画像のうち、被雲率が70%以下のImageCollectionを取得します。
# 2021年8月のSentinel-2のImageCollectionの取得
s2_without_cloud = ee.ImageCollection('COPERNICUS/S2_SR').filterDate('2021-05-01', '2021-09-30').filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE',70))続いて、埼玉県の市区町村ごとのポリゴンデータを取得します。
ポリゴンデータとは、簡単に言えば緯度経度を持った形状のデータのことで、日本の市区町村ごとのポリゴンデータは国土交通省のサイト(https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-N03-v3_0.html)からダウンロードすることができます。サイトからダウンロードした埼玉県の市区町村のポリゴンデータをGeoPandasで読み込みます。
filepath = '埼玉県の市区町村のgeojsonのファイルパスをここに貼り付けてください'
# Geopandasで埼玉県のポリゴンデータを取得
gdf = gpd.read_file(filepath, encoding='cp932')
gdf埼玉県のポリゴンデータをGeoPandasで読み込むことができました。
“N03_004”列に市区町村名、”N03_007”列に行政区域コードが格納されています。
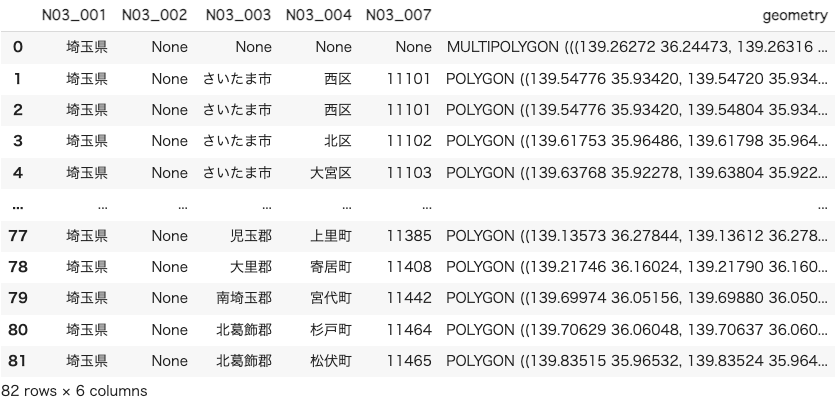
取得した埼玉県のポリゴンデータには1つの行政区域で複数行のデータを持っているものがあります(図2の西区のようなケース)。
これは飛び地のある行政区域があるためです。これらを1つのポリゴンデータにまとめるためにデータを結合する必要があります。
このような場合はGeoPandasの.dissolve()を適用することでデータを結合できます。今回は行政区域コード(N03_007)をキーとしてデータを結合します。
#データの結合
dissolved = gdf.dissolve(by="N03_007")
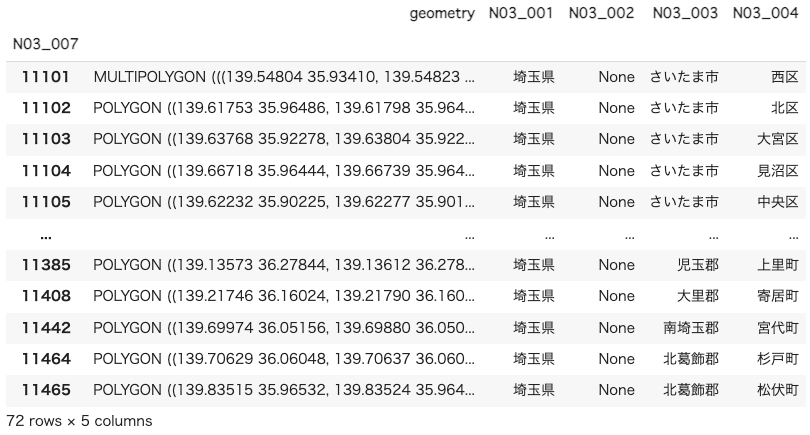
dissolvedデータを結合することができました。
結合前は2行でそれぞれポリゴンデータを持っていた西区ですが、結合後は1行にまとめられマルチポリゴンというデータになっていることがわかります。
次に比較するデータを読み込みます。
上で紹介した公開されている埼玉県の緑地率のデータ(https://www.pref.saitama.lg.jp/documents/180232/0301.pdf)をExcelやGoogleスプレッドシートに転記してcsv形式で出力し、pandasで読み込みます。
※後に扱うポリゴンデータとの兼ね合いで、さいたま市のデータは割愛してcsvを作成しています。
fp = "作成したcsvデータのファイルパスをここに貼り付けてください"
df_gsr_ref = pd.read_csv(fp, sep=",")
df_gsr_ref無事に読み込むことができました。
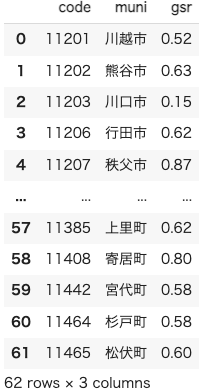
ここからは衛星画像を処理していきます。
まずは雲ピクセルのマスク処理を行う関数を定義します。今回使用するSentinel-2では”QA60”のバンドに雲の情報が格納されています。QA60はBit10とBit11にデータが存在しており、Bit10の値が1であれば雲あり、Bit11の値が1であれば巻雲ありとなっています。引数で与えられた画像から、QA60バンドで「Bit10が0かつBit11が0」となっているピクセル以外をマスクし、マスク画像を返します。
詳細はカタログページ(https://developers.google.com/earth-engine/datasets/catalog/COPERNICUS_S2_SR#description)を参照してください。
# 雲ピクセルのマスク処理
def cloudmask(img):
qa = img.select('QA60')
cloudmask = 1 << 10
cirrusmask = 1 << 11
mask = qa.bitwiseAnd(cloudmask).eq(0) and (qa.bitwiseAnd(cirrusmask).eq(0))
return img.updateMask(mask).divide(10000)上で定義した関数(cloudmask)とSentinel-2のImageCollectionを用いて雲ピクセルのマスク処理をします。map関数を用いてImageCollectionのそれぞれに対して雲ピクセルのマスク処理を行い、.median()で月間の中央値画像を作成します。
s2_mask = s2_without_cloud.map(cloudmask).median()NDVI画像を作成する関数を定義します。NDVIは赤(red)と近赤外(nir)の波長から、以下の式を使って算出します。
NDVI=(nir-red)/(nir+red)
Sentinel-2のバンドは、B4に赤、B8に近赤外が格納されています。引数で与えられたimageから、B4とB8を取得して上述の処理でNDVIを算出し、返す関数になっています。
# NDVI
def get_ndvi(img):
red = img.select('B4')
nir = img.select('B8')
numerator = nir.subtract(red)
denominator = nir.add(red)
ndvi = numerator.divide(denominator).rename("NDVI")
return ndvi上で定義した関数(get_ndvi)と雲ピクセルをマスク処理した中央値画像(s2_mask)を用いて、NDVIを算出します。
ndvi = get_ndvi(s2_mask)GeoPandasからGEEで扱う形式のgeometryを作成する関数を定義します。
データ結合したテーブル(dissolved)はindexが行政区域コードになっているため、引数で与えられたindexから行政区域毎のgeometryを作成します。
# GeopandasからGEEで扱う形式のgeometryを作成する関数
def get_aoi(index, dissolved_df):
if dissolved_df.loc[index].geometry.geom_type=='MultiPolygon':
g = [geom for geom in dissolved_df.loc[index].geometry]
imax = len(g)
else:
g = [dissolved_df.loc[index].geometry]
imax = 1
features = []
for i in range(imax):
x,y = g[i].exterior.coords.xy
coords = np.dstack((x,y)).tolist()
features.append(coords)
aoi = ee.Geometry.MultiPolygon(features)
return aoi緑地率を算出する関数を定義します。引数として、元のimage、閾値以下のピクセルをマスク処理したimage、対象の領域のgeometry(aoi)を受け取ります。それぞれのimageをaoiでクリップし、ee.Reducer.count()でそれぞれのimageのピクセル数を数えて、閾値以上のピクセル数を全てのピクセル数で割って緑地率を求めます。
def get_green_space_ratio(img, img_mask, aoi):
img_clip = img.clip(aoi)
img_mask_clip = img_mask.clip(aoi)
count1 = img_clip.reduceRegion(reducer=ee.Reducer.count(),scale=50,geometry=aoi)
count2 = img_mask_clip.reduceRegion(reducer=ee.Reducer.count(),scale=50,geometry=aoi)
gsr = count2.getInfo().get('NDVI') / count1.getInfo().get('NDVI')
return gsr市区町村ごとにNDVI閾値を0.30から0.40まで0.01刻みで変更して、公開されているデータとの誤差を求めます。上で定義した関数で市区町村ごとに緑地率を求めて、公開されているデータとの二乗誤差をデータフレーム(df)に格納していきます。
ndvi_th_list = np.round(np.arange(0.3, 0.5, 0.01), 2)
df = pd.DataFrame()
for i in range(len(df_gsr_ref)):
code = str(df_gsr_ref.at[i, 'code'])
ref_gsr = float(df_gsr_ref.at[i, 'gsr'])
aoi = get_aoi(code, dissolved)
df.at[i, "code"] = code
for ndvi_th in ndvi_th_list:
ndvi_mask = ndvi.updateMask(ndvi.gt(ndvi_th))
gsr = get_green_space_ratio(ndvi, ndvi_mask, aoi)
del_gsr = ref_gsr - gsr
square_del_gsr = del_gsr**2
df.at[i, str(ndvi_th)] = square_del_gsr
dfNDVI閾値ごとの二乗誤差を持ったデータフレーム(df)が作成されました。
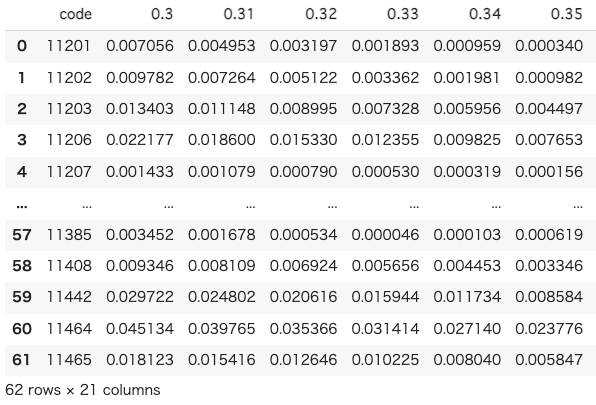
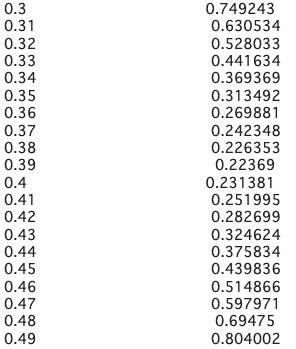
それぞれのNDVI閾値ごとの二乗誤差の和を求めます。
df.sum()NDVI閾値ごとの二乗誤差の和が算出できました。これを見ると、NDVI閾値が0.39のときに最も誤差が小さいということがわかります。
NDVI閾値を0.39に設定して再度埼玉県の緑地率を算出し、公開されている緑地率との比較結果を表示します。
ndvi_mask = ndvi.updateMask(ndvi.gt(0.39))
for i in range(len(df_gsr_ref)):
code = str(df_gsr_ref.at[i, 'code'])
aoi = get_aoi(code, dissolved)
gsr = get_green_space_ratio(ndvi, ndvi_mask, aoi)
df_gsr_ref.at[i, "sentinel2"] = gsr
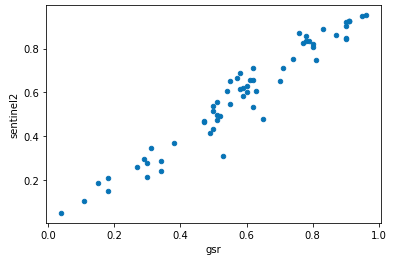
df_gsr_ref.plot.scatter(x='gsr', y='sentinel2')
x, y = df_gsr_ref['gsr'], df_gsr_ref['sentinel2']散布図をみると、公開されているデータと概ね近い値を求められていることがわかります。本記事ではNDVI閾値を0.39として全国の市区町村の緑地率を求めたいと思います。
市区町村ごとの緑地率を算出する
緑地率の閾値が決まったら、いよいよ市区町村ごとの緑地率を算出していきます。
まずは国土交通省のサイトからダウンロードした全国の市区町村のポリゴンデータをGeoPandasで読み込み、行政区域コード(N03_007)をキーとしてデータを結合します。
filepath = '全国の市区町村のgeojsonのファイルパスをここに貼り付けてください'
# Geopandasで全国のポリゴンデータを取得
gdf_all = gpd.read_file(filepath, encoding='cp932')
#データの結合
dissolved_all = gdf_all.dissolve(by="N03_007")
dissolved_all続いて、NDVI閾値を0.39にしたマスク画像(ndvi_mask)を用いて、全国の市区町村の緑地率を求めます。
# 処理時間が長いため、結果をcsvへ保存し、次回再実行を避ける
df_gsr = pd.DataFrame(index=[], columns=["code", "muni", "GreenSpaceRatio"])
print("対象データ数 : " + str(len(dissolved_all)))
for i in range(len(dissolved_all)):
code = dissolved_all.index[i]
if dissolved_all.at[dissolved_all.index[i], "N03_003"] == None:
muni = dissolved_all.at[dissolved_all.index[i], "N03_001"] + dissolved_all.at[dissolved_all.index[i], "N03_004"]
else:
muni = dissolved_all.at[dissolved_all.index[i], "N03_001"] + dissolved_all.at[dissolved_all.index[i], "N03_003"] + dissolved_all.at[dissolved_all.index[i], "N03_004"]
aoi = get_aoi(code, dissolved_all)
gsr = get_green_space_ratio(ndvi, ndvi_mask, aoi)
df_gsr = df_gsr.append(pd.Series([code, muni, gsr], index=df_gsr.columns), ignore_index=True)
df_gsrこれで全国の市区町村の緑地率のデータフレームが完成しました。
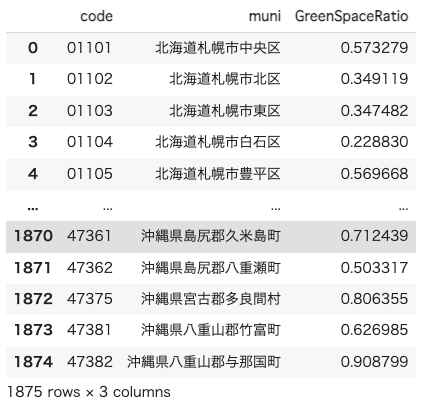
平均寿命と自殺率のテーブルを作成する
全国の市区町村毎の平均寿命(平均余命(0歳))と自殺率のデータフレームを作成します。
まずは平均寿命のデータフレームを作成します。e-Statからダウンロードしたcsvファイルを読み込んで、寿命データのない行を削除してデータを整えます。
# 平均余命csvファイルの読み込み
filepath_lifespan = 'e-Statからダウンロードしたcsvのファイルパスを貼り付けてください。'
df_lifespan = pd.read_csv(filepath_lifespan, encoding="CP932", header=1).drop(columns=["調査年 コード", "調査年", "/項目", "地域"])
# 余命データが無い行を削除(「-」を削除)
df_lifespan.drop(index = df_lifespan[df_lifespan['I1101_平均余命(0歳)(男)【年】'] == '-'].index, inplace=True)
df_lifespan.drop(index = df_lifespan[df_lifespan['I1102_平均余命(0歳)(女)【年】'] == '-'].index, inplace=True)
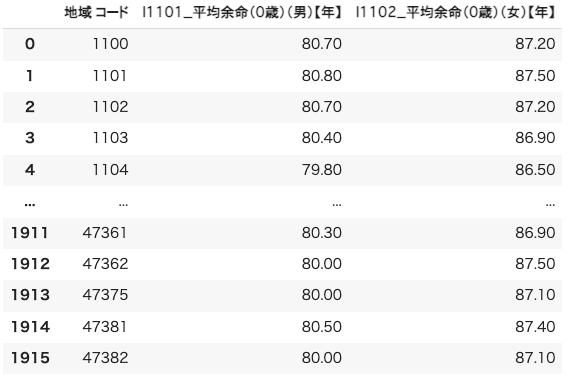
print(df_lifespan)
df_lifespan平均寿命のデータフレームが完成しました。
次に自殺率のデータフレームを作成します。
ダウンロードしたエクセルファイルを確認すると、市区町村コードの末尾一桁に不要な数字が入っているため、この段階で削除しておきます。
# pandas.read_excelの関連ライブラリを最新化
# 必要があれば実行してください
# !pip install -U xlrd
# 自殺数excelファイルの読み込み
filepath_suicide = '警察庁のサイトからダウンロードしたエクセルファイルのファイルパスを貼り付けてください'
df_suicide = pd.read_excel(filepath_suicide, usecols = [1, 5], skiprows=[0, 1, 2], header=0, skipfooter=1)
# 最初3行無駄な行を削除
df_suicide = df_suicide.drop(df_suicide.index[[0, 1, 2]])
# 市区町村コードを文字列化
df_suicide["市区町村コード"] = df_suicide["市区町村コード"].astype(str)
# 市区町村コード末尾削除
df_suicide["市区町村コード"] = df_suicide["市区町村コード"].apply(lambda x:x[:-3])
# NaNの行を削除
df_suicide.dropna(inplace=True)
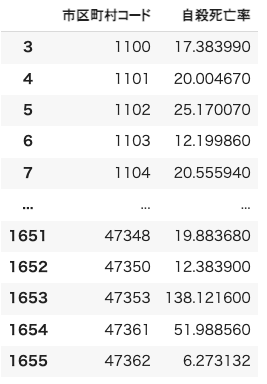
df_suicide自殺率のデータフレームが完成しました。
※)「自殺死亡率」とは、人口10万人当たりの自殺者数の割合を表す。
相関調査
ここまで全国の市区町村の緑地率のデータフレーム(df_gsr)、平均寿命のデータフレーム(df_lifespan)、自殺率のデータフレーム(df_suicide)を作成しました。これらをマージして、相関を調査します。
まずそれぞれのデータフレームのカラムの型を統一して、市区町村コードをキーとしてデータフレームをマージします。
# カラムタイプを統一
df_gsr["code"] = df_gsr["code"].astype(int)
df_lifespan = df_lifespan.astype(float)
df_lifespan["地域 コード"] = df_lifespan["地域 コード"].astype(int)
df_suicide["市区町村コード"] = df_suicide["市区町村コード"].astype(int)
df_lifespan.rename(columns={'I1101_平均余命(0歳)(男)【年】': 'lifespan_man', 'I1102_平均余命(0歳)(女)【年】': 'lifespan_woman'}, inplace=True)
df_suicide.rename(columns={'自殺死亡率': 'suicide_ratio'}, inplace=True)
# 表の結合(ndvi-lifespan)
df_merge = pd.merge(df_gsr, df_lifespan, left_on='code', right_on='地域 コード', how='inner').drop(columns=['muni', "地域 コード"])
# 表の結合(ndvi&lifespan-suicide)
df_merge = pd.merge(df_merge, df_suicide, left_on='code', right_on='市区町村コード', how='inner').drop(columns=["市区町村コード", "code"])
df_merge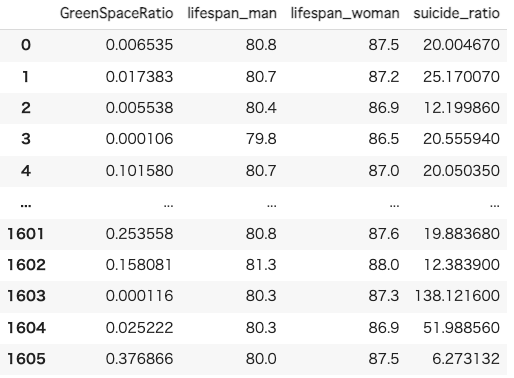
相関係数を算出します。
# 相関マトリクス
df_merge.corr()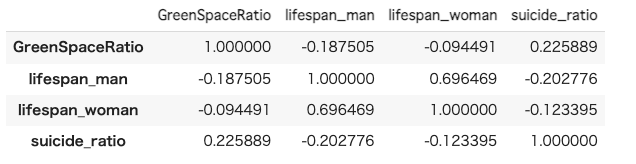
緑地率との相関係数の値を見てみると、平均余命、自殺死亡率ともに相関係数は0に近い値となっており、相関がないことがわかります。
緑地率と平均余命、自殺死亡率の散布図を表示してみます。
fig, ax = plt.subplots(3, 1, figsize=(8, 12))
df_merge.plot.scatter(x='GreenSpaceRatio', y='lifespan_man', ax=ax[0])
df_merge.plot.scatter(x='GreenSpaceRatio', y='lifespan_woman', ax=ax[1])
df_merge.plot.scatter(x='GreenSpaceRatio', y='suicide_ratio', ax=ax[2])
fig.tight_layout()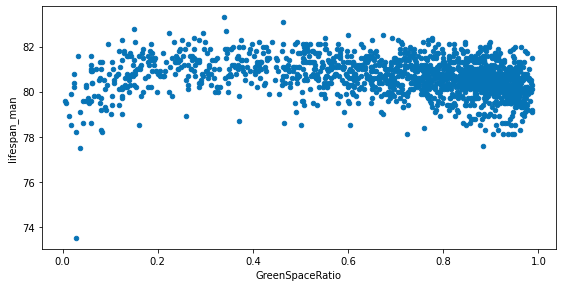
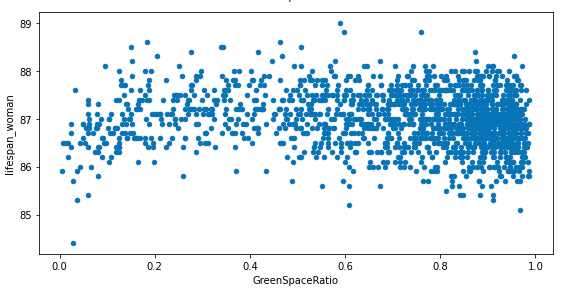
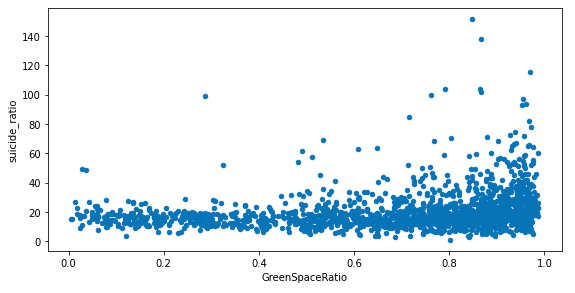
散布図をみてみると、緑地率が高いほど平均寿命が長い、自殺率が低いといったことはなさそうなことがわかります。また、平均余命、自殺率ともにある値の部分に集まっており、ばらつきがあまりないことがわかります。
散布図を表示してから気がつきましたが、そもそもどちらのデータも地域ごとに大きくばらつきがあるようなデータではなく、緑地率などのデータとの相関があるようなデータではなさそうです。
緑地率は、NDVI閾値の決定に用いた埼玉県では公開されている緑地率に近い値を算出できていましたが、全国の市区町村では実際の値に近い値を算出できているかはわかりません。この辺りは今後調査をして精度を高めていく必要がありそうです。
まとめ
Sentinel-2の光学画像を使ってNDVIを算出し、全国の市区町村の緑地率を求めました。
算出した緑地率と平均寿命、自殺率との相関を調査しました。緑地率が高いほうが平均寿命が長く、自殺率が低いだろうという仮説でしたが、そのような関係はなさそうでした。
ただし、緑地率については、今回の解析結果の精度が悪い可能性があります。衛星データを使って緑地率を求めることを試みている論文はたくさん公開されているので、興味がある方はぜひご一読ください。
例
https://www.jstage.jst.go.jp/article/aijt/28/68/28_521/_pdf
https://www.jstage.jst.go.jp/article/journalcpij/44.3/0/44.3_19/_pdf/-char/ja
今回の緑地率の算出では、幅広く衛星画像の扱い方について学ぶことができました。衛星データ解析を始めてみたいけど何をしたら良いかわからないという方は、今回紹介したNDVIを使った緑地率の算出から挑戦してみてください。
